|
Зачем необходимы треугольные нормы и конормы? Как их использовать? Имеется ввиду, на практике. |
Опубликован: 26.07.2006 | Доступ: свободный | Студентов: 3071 / 549 | Оценка: 4.00 / 3.77 | Длительность: 15:27:00
ISBN: 978-5-94774-818-5
Специальности: Программист, Математик
Теги:
Лекция 14:
Алгоритмы нечеткого контроля и управления
Многошаговые процессы принятия решений
Для простоты будем полагать, что управляемая система  является инвариантной
по времени детерминированной системой с конечным числом состояний.
Именно каждое состояние
является инвариантной
по времени детерминированной системой с конечным числом состояний.
Именно каждое состояние  , в котором система
находится в момент
времени
, в котором система
находится в момент
времени 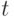 ,
,  , принадлежит заданному
конечному множеству
возможных состояний
, принадлежит заданному
конечному множеству
возможных состояний  ; при этом
входной
сигнал в момент времени является элементом множества
; при этом
входной
сигнал в момент времени является элементом множества  .
Динамика системы во времени описывается уравнением состояния
.
Динамика системы во времени описывается уравнением состояния

 — заданная функция, отображающая
— заданная функция, отображающая  в
в  .
Таким образом,
.
Таким образом,  представляет собой последующее
состояние для при входном сигнале
представляет собой последующее
состояние для при входном сигнале 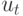 .
Считается также,
что заданы начальное состояние
.
Считается также,
что заданы начальное состояние 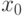 и фиксированное время
окончания
процесса
и фиксированное время
окончания
процесса  .
.Предполагается, что в каждый момент времени на входную
переменную
наложено нечеткое ограничение  , являющееся нечетким
множеством в
, являющееся нечетким
множеством в 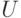 с функцией
принадлежности
с функцией
принадлежности  . Кроме того, считается, что цель —
нечеткое множество
. Кроме того, считается, что цель —
нечеткое множество  в , определяемое функцией
принадлежности
в , определяемое функцией
принадлежности  . Задача заключается в нахождении
максимизирующего решения.
. Задача заключается в нахождении
максимизирующего решения.
Можно записать решение как нечеткое множество в  в виде
в виде
 — нечеткое множество в
— нечеткое множество в  , индуцируемое в .
Для функции принадлежности имеем
, индуцируемое в .
Для функции принадлежности имеем
где  может быть выражено как функция от
может быть выражено как функция от  и
путем последовательного применения уравнения
и
путем последовательного применения уравнения  .
.
Для многошаговых процессов целесообразно представить решение в виде:

 — принятая "стратегия", или
правило выбора входного
воздействия в зависимости от состояния системы .
— принятая "стратегия", или
правило выбора входного
воздействия в зависимости от состояния системы .Таким образом, задача сводится к нахождению оптимальных стратегий и соответствующей
последовательности входных воздействий ,
максимизирующих  . Для решения применяется метод
динамического программирования:
. Для решения применяется метод
динамического программирования:

 может рассматриваться как функция принадлежности нечеткой цели в момент
может рассматриваться как функция принадлежности нечеткой цели в момент  ,
индуцированной заданной целью в момент
,
индуцированной заданной целью в момент  .
.Повторяя процесс обратных итераций, получаем систему рекуррентных уравнений

 ,
которая
дает решение задачи. Таким образом, максимизирующее решение достигается
последовательной максимизацией величин
,
которая
дает решение задачи. Таким образом, максимизирующее решение достигается
последовательной максимизацией величин  , причем
, причем  определяется как функция от
определяется как функция от  .
.В качестве простого примера рассмотрим систему с тремя
состояниями  ,
,  и
и  и двумя входными
сигналами
и двумя входными
сигналами  и
и  . Пусть
. Пусть  и нечеткая цель в момент
времени
и нечеткая цель в момент
времени 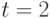 определяется функцией принадлежности, принимающей
значения
определяется функцией принадлежности, принимающей
значения

Пусть далее, нечеткие ограничения в моменты  и
и 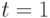 задаются функциями
задаются функциями

Допустим, что таблица изменения состояний, задающая функцию ,
имеет следующий вид:
Находим функцию принадлежности нечеткой цели в момент :

Соответствующее максимизирующее решение имеет вид:

Аналогично, для  имеем
имеем

Итак, если начальное состояние в момент времени есть , то максимизирующим
решением будет , причем соответствующее значение функции
принадлежности  равно 0,8.
равно 0,8.
Владимир Власов