Предобработка данных
Нормировка и предобработка данных
Как входами, так и выходами нейросети могут быть совершенно разнородные величины. Очевидно, что результаты нейросетевого моделирования не должны зависеть от единиц измерения этих величин. А именно, чтобы сеть трактовала их значения единообразно, все входные и выходные величины должны быть приведены к единому - единичному - масштабу. Кроме того, для повышения скорости и качества обучения полезно провести дополнительную предобработку данных, выравнивающую распределение значений еще до этапа обучения.
Индивидуальная нормировка данных
Приведение данных к единичному масштабу обеспечивается нормировкой каждой переменной на диапазон разброса ее значений. В простейшем варианте это - линейное преобразование:
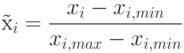
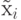 . Обобщение для отображения данных в интервал
. Обобщение для отображения данных в интервал ![[-1,1]](/sites/default/files/tex_cache/d060b17b29e0dae91a1cac23ea62281a.png) , рекомендуемого для входных данных тривиально.
, рекомендуемого для входных данных тривиально.Линейная нормировка оптимальна, когда значения переменной  плотно заполняют определенный интервал. Но подобный
"прямолинейный" подход применим далеко не всегда. Так, если в данных имеются относительно редкие выбросы, намного превышающие
типичный разброс, именно эти выбросы определят согласно предыдущей формуле масштаб нормировки. Это приведет к тому, что основная масса
значений нормированной переменной сосредоточится вблизи нуля:
плотно заполняют определенный интервал. Но подобный
"прямолинейный" подход применим далеко не всегда. Так, если в данных имеются относительно редкие выбросы, намного превышающие
типичный разброс, именно эти выбросы определят согласно предыдущей формуле масштаб нормировки. Это приведет к тому, что основная масса
значений нормированной переменной сосредоточится вблизи нуля:  .
.

Рис. 7.2. Гистограмма значений переменной при наличии редких, но больших по амплитуде отклонений от среднего
Гораздо надежнее, поэтому, ориентироваться при нормировке не на экстремальные значения, а на типичные, т.е. статистические характеристики данных, такие как среднее и дисперсия:



В этом случае основная масса данных будет иметь единичный масштаб, т.е. типичные значения всех переменных будут сравнимы (см. рисунок 7.2).
Однако, теперь нормированные величины не принадлежат гарантированно единичному интервалу, более того, максимальный разброс
значений  . заранее не известен. Для входных данных это может быть и не важно, но выходные переменные будут использоваться в качестве эталонов для выходных нейронов. В случае, если выходные нейроны - сигмоидные, они могут принимать значения лишь в единичном диапазоне. Чтобы установить соответствие между обучающей выборкой и нейросетью в этом случае необходимо ограничить диапазон изменения переменных.
. заранее не известен. Для входных данных это может быть и не важно, но выходные переменные будут использоваться в качестве эталонов для выходных нейронов. В случае, если выходные нейроны - сигмоидные, они могут принимать значения лишь в единичном диапазоне. Чтобы установить соответствие между обучающей выборкой и нейросетью в этом случае необходимо ограничить диапазон изменения переменных.
Линейное преобразование, как мы убедились, неспособно отнормировать основную массу данных и одновременно ограничить диапазон возможных значений этих данных. Естественный выход из этой ситуации - использовать для предобработки данных функцию активации тех же нейронов. Например, нелинейное преобразование


![\mbox{\~{x}_i}\in[0,1]](/sites/default/files/tex_cache/336231f1e682520764f1dd080ca8ee63.png) (см. рисунок 7.3).
(см. рисунок 7.3).

Как видно из приведенного выше рисунка, распределение значений после такого нелинейного преобразования гораздо ближе к равномерному.
До сих пор мы старались максимизировать энтропию каждого входа (выхода) по отдельности. Но, вообще говоря, можно добиться гораздо большего максимизируя их совместную энтропию. Рассмотрим эту технику на примере совместной нормировки входов, подразумевая, что с таким же успехом ее можно применять и для выходов а также для всей совокупности входов-выходов.
Совместная нормировка: выбеливание входов
Если два входа статистически независимы, то их совместная энтропия меньше суммы индивидуальных энтропий:  . Поэтому добившись
статистической независимости входов мы, тем самым, повысим информационную насыщенность входной информации. Это, однако, потребует
более сложной процедуры совместной нормировки входов.
. Поэтому добившись
статистической независимости входов мы, тем самым, повысим информационную насыщенность входной информации. Это, однако, потребует
более сложной процедуры совместной нормировки входов.
Вместо того, чтобы использовать для нормировки индивидуальные дисперсии, будем рассматривать входные данные в совокупности. Мы хотим найти такое линейное преобразование, которое максимизировало бы их совместную энтропию. Для упрощения задачи вместо более сложного условия статистической независимости потребуем, чтобы новые входы после такого преобразования были декоррелированы . Для этого рассчитаем средний вектор и ковариационную матрицу данных по формулам:

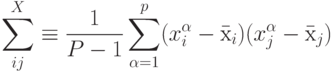
Затем найдем линейное преобразование, диагонализующее ковариационную матрицу. Соответствующая матрица составлена из столбцов - собственных векторов ковариационной матрицы:

Легко убедиться, что линейное преобразование, называемое выбеливанием (whitening)

Если входные данные представляют собой многомерный эллипсоид, то графически выбеливание выглядит как растяжение этого эллипсоида по его главным осям ( рисунок 7.4).

Рис. 7.4. Выбеливание входной информации: повышение информативности входов за счет выравнивания функции распределения
Очевидно, такое преобразование увеличивает совместную энтропию входов, т.к. оно выравнивает распределение данных в обучающей выборке.