
| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 25.12.2006 | Уровень: специалист | Доступ: платный
Лекция 4:
Обучение без учителя: Сжатие информации
Соревнование нейронов: кластеризация
В начале данной лекции мы упомянули два главных способа уменьшения избыточности: снижение размерности данных и уменьшение их разнообразия при той же размерности. До сих пор речь шла о первом способе. Обратимся теперь к второму. Этот способ подразумевает другие правила обучения нейронов.
Победитель забирает все
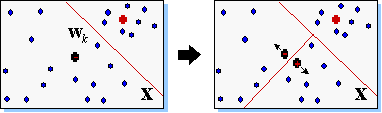
В Хеббовском и производных от него алгоритмах обучения активность выходных нейронов стремится быть по возможности более независимой друг от друга. Напротив, в соревновательном обучении, к рассмотрению которого мы приступаем, выходы сети максимально скоррелированы: при любом значении входа активность всех нейронов, кроме т.н. нейрона-победителя одинакова и равна нулю. Такой режим функционирования сети называется победитель забирает все.
Нейрон-победитель (с индексом 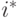 ), свой для каждого входного вектора, будет служить прототипом этого вектора. Поэтому победитель
выбирается так, что его вектор весов
), свой для каждого входного вектора, будет служить прототипом этого вектора. Поэтому победитель
выбирается так, что его вектор весов 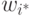 , определенный в том же d-мерном пространстве, находится ближе к данному входному вектору , чем
у всех остальных нейронов:
, определенный в том же d-мерном пространстве, находится ближе к данному входному вектору , чем
у всех остальных нейронов:  для всех i. Если, как это обычно и делается (вспомним слой Ойа), применять правила обучения нейронов,
обеспечивающие одинаковую нормировку всех весов, например,
для всех i. Если, как это обычно и делается (вспомним слой Ойа), применять правила обучения нейронов,
обеспечивающие одинаковую нормировку всех весов, например,  , то победителем окажется нейрон, дающий наибольший отклик на данный входной
стимул:
, то победителем окажется нейрон, дающий наибольший отклик на данный входной
стимул: 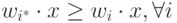 . Выход такого нейрона усиливается до единичного, а остальных - подавляется до нуля.
. Выход такого нейрона усиливается до единичного, а остальных - подавляется до нуля.
Количество нейронов в соревновательном слое определяет максимальное разнообразие выходов и выбирается в соответствии с требуемой степенью детализации входной информации. Обученная сеть может затем классифицировать входы: нейрон-победитель определяет к какому классу относится данный входной вектор.
В отличие от обучения с учителем, самообучение не предполагает априорного задания структуры классов. Входные векторы должны быть разбиты по категориям (кластерам) согласуясь с внутренними закономерностями самих данных. В этом и состоит задача обучения соревновательного слоя нейронов.
Алгоритм обучения соревновательного слоя нейронов
Базовый алгоритм обучения соревновательного слоя остается неизменым:
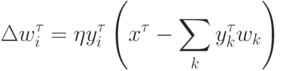
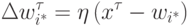
Описанный выше базовый алгоритм обучения на практике обычно несколько модифицируют, т. к. он, например, допускает существование т. н. мертвых нейронов, которые никогда не выигрывают, и, следовательно, бесполезны. Самый простой способ избежать их появления - выбирать в качестве начальных значений весов случайно выбранные в обучающей выборке входные вектора.
Такой способ хорош еще и тем, что при достаточно большом числе прототипов он способствует равной "нагрузке" всех нейронов-прототипов. Это соответствует максимизации энтропии выходов в случае соревновательного слоя. В идеале каждый из нейронов соревновательного слоя должен одинаково часто становились победителем, чтобы априори невозможно было бы предсказать какой из них победит при случайном выборе входного вектора из обучающей выборки.
Наиболее быструю сходимость обеспечивает пакетный (batch) режим обучения, когда веса изменяются лишь после предъявления всех примеров. В этом случае можно сделать приращения не малыми, помещая вес нейрона на следующем шаге сразу в центр тяжести всех входных векторов, относящихся к его ячейке. Такой алгоритм сходится за O(1) итераций.
Кластеризация и квантование
Записав правило соревновательного обучения в градиентном виде:  , легко убедиться, что оно минимизирует квадратичное отклонение
входных векторов от их прототипов - весов нейронов-победителей:
, легко убедиться, что оно минимизирует квадратичное отклонение
входных векторов от их прототипов - весов нейронов-победителей:
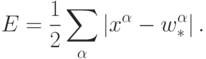
Иными словами, сеть осуществляет кластеризацию данных: находит такие усредненные прототипы, которые минимизируют ошибку огрубления данных. Недостаток такого варианта кластеризации очевиден - "навязывание" количества кластеров, равного числу нейронов. В идеале сеть сама должна находить число кластеров, соответствующее реальной кластеризации векторов в обучающей выборке. Адаптивный подбор числа нейронов осуществляют несколько более сложные алгоритмы, такие, например, как растущий нейронный газ.
Идея последнего подхода состоит в последовательном увеличении числа нейронов-прототипов путем их "деления". Общую ошибку сети можно записать как сумму индивидуальных ошибок каждого нейрона:
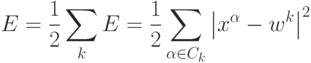
Естественно предположить, что наибольшую ошибку будут иметь нейроны, окруженные слишком большим числом примеров и/или имеющие слишком большую ячейку. Такие нейроны и являются, в первую очередь, кандидатами на "почкование" (см. рисунок 4.10).
Соревновательные слои нейронов широко используются для квантования данных (vector quantization), отличающегося от кластеризации лишь большим числом прототипов. Это весьма распространенный на практике метод сжатия данных. При достаточно большом числе прототипов, плотность распределения весов соревновательного слоя хорошо аппроксимирует реальную плотность распределения многомерных входных векторов. Входное пространство разбивается на ячейки, содержащие вектора, относящиеся к одному и тому же прототипу. Причем эти ячейки (называемые ячейками Дирихле или ячейками Вороного) содержат примерно одинаковое количество обучающих примеров. Тем самым одновременно минимизируется ошибка огрубления и максимизируется выходная информация - за счет равномерной загрузки нейронов.
Сжатие данных в этом случае достигается за счет того, что каждый прототип можно закодировать меньшим числом бит, чем
соответствующие ему вектора данных. При наличии прототипов для идентификации любого из них достаточно лишь  . бит, вместо bd бит
описывающих произвольный входной вектор.
. бит, вместо bd бит
описывающих произвольный входной вектор.