




|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Инспектор
Вы можете этот курс.
Опубликован: 05.01.2015 | Уровень: для всех | Доступ: платный
Лекция 10:
Поразрядная сортировка
Поразрядная MSD-сортировка
Использование в поразрядной быстрой сортировке лишь одного разряда соответствует тому, что ключи считаются числами в двоичной системе счисления, и сначала рассматриваются наиболее значащие цифры. Обобщая этот подход, предположим, что нам нужно отсортировать числа, представленные в системе счисления по основанию R, рассматривая сначала наиболее значащие байты. Это требует разбиения массива не на 2, а на R различных частей. Традиционно эти части называются контейнерами, и мы будем представлять себе, что алгоритм работает с группой из R контейнеров, по одному для каждого возможного значения первой цифры, как показано на следующей диаграмме:
Мы последовательно просматриваем ключи, распределяя их по корзинам, затем рекурсивно сортируем содержимое каждого контейнера по ключам, которые короче на 1 байт.
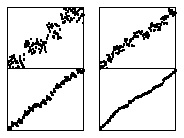
На рис. 10.6 показан пример работы MSD-сортировки на случайных перестановках целых чисел. В отличие от бинарной быстрой сортировки, этот алгоритм может почти упорядочить файл достаточно быстро, даже после первого разбиения, если основание системы счисления достаточно велико.
Как видно на данном примере случайно упорядоченного файла 8-разрядных целых чисел, всего лишь один шаг MSD-сортировки почти полностью упорядочивает данные. Первый шаг MSD-сортировки по двум старшим разрядам (слева) делит исходный файл на четыре подфай-ла. На следующем шаге каждый такой подфайл также делится на четыре подфайла. MSD-сортировка по трем старшим разрядам (справа) всего лишь за один проход распределяющего подсчета делит файл на восемь подфайлов. На следующем уровне каждый из этих подфайлов снова разбивается на восемь частей, после чего в каждой такой части содержится всего лишь несколько элементов.
Как было сказано в разделе 10.2, одной из наиболее привлекательных особенностей поразрядной сортировки является интуитивный и прямолинейный характер ее адаптации к приложениям сортировки, в которых ключами являются символьные строки. Это особенно ярко проявляется в С++ и других средах программирования с прямой поддержкой обработки строк. Для MSD-сортировки просто используется основание системы счисления, соответствующее размеру байта. Чтобы извлечь цифру, достаточно загрузить байт, а для перехода к следующей цифре нужно увеличить на единицу указатель строки. Пока мы рассматриваем ключи фиксированной длины, а чуть позже увидим, что эти же базовые механизмы позволяют работать и с ключами в виде строк переменной длины.
На рис. 10.7 показан пример MSD-сортировки трехбуквенных слов. Для простоты в нем основание системы счисления равно 26, хотя в большинстве приложений мы скорее выберем для этого большее значение основания, соответствующее стандартной кодировке символов.
Все слова распределяются по 26 контейнерам соответственно первой букве. Затем тем же методом сортируется содержимое каждого контейнера, начиная со второй буквы.
Сначала слова разбиваются таким образом, что те из них, которые начинаются с буквы а, расположены раньше слов, начинающихся с буквы b, и т.д. Затем слова, начинающиеся с буквы а, в свою очередь рекурсивно сортируются, далее сортируются слова, начинающиеся с буквы b, и т.д.
Как видно из примера, большая часть работы, связанной с сортировкой, приходится на разбиение по первой букве, а подфайлы, полученные после первого разбиения, имеют небольшие размеры.
Как мы уже убедились на примере быстрой сортировки в "Быстрая сортировка" и разделе 10.2, а также сортировки слиянием в "Слияние и сортировка слиянием" , производительность большинства рекурсивных программ можно повысить, используя для сортировки небольших файлов простой алгоритм. Использование другого метода для сортировки небольших файлов (контейнеров с небольшим количеством элементов) в поразрядной сортировке имеет большое значение, ведь их так много!
Более того, этот алгоритм можно настраивать, выбирая различные значения R, поскольку существует простая зависимость: если R слишком велико, то больше всего затрат приходится на инициализацию и проверку контейнеров; если же R слишком мало, то метод не использует своих потенциальных выгод, достигаемых при разбиении файла на максимально возможное число фрагментов. Мы вернемся к этим вопросам в конце этого раздела и в разделе 10.6.
Для реализации MSD-сортировки необходимо обобщить методы разбиения массива, рассмотренные в разделе 10.7 при изучении реализаций быстрой сортировки. Эти методы, основанные на движении индексов с противоположных концов массива навстречу друг другу до встречи где-то в середине, хорошо работают при разбиении на два или три раздела, но не допускают непосредственного обобщения.
К счастью, для наших целей великолепно подходит метод распределяющего подсчета, который был рассмотрен в "Элементарные методы сортировки" для сортировки файлов с ключами, принимающих значения в узком диапазоне. При этом используются таблица счетчиков и вспомогательный массив; и на первом проходе по массиву подсчитывается, сколько раз встретилось каждое значение самой значащей цифры. Эти счетчики показывают, где окажутся точки разбиения. Затем, на втором проходе по массиву, счетчики используются для перемещения элементов в соответствующие позиции вспомогательного массива.
Этот процесс реализован в программе 10.2. Ее рекурсивная структура обобщает структуру быстрой сортировки, так что все вопросы, рассмотренные в разделе 7.3 "Быстрая сортировка" , необходимо рассмотреть и здесь. Нужно ли обрабатывать больший из подфайлов последним, во избежание излишней глубины рекурсии? Скорее всего, нет, поскольку глубина рекурсии ограничена длиной ключей. Нужно ли применять для сортировки небольших подфайлов простые методы, вроде сортировки вставками? Конечно, поскольку таких подфайлов будет очень много.
Программа 10.2. Поразрядная MSD-сортировка
Эта программа написана на основе программы 8.17 (сортировка распределяющим подсчетом) путем замены ссылок на ключи ссылками на цифры ключей и добавления в конце цикла, выполняющего рекурсивные вызовы для каждого под-файла ключей, начинающихся с одной и той же цифры. Для ключей переменной длины, оканчивающихся нулевым байтом (т.е. строк в стиле С) первый оператор if и первый рекурсивный вызов не нужны. В этой реализации используется вспомогательный массив (aux) достаточного размера, чтобы хранить копию входного файла.
#define bin(A) l+count[A]
template <class Item>
void radixMSD(Item a[], int l, int r, int d)
{ int i, j, count[R+1];
static Item aux[maxN];
if (d > bytesword) return;
if (r-l <= M) { insertion(a, l, r); return; }
for (j = 0; j < R; j++) count[j] = 0;
for (i = l; i <= r; i++)
count[digit(a[i], d) + 1]+ + ;
for (j = 1; j < R; j++)
count[j] += count[j-1];
for (i = l; i <= r; i++)
aux[l+count[digit(a[i], d)]++] = a[i];
for (i = l; i <= r; i++) a[i] = aux[i];
radixMSD(a, l, bin(0)-1, d+1);
for (j = 0; j < R-1; j++)
radixMSD(a, bin(j), bin(j + 1)-1, d+1);
}
Для выполнения разбиения в программе 10.2 используется вспомогательный массив, размер которого равен размеру сортируемого файла. В качестве альтернативы можно воспользоваться обменным методом распределяющего подсчета (см. упражнения 10.17 и 10.18). Особенно большое внимание следует уделить использованию памяти, поскольку рекурсивные обращения могут расходовать очень много памяти для размещения локальных переменных. В программе 10.2 временный буфер для перемещения ключей (aux) может быть глобальным, но массив, в котором хранятся счетчики и позиции точек разбиения (count) должен быть локальным.
Использование дополнительной памяти для вспомогательного массива — не самый серьезный вопрос во многих приложениях, использующих поразрядную сортировку для длинных ключей или записей, поскольку для работы с такими данными обычно применяются указатели. Поэтому дополнительная память нужна только для переупорядочения указателей, и ее объем мал по сравнению с памятью, отведенной под сами ключи и записи (хотя все-таки заметен). Если памяти достаточно, и важно в первую очередь быстродействие (обычная ситуация при использовании поразрядной сортировки), можно также сэкономить время на копирование массива с помощью рекурсивных переключений направления просмотра, как это было сделано для сортировки слиянием в разделе 8.4 "Слияние и сортировка слиянием" .

Рис. 10.8. Пример поразрядной MSD-сортировки (с пустыми контейнерами) Уже на втором этапе сортировки небольших файлов получается множество пустых корзин
При сортировке случайных ключей количество ключей в каждом контейнере (размер подфайлов) после первого прохода в среднем будет равно N/R. На практике ключи могут не быть случайными (например, если ключи — это строки, представляющие собой слова на русском языке, то мы знаем, что лишь немногие из них начинаются с буквы й и совсем нет слов, начинающихся с буквы ъ), так что многие контейнеры окажутся пустыми, а некоторые из непустых контейнеров будут содержать больше ключей, чем остальные (см. рис. 10.8). Несмотря на этот эффект, процесс многопутевого разбиения в общем случае будет эффективно разбивать большие сортируемые файлы на множество меньших под-файлов.
Другой естественный путь реализации MSD-сортировки — использование связных списков. Каждый контейнер представляется отдельным связным списком: на первом проходе по сортируемым элементам каждый элемент вставляется в соответствующий связный список, определяемый старшей цифрой. Далее подсписки сортируются, после чего объединяются в единое отсортированное целое. Такой подход представляет собой достаточно трудную задачу программирования (см. упражнение 10.36). Объединение связных списков требует отслеживания начала и конца каждого из этих списков, и, естественно, специальной обработки пустых списков, которых, очевидно, будет много.
Чтобы добиться высокой производительности поразрядной сортировки в каком-либо приложении, нужно ограничить число пустых контейнеров с помощью выбора соответствующего значения как основания системы счисления, так и размера отсекаемых небольших подфайлов. В качестве конкретного примера предположим, что требуется отсортировать 224 (около шестнадцати миллионов) 64-разрядных целых чисел. Чтобы использовать таблицу счетчиков, меньшую по размеру, чем размер файла, можно выбрать основание R = 216, соответствующее проверке 16 разрядов ключа. Но после первого разбиения средний размер файла составит всего лишь 228, а основание системы счисления 216 слишком велико для таких небольших файлов. Что еще хуже, таких файлов может быть очень много: в рассматриваемом случае порядка 216. Для каждого из этих 216 файлов процедура сортировки обнуляет 216 счетчиков, затем проверяет, какие из них не равны нулю и так далее — выполняя по меньшей мере 232 арифметических операций. Программа 10.2, реализованная в предположении, что большая часть контейнеров не пуста, выполняет достаточно большое число арифметических операций для каждого пустого контейнера (например, она выполняет рекурсивные вызовы для всех пустых контейнеров), так что для рассматриваемого примера время выполнения окажется очень большим. Более подходящим основанием для второго уровня может быть 28 или 24. Короче говоря, для MSD-сортировки небольших файлов не стоит использовать большие основания систем счисления. Этот вопрос будет подробно рассмотрен в разделе 10.6, при изучении производительности различных методов.
Если положить R = 256 и отказаться от рекурсивного вызова для контейнера 0, то программа 10.2 становится эффективным методом сортировки строк в стиле С. Если также известно, что длина всех строк не превышает некоторой фиксированной величины, то можно ввести специальную переменную bytesword для хранения этой величины, либо отказаться от сравнения с bytesword и выполнять сортировку обычных символьных строк переменной длины. Для сортировки строк мы обычно будем реализовывать абстрактную операцию digit в виде единственной ссылки на массив, как описано в разделе 10.1. С помощью подбора значений R и bytesword (и их проверки) программу 10.2 можно легко модифицировать для работы со строками символов из нестандартных алфавитов, со строками нестандартных форматов, с учетом ограничений по длине или других вариантов.
Сортировка строк еще раз показывает важность правильной обработки пустых контейнеров. На рис. 10.8 показан процесс разбиения для примера наподобие рис. 10.7 рис. 10.7, но для слов из двух букв и с явно показанными пустыми контейнерами. В этом примере с помощью поразрядной сортировки по основанию 26 сортируются двухбуквенные слова, поэтому на каждой стадии сортировки имеется 26 контейнеров. На первом этапе число пустых контейнеров невелико, однако на втором этапе пустые контейнеры преобладают.
Функция MSD-сортировки выполняет разбиение файла по первой цифре ключей, затем рекурсивно вызывает себя для обработки подфайлов, соответствующих каждому значению. На рис. 10.9 рис. 10.9 представлена структура рекурсивных вызовов MSD-сортировки для примера, показанного на рис. 10.8. Структура вызовов соответствует многопутевому trie-дереву — прямому обобщению структуры trie-дерева для бинарной быстрой сортировки, показанной на рис. 10.4. Каждый узел соответствует рекурсивному вызову MSD-сортировки некоторого подфайла. Например, поддерево корня с буквой o в корне соответствует сортировке подфайла из трех ключей: of, on и or.
Из этих рисунков легко видеть, что в процессе MSD-сортировки строк появляется значительное число пустых контейнеров. В разделе 10.4 мы рассмотрим способ решения этой проблемы, а в главе 15 "Поразрядный поиск" изучим явное использование trie-структур в приложениях, применяющих обработку строк. В общем случае мы будем работать с компактными представлениями trie-структур, которые не содержат узлов, соответствующих пустым контейнерам, и в которых метки перенесены с ребер на их нижние узлы (как на рис. 10.10) — т.е. со структурой, соответствующей структуре рекурсивных вызовов (с игнорированием пустых контейнеров) на рис. 10.7, где показан пример MSD-сортировки трехбуквенных ключей. Например, поддерево корня с буквой j в корне соответствует сортировке контейнера, содержащего четыре ключа: jam, jay, jot и joy. Подробно свойства таких trie-деревьев будут рассмотрены в "Поразрядный поиск" .
Основная трудность в достижении на практике максимальной эффективности MSD-сортировки ключей, представляющих собой длинные строки, состоит в недостаточной случайности сортируемых данных. Часто эти ключи содержат длинные последовательности одинаковых или ненужных элементов, либо их части находятся в узком диапазоне. Например, приложение, обрабатывающее записи с данными о студентах, может иметь дело с ключами, поля которых содержат год выпуска (четыре байта, но только одно из четырех значений), название штата (максимум 10 байтов, но только одно из 50 возможных значений) и пол (1 байт с одним из двух возможных значений), а также поле фамилии студента (это больше похоже на случайную строку, но оно не обязательно короткое, буквы не распределены равномерно и, если длина фиксирована, то в конце может быть много пробелов). Все эти ограничения приводят к образованию в процессе MSD-сортировки большого количества пустых контейнеров (см. упражнение 10.23).
Это дерево соответствует выполнению рекурсивной MSD-сортировки из программы 10.2 для примера упорядочения двухбуквенных ключей методом MSD-сортировки, представленного на рис. 10.8. Если размер файла равен 0 или 1, рекурсивные вызовы не выполняются. В остальных случаях выполняются 26 вызовов, по одному на каждое возможное значение текущего байта.
Данное представление рекурсивной структуры MSD-сортировки более компактно, чем представление на рис. 10.9. Каждый узел этого дерева помечен значением (i — 1)-ой цифры соответствующего ключа, где i — расстояние от узла до корня. Каждый путь от корня до нижнего уровня дерева соответствует какому-либо ключу, который получается слитной записью меток узлов. Данное дерево соответствует представленному на 10.7примеру MSD-сортировки трехбуквенных ключей.
Один из практических способов решения этой проблемы заключается в разработке более сложной реализации абстрактной операции доступа к байтам, которая учитывает любые специальные сведения о сортируемых строках. Другой метод, который достаточно просто реализуется и называется эвристикой распределения контейнеров (bin-span heuristics), заключается в отслеживании на стадии подсчета начального и конечного значений диапазона значений непустых контейнеров, и использовании в дальнейшем только контейнеров, попадающих в этот диапазон (возможно, включая некоторые специальные случаи, вроде нулевых или пробельных ключей). Такое усовершенствование удобно для ситуаций, описанных в предыдущем абзаце. Например, в случае алфавитноцифровых данных с основанием системы счисления 256 можно работать в одном разделе с числовыми ключами и получить лишь 10 непустых контейнеров, соответствующих цифрам, а в другом разделе — с заглавными английскими буквами и получить 26 непустых контейнеров, соответствующих этим буквам.
Эвристику распределения контейнеров можно совершенствовать разными способами (см. раздел ссылок). Например, можно использовать дополнительную структуру данных для определения непустых контейнеров, и потом хранить счетчики и выполнять рекурсивные вызовы только для них. Однако все это (и даже применения эвристики распределения контейнеров), скорее всего, не нужно, поскольку экономия получается незначительной, кроме случаев, когда основание системы счисления очень велико или если файл очень короткий — но в этом случае следует уменьшить основание либо сортировать файл другим способом. Такой же экономии, как и за счет выбора соответствующего основания или переключения на другой метод для небольших файлов, можно достичь более специальными способами, хотя, возможно, и не так легко. В разделе 10.4 будет рассмотрен еще один вариант быстрой сортировки, элегантно решающий проблему пустых контейнеров.
Упражнения
10.14. Начертите компактную trie-структуру (без пустых контейнеров и с ключами в узлах, как на рис. 10.10), соответствующую рис. 10.9.
10.15. Сколько узлов содержит полное trie-дерево, соответствующее рис. 10.10?
10.16. Покажите, как выполняется разбиение MSD-сортировкой набора ключей now is the time for all good people to come the aid of their party.
10.17. Напишите программу, которая выполняет четырехпутевое обменное разбиение путем подсчета частоты повторения каждого ключа, как при распределяющей сортировке, с последующим использованием для перемещения ключей метода, подобного реализованному в программе 6.14.
10.18. Напишите программу, которая решает задачу обобщенного R-путевого разбиения с помощью метода, описанного в общих чертах в упражнении 10.17.
10.19. Напишите программу, которая генерирует случайные 80-байтовые ключи, а потом сортирует их методом поразрядной MSD-сортировки для N = 103, 104, 105 и 106 . Добавьте возможность вывода общего количества байтов, проверенных в процессе каждой сортировки.
10.20. Чему равно ожидаемое крайнее правое положение байта ключа, к которому обратится программа из упражнения 10.19 для каждого заданного значения N? Если вы сделали упражнение 10.19, вставьте в программу вывод этого значения и сравните результаты теоретических расчетов с результатами, полученными опытным путем.
10.21. Напишите генератор ключей, который порождает ключи путем перетасовки случайной 80-байтной последовательности. Воспользуйтесь полученной реализацией для генерации N случайных ключей, затем упорядочьте их методом MSD-сортировки для N = 103, 104, 105 и 106 . Сравните полученную производительность с аналогичным результатом для действительно случайных ключей (см. упражнение 10.19).
10.22. Чему равно ожидаемое крайнее правое положение байта ключа, к которому обратится программа из упражнения 10.21 для каждого значения N? Если вы сделали упражнение 10.21, сравните результаты теоретических расчетов с результатами, полученными опытным путем.
10.23. Напишите генератор ключей, который порождает случайные 30-байтовые строки, состоящие из четырех полей: 4-байтовое поле, содержащее одну из 10 заданных строк; 10-байтовое поле, содержащее одну из 50 заданных строк; 1-байтовое поле, содержащее одно из двух возможных значений; и 15-байтовое поле, содержащее случайную выровненную влево строку длиной от 4 до 15 символов (с равной вероятностью). Воспользуйтесь полученной реализацией для генерации N случайных ключей, а затем упорядочьте их методом MSD-сортировки для N = 103, 104, 105 и 106 . Добавьте в генератор возможность вывода общего количества проверенных байтов ключей. Сравните достигнутую производительность с аналогичным результатом для действительно случайных ключей (см. упражнение 10.19).
10.24. Реализуйте в программе 10.2 эвристику распределения контейнеров. Проверьте работу программы на данных из упражнения 10.23.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |