
|
Здравствуйте! Записался на ваш курс, но не понимаю как произвести оплату. Надо ли писать заявление и, если да, то куда отправлять? как я получу диплом о профессиональной переподготовке? |
Инспектор
Вы можете этот курс.
Опубликован: 19.03.2004 | Уровень: специалист | Доступ: платный
Лекция 12:
Управление процессами
Смешанные вычисления
Идея смешанных вычислений с точки зрения реализации близка технике ленивых вычислений, но сложилась концептуально из несколько иных предпосылок [9]. Рассматривается пара Программа-Данные при недостаточных данных, отображаемая в так называемую остаточную программу, которая может дать нужный результат, если дать недостающие данные. Для определения такого отображения понадобилась разметка действий программы на исполнимые и задерживаемые. Если такую разметку не связывать с отсутствием данных, то получается модель, практически подобная вычислениям с задержками и возобновлением .
Не всегда неопределенность части данных мешает организовать вычисление.
Рассмотрим
(if (< X Y) Z T)
или эквивалент
if X < Y then Z else T
Если X и Y не определены, но известно, что X лежит в интервале [1, 4], а Y в интервале [5, 6], то логическое выражение X<Y определено, и можно сделать вывод относительно выбора ветви условного выражения и, возможно, получить его значение.
Изучение смешанных вычислений может исходить из разных толкований понятия частичности, т.е. функций, определенных не на всей области их существования.
Первые работы Lombardi в этой области посвящены частичным вычислениям, т.е. обработке частично определенных выражений над числами. Реализация такой обработки на Лиспе осуществляла выполнимые операции и строила из полученных частичных результатов и невыполнимых операций некоторый промежуточный результат — выражение, доопределив которое, можно получить полный результат.
В.Э. Иткин оценивал частичность как практичный критерий эффективности организации деятельности.
При подготовке программ на Лиспе неопределенность часто представляют пустым списком, предполагая, что в него просто не успели что-то записать. Такое представление не всегда достаточно корректно и может потребовать дополнительных соглашений при обработке данных, по смыслу допускающих NIL в качестве определенного значения. Так, при реализации Lisp 1.5 введено соглашение, что значение атома в списке свойств хранится упакованным в список [1].
В работах по формальной семантике стандартных языков программирования принято сведение к неопределенности значений любых операций, зависящих от неопределенных данных.
На практике это приводит к необоснованным потерям части определенной информации и результатов.
A_1+...+A_100_000_000+неопределенность -> неопределенность
Можно обратить внимание, что невелика практическая разница в уровне определенности данных вида (A …) и (A F), где F — рецепт вычисления, про который не всегда известно, приведет ли он к получению результата. Поэтомупрактичнее неопределенные данные "накрывать" рецептами, использующими специальные функции, нацеленные на раскрытие неопределенностей.
Например, роль такой функции может сыграть запрос у пользователя дополнительной информации:
(A …) => (A . ( ||(READ)) )
В определении интерпретатора обработка неопределенностей сосредоточена в функции ERROR.
(DEFUN EVAL (e AL) … ((assoc e AL)(cdr (assoc e AL))) (T(ERROR '"неопределенная переменная")) … )
В определение функции ERROR можно включить обращение к READ, обрамленное сообщением о ситуации с информацией о контексте.
(DEFUN APPLY (f args AL)
…
((assoc f AL)(apply (cdr (assoc f AL))
(evlis args AL)AL))
(T (ERROR ‘"неопределенная функция"))
…
)При отладке сложных комплексов часто неразработанные определения замещают временными "заглушками", которые помогают разобраться в будущей программе по частям. Такую работу можно стандартизировать заданием предварительных определений функций в виде отображения типа аргументов в тип результата. Соответственно, исполнение предопределенной таким образом функции можно интерпретировать как проверку аргументов на соответствие типу аргументов и выдачу в качестве результата вариантов значения, принадлежащего типу результата.
При небольшом числе значений заданного типа, например, истинностные значения, может быть целесообразным полный перебор таких значений с последующим выбором реальной альтернативы пользователем.
(COND (e r)(T g))
=> (assoc e (list (CONS T (EVAL r AL))
(CONS NIL (EVAL g AL))) )Таким образом выполнятся обе ветви, их результаты ассоциируются с различными значениями заданного типа, что позволяет получить нужный результат, как только доопределится ранее не определенное значение. Это позволяет избежать повторного выполнения предшествующих вычислений, если их объем достаточно велик.
Применение библиотечных процедур, зависящих от слишком большого числа параметров, можно упростить для пользователя построением проекций на типовые комплекты трудно задаваемых параметров, понимаемых как определение режима работы процедуры.
(DEFUN f (x y z a b c … v t u) (g …)) (DEFUN Fi (x y z ) (f x y z ai bi ci … vi ti ui))
Примерно это и делает необязательный параметр вида 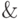 optional в языке Clisp.
optional в языке Clisp.
Такое построение можно рассматривать как декомпозицию, разделение, сортировку на выполнимые и невыполнимые действия, при которой выполнимые действия в тексте определения замещаются их результатом, а невыполнимые преобразуются в остаточные, что все вместе образует проекцию процедуры на заданную часть ее параметров.
Многие выражения по смыслу используемых в них операций иногда определены при частичной определенности их операндов, что часто используется при оптимизации кода программ:
X * 0 = 0 CAR (A …) = A X*1 = X при любом X X-X = 0 X/X = 1 и т.п.Пример 12.2.
Представление функции в некоторых точках при отладке можно задать ассоциативной таблицей:
(SETQ f ‘((a1 . r1)(a2 . r2)(a3 . r3) …)) (DEFUN f (x) (assoc x f))
В такое точечное определение легко добавлять недостающие пары, соответствующие нужным демонстрационным тестам при макетировании программ для согласования их функций на начальных этапах разработки, о чем еще будет речь в лекции 14.
Итак, мы получили некоторое число схем, различных с точки зрения управления вычислениями, полезных в разных ситуациях:
- частичные;
- интервальные;
- многовариантные;
- предопределения;
- точечные;
- проекции.
Возможны и другие, обеспечивающие оптимизацию, компиляцию, предвычисления, макрогенерацию текста программы, что в перспективе может покрыть полное пространство обработки программ в рамках единой методики. Например, основой единого подхода может быть так называемый трансформационный подход, заключающийся в сведении смешанных вычислений к преобразованию программ посредством набора базовых трансформаций.