|
С помощью обобщенного алгоритма Евклида найдите числа х и у, удовлетворяющие уравнению 30х +12y = НОД(30,12). х=1, у=-2, НОД = 6. Где ошибка? |
Тульский государственный университет
Опубликован: 19.09.2011 | Доступ: свободный | Студентов: 7918 / 2500 | Оценка: 4.38 / 4.03 | Длительность: 18:45:00
Тема: Безопасность
Специальности: Специалист по безопасности
Теги:
Лекция 14:
Совершенно секретные системы
Энтропия и неопределенность
Таким образом, мы выяснили, что измерение количества информации в сообщении можно проводить на основе учета изменения неопределенности. К. Шеннон ввел понятие энтропии как меры неопределенности. Энтропия H(m) определяет количество информации в сообщении m и является мерой его неопределенности.
Пусть источник сообщений может создавать n разных сообщений m 1 , m 2 , ... m n с вероятностями p 1 , p 2 ,... , p n . В этом случае энтропия сообщения будет определяться формулой

Так как в данной формуле используется двоичный логарифм, то энтропия измеряется в битах, что общепринято в криптографии, теории информации и в компьютерных науках.
"Физический" смысл энтропии состоит в том, что энтропия — это количественная мера неопределенности. В качестве примера рассмотрим три источника сообщений, каждый из которых может генерировать только по два разных сообщения m1 и m2. Пусть известно, что для первого источника вероятность появления первого сообщения р(m1)=0, а вероятность второго сообщения р(m1)=1. Для второго источника вероятности сообщений равны, то есть р(m1)=0,5 и р(m2)=0,5. Для третьего источника вероятности сообщений следующие: р(m1)=0,9 и р(m1)=0,1. Определим энтропию каждого из источников сообщений. Для первого источника:
H1 = -0 * log2 0 – 1 * log2 1 = 0 – 0 = 0
Энтропия или неопределенность первого источника равна нулю. И действительно, если заранее известно, что из двух сообщений всегда генерируется только одно, то никакой неопределенности нет.
Определим энтропию второго источника:

Неопределенность оказалась равной одному биту. Найдем теперь энтропию третьего источника:
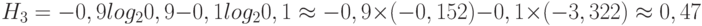
Неопределенность у третьего источника меньше, чем у второго, так как из двух возможных сообщений, генерируемых третьим источником, одно более вероятно, чем другое.
Понятие энтропии играет важную роль во многих задачах теории передачи и хранения информации. В частности, энтропия может использоваться для определения максимальной степени сжатия данных. Точнее, если источник сообщений порождает текст достаточно большой длины n с определенной предельной энтропией h на бит сообщения, то этот текст теоретически может быть сжат до величины n*h бит. Например, если h = 1/2, то текст может сжиматься вдвое и т.д. Значение n*h является пределом и на практике достигается редко.
С точки зрения криптографии, энтропия определяет количество символов, которые необходимо раскрыть, чтобы узнать содержание сообщения. Так, если некоторый 8-битовый блок данных хранит одно из двух возможных сообщений (например, ответы "Да" или "Нет" ), то достаточно правильно узнать один бит, чтобы определить значение исходного сообщения. Сколько бы бит мы не отводили для шифрования слов "Да" и "Нет", энтропия или неопределенность всегда будет меньше или равна 1.
Норма языка и избыточность сообщений
Для каждого языка можно ввести величину, называемую нормой языка r и определяемую по формуле
r = H(m)/N,
где H(m) – это энтропия сообщения, а N – длина сообщения в символах используемого языка. Норму языка можно рассматривать как количество информации, приходящееся на один символ сообщения. Норма языка будет различной для разных языков, а также для сообщений с разной длиной и содержанием. Так, например, различные исследователи оценивают норму английского языка в диапазоне от 1,0 до 1,5 бит на символ. Будем считать, что норма русского языка примерно равна 1,5 бит на символ.
Абсолютной нормой языка R называют максимальное количество бит информации, которое может быть передано одним символом рассматриваемого языка, при условии, что все последовательности символов равновероятны. Абсолютная норма языка, алфавит которого состоит из L символов, может быть вычислена как
R = log2 L
Для русского языка, алфавит которого состоит из 33 букв, абсолютная норма языка

Таким образом, видно, что абсолютная норма русского языка значительно больше, чем реальная. В этом нет ничего удивительного, так как все естественные языки обладают значительной избыточностью. Это связано с несколькими факторами. Во-первых, некоторые буквы алфавита встречаются в сообщениях чаще других. Некоторая статистика по символам русского алфавита приведена в лекции 2, где рассматривается процесс криптоанализа сообщения на основе статистических данных языка. Второй причиной избыточности является то, что некоторые сочетания букв в словах недопустимы. Например, в русском языке нет слов, в которых стояли бы подряд буквы "ц" и "й" или "я" и "ь". Кроме того, естественные языки устроены таким образом, что иногда, зная фрагмент слова или фразы, мы может восстановить недостающую часть. Например, в приветствии
Зд.авствуй, до.огой д.уг!
мы легко сможет восстановить недостающие буквы "р".
Избыточность языка D оценивают как
D =R – r.
Избыточность русского языка получается равной 3,5 бит на символ. Это означает, что в среднем каждая буква русского языка содержит 3,5 бита неиспользуемой информации. Примерно такую же избыточность имеют и другие естественные языки, например, английский.
Минимальной избыточностью сообщений D = 0 обладал бы язык, в котором все символы равновероятны и могут встречаться в сообщениях независимо друг от друга в любом порядке.
Понятие совершенно секретной системы
Криптографическая система называется совершенно секретной, если анализ зашифрованного текста не может дать никакой информации об открытом тексте, кроме, возможно, его длины.
Если криптографическая система не является совершенно секретной, то знание шифротекста сообщения предоставляет некоторую информацию относительно соответствующего открытого текста. Для большинства простых систем шифрования, например, методов однократной замены или перестановки, по мере увеличения длины перехваченного зашифрованного сообщения можно делать некоторые выводы о ключе шифрования или об открытом тексте. Это связано с большой избыточностью естественных языков. Так, например, если перехвачено сообщение, зашифрованное методом перестановки, то противник может узнать, какие символы и в каком количестве встречались в исходном сообщении, а после этого может попробовать провести какой-либо более сложный анализ с целью определения правила перестановки. Если нам известно зашифрованное методом моноалфавитной замены сообщение ДКДК, мы, конечно, без дополнительной информации не сможем однозначно определить, что содержалось в исходном тексте. Однако, получив в свое распоряжение ДКДК, мы сможем сделать вывод, что
- в исходном сообщении использовалось всего две буквы алфавита
- первая и третья, а также вторая и четвертые буквы открытого текста были одинаковы.
Можно также предположить, что либо Д, либо К заменяют гласную букву. Может быть, исходное сообщение представляло собой слово МАМА, а может быть ПАПА, а может быть что-нибудь еще. Однозначно дешифровать его нельзя, однако некоторую информацию по шифротексту мы смогли определить. Таким образом, можно сделать вывод, что методы перестановки или замены не являются совершенно секретными криптографическими шифрами.
На практике возможна следующая реализация совершенно секретной системы, называемая одноразовая лента (или одноразовый блокнот, или шифр Вернама по имени американского инженера, предложившего эту систему в первой половине ХХ века). Будем предполагать, что процессу шифрования подвергаются двоичные данные. На передающей и приемной сторонах подготавливаются две одинаковые ленты, например, магнитные. Они содержат ключ шифрования. На передающей стороне лента помещается в устройство шифрования, а на принимающей стороне – в идентичное устройство, используемое для расшифрования. Когда отправитель хочет передать сообщение, он складывает по модулю два один бит исходного сообщения и один бит с магнитной ленты. После этого лента перемещается в следующее положение и можно шифровать второй бит сообщения, используя второй бит ключа. Таким образом шифруется все сообщение. На принимающей стороне лента с ключом используется аналогично.
Например, пусть исходное сообщение m содержит следующие двоичные цифры:
m = 1100101110...
Предположим, в качестве ключевой используется последовательность:
k = 1001100111...
Выполним шифрование по методу одноразовой ленты, сложив цифры в каждом столбике по модулю 2:
исходный текст m = 1100101110... биты ключевой послед-ти k = 1001100111... ------------------- зашифрованный текст с = 0101001001...
Этот процесс напоминает наложение гаммы на поток входных данных. Шифр с одноразовой лентой действительно является гаммированием, однако, в отличие от всех рассмотренных до этого криптосистем в нем предполагается бесконечная гамма.
В одноразовой ленте все буквы встречаются с одинаковой частотой. Поэтому, сколько бы знаков гаммы нам ни было известно, мы не сможем предсказать, какой будет следующая буква. Из этого следует, что все последовательности знаков гаммы равновероятны. Это означает, что сообщение, зашифрованное с помощью шифра Вернама, может быть "дешифровано" в любой открытый текст подходящей длины, поскольку предполагаемая последовательность знаков гаммы не имеет никаких свойств, позволяющих отличить её от любой другой.
В шифре Вернама, конечно, совсем необязательно использовать в качестве носителя ключевых данных именно ленту. Главное, чтобы у отправителя и получателя был секретный ключ размера не меньшего, чем длина исходного сообщения. Проблемы могут возникнуть при шифровании большого объема данных, так как запасы ключевых цифр должны быть заблаговременно доставлены получателю информации и храниться у него.
Совершенно секретные системы могут быть реализованы на практике. Почему же они не используются во всех случаях? Это объясняется несколькими причинами. Во-первых, как и любые системы шифрования с закрытым ключом в них существует проблема распределения ключей. Во-вторых, в совершенной секретной системе ключ шифрования должен иметь по крайней мере такую же длину, как и открытый текст. Кроме того, для шифрования каждого сообщения должен применяться свой новый ключ. Все эти факторы делают реализацию совершенно секретной системы очень дорогой и не слишком удобной. Такие системы имеет смысл использовать лишь для самых важных линий связи, например, правительственных.