Настройка и оптимизация производительности
Утилиты от сторонних поставщиков
В дополнение к набору средств Microsoft имеется ряд утилит планирования вычислительной мощности от сторонних поставщиков для Windows Server 2003. Некоторые из этих средств приведены в табл. 16.3.
Эти продукты обычно содержат средства для сбора, анализа, хранения и создания отчетов по статистической информации о системе аналогично оснастке Performance в Windows Server 2003. Большинство продуктов включают также такие улучшения, как расписание или графическое представление данных. В некоторые утилиты даже включены такие нововведения, как автоматизация многих аспектов оптимизации производительности. Например, в некоторых наиболее продвинутых программах, таких как PATROL, выполняется анализ временных трендов и включены модели поддержки решений, помогающие вам прогнозировать будущее использование системы.
| Имя утилиты | Компания | |
|---|---|---|
| HP OpenView | Hewlett Packard | Веб-сайт: www.openview.hp.com/ |
| Unicenter TNG | Computer Associates | Веб-сайт: www.cai.com/unicenter/ |
| PerfMan | Information Systems | Веб-сайт: www.infosysman.com/ |
| PATROL | BMC Software | Веб-сайт: www.bmc.com/products/ |
Большинство улучшений в этих продуктах от сторонних поставщиков (будь то расширенные возможности хранения или улучшения в графическом интерфейсе) превосходят по своим функциям оснастку Performance системы Windows Server 2003. Однако имеются как преимущества (например, анализ трендов, простота использования и отчетность), так и недостатки (стоимость и сложность) в использовании этих утилит вместо бесплатной встроенной утилиты Performance.
Мониторинг и оптимизация системных ресурсов
Вы можете осуществлять мониторинг многочисленных системных ресурсов в целях оптимизации производительности. На самом деле существует так много объектов и счетчиков, за которыми можно следить, что вы можете быстро собрать такой объем данных, с которым невозможно справиться. Если не применить тщательный подход к выбору объектов и счетчиков мониторинга, то вы можете собрать столько информации, что эти данные будут бесполезны. С большими объемами данных трудно работать, поэтому вы будете тратить почти все время на организацию данных вместо их анализа. Помните, что одной из ключевых концепций, лежащих в основе планирования вычислительной мощности, является рациональный подход. Формируйте мониторинг конфигурации сервера как можно аккуратнее.
Имеется небольшое число важных ресурсов, мониторинг которых обязателен для каждого сервера: память, процессор, дисковая подсистема и сетевая подсистема. Эти ресурсы составляют четверку наиболее распространенных источников узких мест в системе. Узкое место (bottleneck) - это наиболее медленный компонент вашей системы, и это может быть компонент оборудования или ПО. Узкие места ограничивают производительность системы, поскольку ваша система работает со скоростью самого медленного ресурса. Например, файловый сервер может быть оборудован гигабитным сетевым адаптером (картой сетевого интерфейса), но если дисковая подсистема устарела, то данный компьютер не сможет в полной мере использовать пропускную способность сети, которая предоставляется этим сетевым адаптером. Имеются также остаточные эффекты узких мест, такие как недостаточное использование ресурсов оборудования. Ресурсы могут недоиспользоваться из-за того, что система пытается компенсировать узкое место.
Кроме того, то, как сконфигурирован сервер Windows Server 2003, функционально влияет на ресурсы или службы, которые вам следует включать в мониторинг. Например, в наиболее распространенные конфигурации Windows Server 2003 включаются база данных, разделяемый доступ к файлам и принтерам, разделяемое использование приложений, функции контроллера домена и целый ряд других функций. Вам может потребоваться мониторинг влияния репликации и синхронизации на контроллеры домена, но не для файловых серверов и серверов печати. Важно следить за наиболее распространенными источниками узких мест системы, а также за источниками, которые относятся к определенной конфигурации сервера.
В этом разделе рассматриваются конкретные счетчики, за которыми вы должны следить для каждого из распространенных источников узких мест. Отметим, однако, что существует много других счетчиков, которые следует включать в мониторинг в дополнение к этим счетчикам. В этом разделе приводится базовый минимальный набор счетчиков, чтобы вы могли начать процесс мониторинга.
Мониторинг памяти
Из четырех наиболее распространенных источников узких мест память обычно является первым ресурсом, вызывающим снижение производительности. Дело в том, что Windows Server 2003 является настоящим "пожирателем" памяти. К счастью, добавление блоков памяти является также наиболее простым и экономичным способом увеличения производительности. На рис. 16.12 показано окно System Monitor для мониторинга счетчиков памяти в реальном масштабе времени.
Имеется много важных счетчиков, связанных с памятью. Однако имеется два счетчика, обязательных для мониторинга. Это Page Faults/sec (Отсутствие страниц/ сек) и Pages/sec (Страниц/сек). Они показывают, достаточно ли для данной системы установленного количества RAM-памяти.
Ситуация page fault (ошибка страницы) возникает, когда процессу требуется код или данные, которых нет в его рабочем наборе (working set). Рабочий набор - это количество выделенной памяти для процесса или приложения. В счетчик Page Faults/sec включаются как аппаратные ошибки (требующие дискового доступа), так и программные ошибки (когда отсутствующая страница находится где-либо в памяти). Большинство систем могут справляться с большим числом программных ошибок без влияния на производительность. Однако аппаратные ошибки могут вызывать существенные задержки из-за времени доступа к жесткому диску. Скорости поиска и передачи данных даже самого быстрого диска намного меньше, чем скорость доступа к памяти. Огромная задержка, связанная с аппаратными ошибками страниц, вынуждает вас немедленно сконфигурировать систему, как можно больше увеличив объем RAM-памяти.

Счетчик Pages/sec определяет количество страниц, прочитанных или записанных на диске для разрешения аппаратных ошибок страниц. Ситуация hard page fault (ошибка страницы на диске) возникает, когда процессу требуется код или данные, которых нет в его рабочем наборе или где-либо в памяти. Тогда этот код или данные должны быть считаны с диска. Этот счетчик является главным индикатором так называемой пробуксовки (thrashing), то есть слишком большого числа обращений к жесткому диску для использования виртуальной памяти, а также излишнего обмена страниц. Microsoft утверждает, что если значение счетчика Pages/sec постоянно выше 5, это может означать, у вашей системы недостаточно памяти. Если это значение постоянно превышает 20, то вы начнете ощущать снижение производительности из-за недостаточной памяти.
Мониторинг процессора
Процессор часто является первым анализируемым ресурсом, когда наблюдается ощутимое снижение производительности. Имеется два важных счетчика по процессору, используемых для оптимизации производительности: % Processor Time (Процент использования процессора) и Interrupts/sec (Прерываний/сек). Счетчик % Processor Time показывает процент использования процессора в целом по системе. Если на компьютере больше одного процессора, то имеются отдельные экземпляры для каждого из них, а также счетчик суммарного значения. Если значение счетчика % Processor Time превышает 50 процентов в течение длительных периодов времени, то вам следует предусмотреть модернизацию. Если среднее значение постоянно превышает 65 процентов, то пользователи могут ощущать неприемлемое снижение производительности.
Счетчик Interrupts/sec также является хорошим индикатором использования процессора. Он указывает количество прерываний устройств в секунду, обрабатываемых процессором. Прерывание устройств может вызываться оборудованием или программным обеспечением, и это значение может достигать нескольких тысяч. Для повышения производительности перекладывают нагрузку некоторых служб на другой, менее загруженный сервер, добавляют еще один процессор, модернизируют имеющийся процессор, прибегают к кластеризации и распределению нагрузки на совершенно новую машину.
Мониторинг дисковой подсистемы
Дисковая подсистема состоит из двух основных типов ресурсов: накопители на жестких дисках и контроллеры жестких дисков. Оснастка Performance не имеет объекта, непосредственно связанного с контроллером жесткого диска, поскольку значения объектов Physical Disk и Logical Disk точно представляют производительность дисковой подсистемы.
В настоящее время любой компонент компьютера превосходит то, что было раньше, и это также относится к компонентам дисковой подсистемы. В результате влияние объектов производительности дисковой подсистемы становится все более несущественным и, в зависимости от конфигурации вашей системы, даже незаметным.
Windows Server 2003 позволяет вам гибко запускать и прекращать работу объектов дисковой подсистемы. Вы можете использовать diskperf -y, чтобы запускать дисковые счетчики, diskperf -y \\mycomputer, чтобы запускать их на удаленных машинах, или diskperf -n, чтобы отключать их, как это делали до Windows Server 2003. Гибкость проявляется в том, что вы можете активизировать объекты Logical Disk и Physical Disk по отдельности. Чтобы задать объект, который вы хотите активизировать или деактивизировать, включите букву d в параметры для объекта Physical Disk или букву v для объекта Logical Disk. Например, чтобы начать просмотр статистики по счетчику Logical Disk, вы должны повторно активизировать объект производительности Logical Disk с помощью команды diskperf -yv.
Самыми лучшими, но, конечно не единственными счетчиками производительности дисков в целях оптимизации производительности являются % Disk Time (Процент времени активности диска) и Avg. Disk Queue Length (Среднее значение длины очереди). Счетчик % Disk Time следит за количеством времени, которое тратится выбранным физическим или логическим диском на запросы чтения и записи. Счетчик Avg. Disk Queue Length указывает количество ожидающих (еще не обслуженных) запросов на физическом или логическом диске. Это мгновенное значение, а не среднее значение за определенный период, но оно все же точно представляет количество задержек на данном диске. Задержки запросов на диске можно рассчитать путем вычитания количества шпинделей дисковода из результата измерения Avg. Disk Queue Length. Если величина задержки часто превышает 2, значит, диски вызывают снижение производительности.
Мониторинг сетевой производительности
Из-за большого числа компонентов сетевая подсистема наиболее сложна для мониторинга узких мест. Протоколы, сетевые адаптеры, сетевые приложения и физические топологии - все это оказывает существенное влияние на вашу сеть. Ситуация еще больше осложняется тем, что в вашем окружении могут быть реализованы несколько стеков протоколов. Поэтому набор счетчиков сетевой производительности, за которыми вы должны следить, варьируется в зависимости от конфигурации вашей системы.
Важной информацией, собираемой от компонентов мониторинга сетевой подсистемы, является уровень сетевой активности и пропускная способность. При мониторинге компонентов сетевой подсистемы вам следует использовать и другие средства мониторинга сети в дополнение к оснастке Performance. Например, можно использовать Network Monitor (встроенную версию или SMS-версию) или приложение управления системами, такое как MOM. Совместное использование этих средств расширяет охват мониторинга и дает более точное представление того, что происходит в вашей сетевой инфраструктуре.
Вопросы оптимизации производительности для сетевой подсистемы фокусируются на TCP/IP. Нельзя просто говорить о том, что работа Windows Server 2003 существенно зависит от этого протокола. После установки этого протокола добавляются счетчики для TCP/IP, включая счетчики для Internet Protocol version 6 (IPv6).
Имеется много важных счетчиков в объектах, относящихся к TCP/IP, которые вам следует включать в мониторинг. Два важных счетчика, используемых для мониторинга TCP/IP, относятся к объекту NIC (Сетевой адаптер). Это счетчики Bytes Total/sec (Всего байтов/сек) и Output Queue Length (Длина выходной очереди). Счетчик Bytes Total/sec указывает объем входящего и исходящего трафика TCP/IP на вашем сервере. Счетчик Output Queue Length указывает, имеются ли проблемы перегрузки или конфликтной ситуации на вашем сетевом адаптере. Если значение Output Queue Length постоянно превышает 2, то проверьте значение счетчика Bytes Total/sec. Высокие значения обоих счетчиков могут означать, что в вашей сетевой подсистеме имеется узкое место и, может быть, пришло время, когда требуется модернизация компонентов вашей сетевой подсистемы.
Имеется много других счетчиков, за которыми требуется следить, чтобы точно определить причину слишком высоких значений этих счетчиков или снижения производительности сети. Например, чем вызваны слишком высокие значения счетчиков Bytes Total/sec and Output Queue Length - временным всплеском сетевой активности или слишком большой частотой конфликтов (collision rate)? Если collision rate больше 10 процентов, то проблемой может быть производительность сети в целом, а не только рассматриваемый сервер Windows Server 2003.
Контроль над системными ресурсами
На протяжении этой лекции мы анализировали различные способы мониторинга и использования данных производительности системы. Хотя мониторинг или анализ данных производительности необходим для более точной настройки производительности системы, он не дает непосредственного контроля над ресурсами, за которыми вы следите. Компания Microsoft разработала оснастку MMC Windows System Resource Monitor (WSRM), чтобы обеспечивать определенный уровень контроля в современных системах.
Windows System Resource Monitor
Оснастка WSRM (см. рис. 16.13) - это утилита, которую можно использовать с версиями Windows Server 2003 Enterprise Edition или Datacenter Edition. Она дает вам дополнительный контроль над системными ресурсами и процессами. Вы можете использовать WSRM для контроля приложений, служб и использования ресурсов процессов (например, использования процессора, памяти и родственности процессоров).
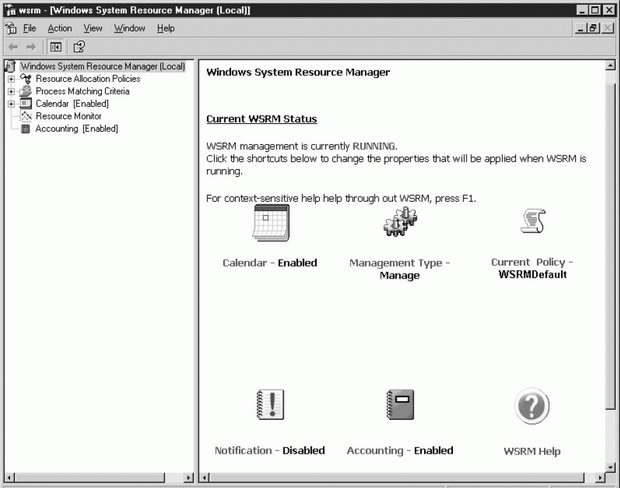
Чтобы контролировать или защищать системные ресурсы и использование, задаются предельные значения для приложений, служб или процессов с помощью политик. Эти политики можно настраивать, чтобы вы могли применять различные стандарты к различным системам. Кроме ограничений по использованию, вы можете также учитывать факторы расписания. Например, вы можете ограничить определенное приложение использованием только 25% времени процессора в часы пиковой нагрузки рабочего дня. WSRM управляет своим собственным расписанием с помощью встроенной календарной функции.
Оснастка WSRM особенно полезна для систем, исполняющих несколько функциональных ролей (когда-то вы могли устанавливать и конфигурировать на одном компьютере только один тип рабочей нагрузки или роли). Различные функции могут конкурировать за получение системных ресурсов, необходимых для выполнения текущих задач. Если приложение, служба или процесс, связанные с определенной ролью сервера, чувствительны к потреблению системных ресурсов, то здесь может вмешаться WSRM, чтобы не допускать превышения границ, которые заданы в политиках.