Языки программирования
3.3. Основы компиляции
Сегодня компиляторы (и интерпретаторы) являются хорошо продуманными программными системами, которые вобрали опыт многочисленных исследований и разработок, продолжающихся уже 50 лет. Главная задача компилятора состоит в генерации кода для целевой машины, но это не единственная задача, как мы видели, – он должен проверять правильность программы.
Задачи компилятора
Компиляторы могут существенно различаться в деталях, но для всех вариантов есть общие задачи. Рассмотрим их примерно в том порядке, в котором компилятор должен применять их при обработке исходного текста.
Лексический анализ преобразует текст в последовательность лексем, представляющих идентификаторы, константы, ключевые слова и символы. Мы уже знакомы с базисными методами, используемыми при решении этой задачи: конечные автоматы и регулярные грамматики.
Синтаксический анализ воссоздает синтаксическую структуру программы.
Проверка правильности включает контроль типов и другие согласованные проверки. Eiffel, например, имеет примерно 90 "правил контроля правильности", таких как:
- в операторах присваивания и при передаче аргументов тип источника должен соответствовать типу цели;
- класс B не может назвать класс A своим родителем, если родителем B назван предок A. Это правило защищает от возникновения циклов при наследовании.
Семантический анализ включает обработку результатов, полученных на этапе синтаксического анализа, – структур данных, которые будут описаны ниже, таких как абстрактное синтаксическое дерево и таблица символов. На этом этапе создается важная семантическая информация, используемая на следующих шагах.
Генератор кода создает целевой код из исходного кода. Возможно, что на этом этапе будут выполняться несколько шагов по генерации кода, поскольку компиляторы могут использовать промежуточные представления, прежде чем сгенерировать окончательный код. Для исходного кода на Eiffel компилятор EiffelStudio генерирует байт-код, доступный для интерпретации (как часть технологии тающего льда, обсуждаемой ниже), но он также используется как промежуточный код, для которого компилятор может сгенерировать финальный целевой код.
Оптимизация улучшает процесс генерации кода, позволяя создавать более эффективный код. Оптимизация может встречаться в конъюнкции с некоторыми предшествующими задачами, такими как семантический анализ и генерация кода. Примеры оптимизации включают:
- распределение регистров – оптимизация периода выполнения. Математически
 имеет то же значение, что и
имеет то же значение, что и  , но одна из этих форм может выполняться быстрее другой из-за более эффективного распределения регистров. Оптимизация приводит к тому, что генератор кода выберет быстрейший вариант;
, но одна из этих форм может выполняться быстрее другой из-за более эффективного распределения регистров. Оптимизация приводит к тому, что генератор кода выберет быстрейший вариант; - удаление участков "мертвого кода". Если оптимизатор обнаружит, что некоторые участки кода программы никогда не будут выполняться во время исполнения, то он может удалить соответствующий сгенерированный код, а еще лучше – вообще не генерировать его с самого начала.
Фундаментальные структуры данных
Задачи лексического и синтаксического анализа взаимосвязаны: "парсер" вызывает "лексер" (сокращения для синтаксического и лексического анализатора) для получения очередной лексемы. Главным результатом работы парсера является АСТ (абстрактное синтаксическое дерево), которое задает структуру программы, очищенную от чисто текстуальных свойств, таких как ключевые слова. Другой фундаментальной структурой данных является таблица идентификаторов, в которой записаны имена, используемые в программе, – имена классов, методов, локальных переменных, других сущностей, – и свойства, связанные с каждым из этих имен. Например, для локальной переменной хранится тип этой переменной, метод, которому она принадлежит. Другие свойства, полезные для семантического анализа и оптимизации, могут включать списки операторов, использующих значение этой переменной, и списки операторов, модифицирующих ее значение. Хэш-таблицы, изучаемые в этой лекции, хорошо подходят для реализации таблицы идентификаторов.
Для типичной организации современных компиляторов в задачу лексера и парсера входит создание АСТ и таблицы идентификаторов, инициализированной базисной чисто синтаксической информацией. Оставшиеся компоненты компилятора обогащают, часто говорят – декорируют, эти структуры данных более глубокой семантической информацией.
Проходы
Традиционное описание процесса компиляции включает понятие "прохода". На каждом проходе компилятор просматривает всю программу, выполняя специфические операции на ее компонентах. Важность этого понятия обусловлена еще и историей. На каждом проходе программа имеет свое представление – вначале это исходный текст, затем АСТ и так далее. В старые почтенные времена такие представления не помещались в оперативной памяти изза ее ограниченных размеров и хранились во внешней памяти в виде отдельных файлов на диске, а еще раньше – на магнитных лентах. Компиляция состояла из последовательности проходов, каждый из которых обрабатывал ранее полученный файл и создавал новый. Естественное требование сокращения времени компиляции диктовало необходимость минимизации числа проходов.
Эти соображения влияли даже на проектирование языка. Паскаль, например, был явно спроектирован со строгим ограничением на "ссылки вперед": не допускается в языке вызов процедуры, предшествовавший ее описанию (вначале опиши в тексте, а потом можешь вызывать). Такое ограничение позволяло выполнить однопроходную компиляцию.
Сегодня ситуация другая и понятие прохода менее четкое. В большинстве применяемых схем четко выделяется первый проход, на котором комбинация лексера и парсера создает АСТ и таблицу идентификаторов, а далее в процессе компиляции эти структуры данных обрабатываются и декорируются.
Компилятор как инструмент верификации
Всю значимость компилятора можно оценить, если вспомнить уже неоднократно высказанную мысль, что компилятор в дополнение к своей главной роли является еще и инструментом верификации. Для современных строго типизированных языков свойства типов предоставляют важную семантическую информацию. Правила проверки, используемые в Eiffel, описывают множество свойств, которые должны быть согласованными, что позволяет улучшить надежность создаваемого ПО. Выполняя проверку правильности, компилятор требует, чтобы эти правила выполнялись, обеспечивая тем самым обнаружение ошибок еще на этапе компиляции.
Исследования, выполненные в инженерии программ, показали все преимущества раннего обнаружения ошибок. Стоимость ошибок, обнаруженных динамически во время выполнения, гораздо выше стоимости статически обнаруживаемых ошибок. С этой точки зрения ошибки времени компиляции – это хорошие новости.
Загрузка и связывание
Программам в машинном коде необходимы адреса памяти. Присваивание x: = expr будет помещать значение выражения expr по адресу памяти, связанному с x. В условном операторе if c then a … управление будет передаваться в зависимости от вычисленного значения условия c по различным адресам, связанным с соответствующими участками кода. Вызов метода r(…) или x.r(…) приведет к передаче управления по адресу соответствующего кода, а затем вернет управление в точку, следующую за вызовом метода.
Точные адреса памяти компилятору недоступны. На современных процессорах большинство программ выполняются параллельно. Специальная программа операционной системы – загрузчик – ответственна за запуск других программ. Всякий раз, когда необходимо запустить на выполнение программу, загрузчик должен выделить программе соответствующую память и разместить там программу и ее данные. Такая схема позволяет компилятору не включать в генерируемый код фактические адреса памяти.
- Когда обрабатываются элементы программы, принадлежащие некоторому модулю, например, методы класса, компилятор управляет только относительными адресами в области памяти, отведенной модулю. Например, когда он обрабатывает неквалифицированный вызов r(…), появляющийся в методе того же класса C, что и r, компилятору известно смещение кода для r внутри области, отведенной для C. Компилятору неизвестны соответствующие абсолютные адреса, которые могут быть установлены только в момент загрузки и могут меняться от одного сеанса выполнения к другому.
- Для элементов другого модуля адреса будут смещаться относительно начального адреса этого модуля. Если бы вся программа компилировалась полностью, то это соответствовало бы уже рассмотренной нами ситуации, поскольку компилятор мог бы определить раскладки для всех модулей. Но часто желательно допускать раздельную компиляцию, когда модули компилируются независимо друг от друга и только потом объединяются в единую программу.
Первая задача имеет два возможных решения. Некоторые операционные системы применяют распределяющий загрузчик, который перед выполнением добавляет к каждому относительному адресу стартовый адрес модуля. Другое более общее решение: сама аппаратура спроектирована так, чтобы непосредственно использовать относительные адреса, интерпретируя адреса всех операторов относительно начального адреса.
Вторая задача требует применения еще одного инструмента операционной системы, называемого компоновщиком, или линкером, в задачу которого входит связывание отдельных независимо скомпилированных модулей в единый модуль. Любой из модулей, подаваемых на вход линкеру, может иметь так называемые неразрешенные ссылки, которые компоновщик будет заменять всюду, где это возможно, адресами, полученными из других модулей. Этот процесс может быть итеративным: если не все ссылки имеют целью уже связанные модули, то выход линкера может содержать еще не разрешенные ссылки, которые будут заполняться позже, на следующем шаге связывания.
Связывание является простой по концепции операцией, но может приводить к временным затратам, поскольку необходимо просматривать все множество модулей, подлежащих связыванию, что делает время связывания потенциально пропорциональным размеру программы. Желание справиться с этой проблемой привело к технологии "возрастающей компиляции", когда перекомпиляции подлежит только та часть программы, которую затрагивают сделанные изменения.
Время выполнения
Сегодняшние амбициозные языки программирования требуют не только изощренного инструментария в период компиляции (включая изощренный компилятор), но также серьезной поддержки на этапе выполнения. Когда программа выполняется, ей необходимо динамическое распределение памяти (для таких операторов, как конструкторы класса create x), нужна автоматическая сборка мусора, которая освобождает память от объектов, ставших недоступными программе, требуется обработка исключений и поддержка ввода и вывода. Аппаратура обычно напрямую не поддерживает эти механизмы. Эффективное управление памятью, в частности, основано на сложных алгоритмах и структурах данных.
Это потребности всех программ, а потому было бы неразумно, если бы компилятор генерировал соответствующий код для каждой программы. Вместо этого, когда программе понадобится одно из таких свойств, компилятор включает в генерируемый код вызов соответствующего метода из библиотеки, известной как система времени исполнения, или библиотека времени исполнения, или просто исполняемая среда (the run time). Программный код перед выполнением должен быть скомпонован с библиотекой исполняемой среды.
Другой способ установки роли исполняемой среды состоит в том, чтобы связать ее с понятием виртуальной машины. В то время как типичные машинные команды и видимые свойства "железа" – не считая скорости и размеров – не слишком изменились за последние пятьдесят лет, языкам программирования требуются более продвинутые виртуальные машины. Мы уже видели, что вполне возможно построить такую машину с собственными командами, например, байт-код, и создать компилятор, преобразующий исходный текст в код виртуальной машины. Полученный таким образом код может интерпретироваться, и недостаток такого подхода состоит в возможной потере эффективности. Другой возможный подход состоит в генерации кода для фактической аппаратуры, с обеспечением при этом более продвинутых механизмов исполняемой среды. В этом случае виртуальная машина представляет комбинацию аппаратуры и исполняемой среды.
Для современных ОО-языков исполняемая среда необходима в той же степени, что и компилятор.
Отладчики и инструментарий выполнения
После того, как программа скомпилирована и скомпонована, возникает естественное желание запустить ее на выполнение. Окончательная версия программы типично является исполняемым exe-файлом. Но до завершения разработки необходимо контролировать выполнение, чтобы иметь возможность, например, в случае возникновения ошибки, исследовать контекст выполнения – анализировать содержимое объектов в точке ее проявления. Для этого необходим отладчик (debugger). Роль отладчика не только в том, чтобы отладить программу, разыскивая в ней ошибки (bug). Современные отладчики представляют инструментарий, предназначенный, как теперь модно говорить, для мониторинга за процессом выполнения программы.
Типичный отладчик включает такие средства, как задание точек останова (прерывания) в исходном тексте, запуск, прерывание, продолжение и завершение выполнения. Когда выполнение останавливается, что может быть вызвано одной из трех причин: достижением точки останова, возникновением ошибки или прерыванием, инициированным пользователем, – отладчик позволит исследовать код, приведший к текущему состоянию, проанализировать структуру объектов, видя их содержимое, динамически вычислять выражения, выполнять различные другие проверки программы и ее данных. В некоторых случаях отладчики, такие как отладчик EiffelStudio, позволяют выполнить откат по программе, чтобы повторно в пошаговом режиме проследить и понять причину, приведшую к такому состоянию (появлению ошибки). Следующий рисунок показывает типичное состояние отладчика EiffelStudio.
Наличие хороших отладчиков не дает нам права на "плохое" программирование (не надейтесь, что любая ошибка будет обнаружена в процессе отладки). Контроль выполнения может помочь только в некоторых случаях из несметного числа возможных сеансов выполнения.
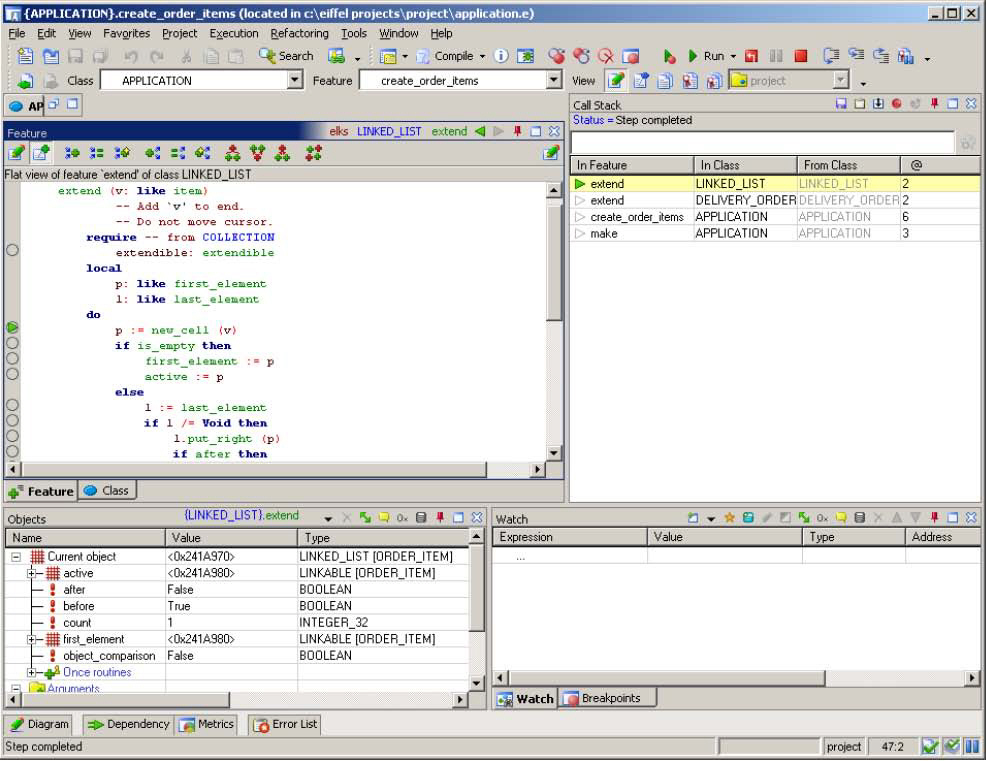
Методы динамической верификации, такие как отладка, не являются заменой статической верификации и проверки правильности. Всегда лучше избежать ошибки, чем исправлять уже допущенную. Отладчики важны, поскольку позволяют экспериментировать с программой и получать конкретное представление о ее поведении в момент выполнения.
3.4. Верификация и проверка правильности
Отладчики типично поддерживают проверку программы, выполняемую самими разработчиками. Перед тем, как работа над программой будет считаться законченной и она может быть передана пользователям, программа обычно подвергается систематическому процессу верификации и проверки правильности (verification and validation – V & V), который выполняется специальными людьми – тестировщиками.
Под верификацией понимают проверку внутренней согласованности, под проверкой правильности – проверку на соответствие внешним спецификациям. В лекции, посвященной инженерии программ, процессу V & V будет уделено больше внимания. На данный момент просто стоит понимать, что соответствующие средства относятся к двум разным категориям.
- Статические анализаторы основываются на программных текстах. Примером является принуждение соблюдений правил согласованности типов и других ограничений правильности, выполняемых компилятором. Средства статического анализа на этом не останавливаются и идут далее в направлении возможного доказательства корректности программы.
- Динамические методы должны выполнять программу, тестируя ее на соответствие ожидаемым результатам.