Алтайский государственный университет
Опубликован: 12.07.2010 | Доступ: свободный | Студентов: 1462 / 389 | Оценка: 4.02 / 3.93 | Длительность: 16:32:00
ISBN: 978-5-9963-0349-6
Тема: Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Теги:
Лекция 4:
Многоядерные процессоры с низким энергопотреблением
Архитектура процессоров SEAforth
Процессоры SEAforth [1, 2] позиционируются как многоядерные процессоры для встраиваемых систем реального времени. Построены по технологии встраиваемого масштабируемого массива — Scalable Embedded Array.
Одно из основных возможных применений процессов SEAforh — производственные контролирующие и сенсорные системы, контроллеры сенсорных сетей, мультимедийные системы [3, 4].
Данные процессоры отвечают практически всем современным тенденциям — параллелизм, низкое энергопотребление, высокая скорость работы ядра. Есть также и моменты, которые ставят их особняком: кроме стековой архитектура ядра это отсутствие модуля вещественных вычислений; отсутствие кэша, если сравнивать с процессорами; малый объем памяти, небольшое количество периферийных устройств, если проводить сравнение с микроконтроллерами.
Имея в своем распоряжении несколько десятков ядер, программист может выделять некоторые группы из них для решения различных специализированных задач. Для типовых задач возможно создание т. н. параметризированных макроблоков из нескольких ядер. В результате получается гибкая мультипроцессорная система, предназначенная для решения широкого круга прикладных задач.
Поскольку объем памяти для размещения программ мал, типичной практикой в программировании процессора является замена исполнимого кода во время исполнения программы. Как правило, каждое ядро исполняет относительно небольшую функцию или блок приложения, что характерно для большого количества задач управления или обработки потоков данных. В качестве примера можно привести реализацию QPSK-приемника и передатчика на SEAforth24 [3].
Одно из основных возможных применений процессов SEAforth — производственные контролирующие и сенсорные системы, контроллеры сенсорных сетей [4], мультимедийные системы. Причины, обусловливающие это:
- возможность параллельной обработки данных в реальном времени;
- возможность распределенного управления промышленной сетью.
К процессору в системе сбора данных могут быть подключены датчики практически с любым интерфейсом (при условии согласования уровней напряжения) и различными протоколами обмена. Это достигается за счет программного управления линиями ввода-вывода, таким образом, различные ядра процессора имеют возможность взаимодействовать с датчиками по различным протоколам. Упрощается также замена датчиков — при необходимости вносятся коррективы только в программное обеспечение.
Кроме непосредственно сбора данных параллельно процессор может вести их обработку в реальном времени, включая такие вычислительно емкие задачи, как цифровая фильтрация, быстрые преобразования (Фурье, Уолша, Хартли и др.), анализ аудио-, видео- или радиосигналов, PID-регулирование, ФАПЧ.
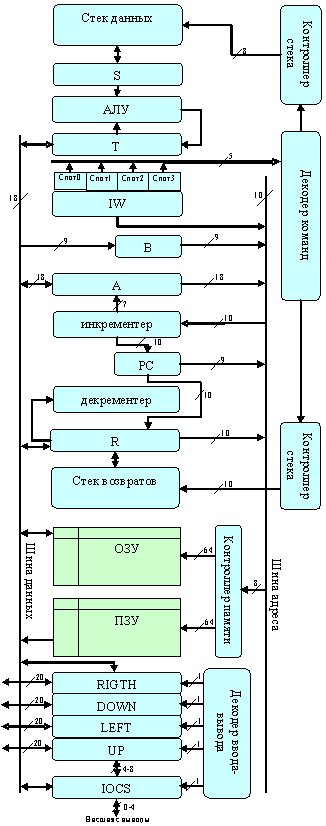
Процессор состоит из множества независимых вычислителей, соединенных по топологии двумерной прямоугольной решетки, имеет ряд последовательных портов, параллельные порты, выводы общего назначения, АЦП, ЦАП (рисунок 4.7). Каждый из вычислителей является фон-неймановским стековым процессором с сокращенным набором команд, имеет собственную оперативную память, порты ввода-вывода и постоянную память с рядом предустановленных фирменных функций. Взаимодействие вычислителей (далее — ядер) осуществляется посредством механизма параллельных взаимодействующих процессов (парадигма ОККАМ). В некотором приближении процессор можно рассматривать как сеть из миниатюрных транспьютероподобных узлов. Глобальная синхронизация ядер отсутствует.
Линии ввода-вывода можно применять для программной реализации различного рода интерфейсов, помимо ограниченной поддержки основных последовательных интерфейсов в ПЗУ некоторых ядер. Последовательные порты могут быть использованы для соединения нескольких процессоров.
Программное управление линиями ввода-вывода позволяет поддерживать несколько форматов цифровых сигналов и видов модуляций аналоговых сигналов, в отличие от специализированных СБИС, поддерживающих 1-2 стандарта.

Интерфейсы и протоколы, реализуемые программно, могут варьироваться от простых протоколов, аналогичных RS-232, SPI, до достаточно сложных алгоритмов кодирования типа QPSK или QAM. При этом максимальные скорости обмена данными лежат в диапазоне 10-20 Мбит/с.
В процессорах применен ряд технологий, позволяющих добиться значительной экономии энергии. Наиболее заметная из них: ядро, первым подошедшее к точке передачи данных, автоматически переходит в спящий (пассивный) режим до тех пор, пока взаимодействующее с ним ядро не подойдет к этой же точке. При этом время выхода из пассивного режима составляет примерно 10 нс. В спящем режиме ядро рассеивает порядка 1 мкВт, плюс обеспечивается прозрачная для прикладного программиста синхронизация процессов, выполняющихся на различных ядрах. Как правило, во время работы приложения активны одновременно активны 8-16 ядер. Вторая особенность — внутреннее представление данных. На физическом уровне в ядре в соседних битах одинаковые логические уровни представлены противоположными уровнями напряжений. Например, если в регистре находится число 100010b, то физические уровни напряжений на его выходах будут следующие: НННВВВ. И третий момент — отсутствие глобальной синхронизации ядер и асинхронное исполнение самого ядра (нет тактовых генераторов). Низкое энергопотребление и высокая энергетическая эффективность являются одними из ключевых свойств процессоров SEAforth.
В процессорах SEAforth не используется механизм прерываний. В случае необходимости ядро переходит в пассивный режим, ожидая записи или чтения в коммуникационный порт. При этом время перехода из пассивного в активный режим и наоборот крайне мало — <10нс. Благодаря наличию нескольких периферийных ядер процессор может одновременно обслуживать несколько источников событий с минимальной задержкой, что идеально для систем, работающих в режиме жесткого реального времени. Поскольку ядра асинхронные, исполнение программы происходит с максимально возможной скоростью. Процессор не нуждается в режимах пониженной частоты, характерных для обычных микроконтроллеров с целью понижения энергопотребления.
Процессор SEAforth40 (40С18) содержит 40 ядер (рис.4.8), объединенных в решетку 4х10.
Ввод-вывод в SEAforth программно доступен по трем путям:
- цифровые выводы, доступные через специальные регистры или регистры IOCS;
- межпроцессорные коммуникации, выполняемые при помощи направленных портов;
- аналоговый ввод-вывод, доступный через специальные регистры или регистры IOCS.
Каждое ядро C18 разделяет до четырех портов ввода-вывода со своими соседями. В общем случае межпроцессорные коммуникации являются блокирующими и самосинхронизирующимися — это значит, что процессор уходит в спящее состояние, пока операция не будет завершена.
Каждый межпроцессорный коммуникационный порт соединен напрямую со своими соседями — соседние узлы разделяют один порт. Общий порт имеет для соседних процессоров один и тот же адрес. Нет регистров или FIFO-буфера — одни линии порта напрямую соединены с соседними линиями записи. Значение, записанное в порт, может иметь различные интерпретации — узел, проводящий чтение, может исполнить считанный код. Когда процессор проводит операцию чтения, он блокирует запись соседнего процессора; когда процессор пишет, он блокирует операцию записи соседа. Подобный метод синхронизирует соседние процессоры. Блокировка — ключевой элемент в уменьшении потребляемой процессором мощности и средство синхронизации ядер (процессов). В блокированном состоянии ядро практически не потребляет мощности. Только один из процессоров блокируется во время транзакции — тот, кто входит в нее первым. Блокировки можно избежать, считывая бит статуса в регистре IOCS перед операцией чтения или записи. Возможны операции множественного чтения/записи в порт. При наличии готового к транзакции соседнего узла операции чтения/записи занимают порядка 4,2 нс.
Каждое ядро, входящее в состав процессоров SEAforth, содержит 18-разрядный микропроцессор С18, имеющий 64 18-разрядных слова ОЗУ, 64 18-разрядных слова ПЗУ с заранее прошитыми функциями (т. н. Intellasys-bios), 4 порта ввода-вывода. Некоторые узлы, находящиеся по краям решетки, имеют дополнительно последовательный или параллельный порт, АЦП или ЦАП. Функции, прошитые в ПЗУ отдельных ядер, также несколько отличаются.
По сравнению с предыдущей моделью в его ядра С18 внесены изменения, существенно упрощающие организацию вычислительного процесса. Был добавлен т. н. режим расширенной арифметики, при котором перенос сохраняется в 10-м бите регистра Р (данный бит в адресации памяти не участвует); таким образом, появляется возможность производить операции над многоразрядными числами. Вторая особенность АЛУ — операция +* производится между вторым элементом стека и регистром A. Старшее слово результата помещается на вершину стека, младшее остается в регистре A, второй элемент стека — регистр S — остается без изменений. Два ядра процессора имеют высокоскоростные интерфейсы SERDES, отсутствовавшие в SEAforth24.
Производительность ядра — примерно 700 MIPS (время выполнения инструкции примерно 1,4 нс) при уровне потребления мощности ~12 мВт. Соответственно — максимальная мощность, рассеиваемая процессором при полной загрузке всех узлов, не более 250-400 мВт, что сравнимо со многими сигнальными процессорами.
Помимо ОЗУ и ПЗУ C18 содержит два стека — данных и возвратов, с выделенными регистрами вершин стеков и логикой управления, регистр слова-инструкции, программный счетчик, АЛУ, декодер команд и логику выборки команд, а также два индексных регистра. Инструкции имеют длину всего лишь 5 бит, что позволяет упаковывать три или четыре инструкции в одно 18-битное слово. 18-битное слово содержит до 4 опкодов, выбираемых слот-селектором, и передается на декодер и логику контроля, управляющую функциями ядра. Восемь из 5-битных инструкций могут быть помещены в 3-битный слот, как последний код операции в слове. Таким образом, максимально в оперативной памяти С18 можно разместить 256 команд, что с учетом высокой реентерабельности форт-кода достаточно для реализации многих алгоритмов и прикладных программ.
Стеки в С18 — массивы регистров. Стек данных используется для выполнения арифметических операций. Два наиболее часто используемых регистра могут быть доступны непосредственно — T и S. Оба они подключены к АЛУ, результат операций помещается в регистр Т. Ниже находится циклический массив из 8 регистров. Один из этих регистров в каждый момент времени выбирается как регистр, следующий за S. АЛУ, использующее регистры T и S, вычисляет все возможные арифметические операции параллельно, используя комбинаторную логику. Текущей командой выбирается необходимый результат из АЛУ и помещается в Т.
C18 имеет девять 18-битных регистров стека возвратов. Верхняя позиция стека возвратов находится в регистре R. Под R также находится циклический массив из 8 регистров. Инструкции вызова оставляют значение программного счетчика на стеке возвратов. Команды возврата снимают только 9 младших разрядов. Стек возвратов также может быть использован для временного хранения данных и в качестве счетчика циклов.
| PC | 9-ти битный программный счетчик (10-битный для процессора 40с18) |
| T,S | Первый и второй элемент стека данных |
| R | Верхний регистр стека возвратов. Один из 9-ти регистров стека возвратов, доступен через push/pop,call/return |
| A | 18-битный регистр общего назначения, адресный, автоинкрементный |
| B | 9-битный адресный регистр |
| IW | 18- битное слово инструкции |
| RIGTH, DOWN, LEFT, UP | Коммуникационные регистры (являются общими с соседними ядрами) |
| IOCS | Регистр режим выводов и статус ввода-вывода |
| DATA | Внешняя шина данных |
| ADDRESS | Адресный регистр внешней памяти |
Аппаратного контроля за переполнением и исчерпанием стеков не предусмотрено. Поскольку регистры в стеке связаны в кольцо, они не могут переполниться или исчерпаться, они просто "прокручиваются". Так как глубина стека ограничена, добавление элемента на стек означает затирание самого нижнего элемента. Когда идет извлечение из стека, нижние 8 элементов будут повторяться. После двух чтений T и S будут содержать копии двух элементов массива стековых регистров.
Выходы программного счетчика PC управляют адресной шиной (подаются на шину адреса) программный счетчик по выполнении инструкции инкрементируется. Данные, адресуемые РС, загружаются в регистр инструкций IW.
Регистры IOCS - предназначены как для ввода-вывода, так и для мониторинга межпроцессорного обмена. Они являются комбинацией элементов хранения бит статуса, показывающих, произошли ли операции чтения или записи (с той или другой стороны). Также они содержат значение, выводимое или считанное с линии ввода-вывода. Режим и выходное состояние линии устанавливается записью в IOCS. Типовое время доступа к регистрам IOCS – 2,8нс.
Структура адресного пространства. Карта распределения адресного пространства микропроцессора С18 выглядит следующим образом - рис.3. Оперативная, постоянная память, специальные регистры и порты ввода-вывода находятся в одном адресном пространстве и для работы с ними применяются одни и те же команды.

При выполнении программы логика берет значение с адресной шины и вычисляет новый адрес параллельно со временем доступа шины. Результат становится доступным для PC или для регистра А. Использование инкрементированного адреса определяется текущей инструкцией. При нормальном потоке выполнения результат записывается в РС. В пределах границы 128 слов, инкрементированный адрес может прокрутиться к началу страницы, следовательно, RAM и ROM появляются в двух различных диапазонах.
Когда бит 8 адреса равен 1, идет адресация в пространстве ввода-вывода и увеличение адреса запрещено, т.е. когда регистр указывает на порт, указатель не сдвигается. Это значит, что выборка инструкций, литералов, запись литералов выполняются непосредственно с порта. Вызов с порта возвращает на порт.
Процессор имеет достаточно большой объем математических библиотек и библиотек ввода-вывода (таблица 4.2). Математическая библиотека содержит наборы функции умножения: mlt, fmult, для операций с целыми числами и с числами в формате с фиксированной точкой, деления с остатком um/mod (имеет несколько точек входа), линейной интерполяции — interp, работы с векторами — rotation, вычисление полиномов — poly, вычисления триангулярной функции — triangle, taps — слова для организации расчета цифровых фильтров.
Функции ввода-вывода представлены набором слов для последовательных интерфейсов (синхронного и асинхронного — представлены в основном функциями чтения данных с порта). Spi — слова начальной загрузки с флэш-памяти, чтения последовательной памяти. Serial — чтение данных с последовательного порта. Sget — работа с синхронным последовательным портом. Bget — чтение данных с асинхронного последовательного порта. Upserdes — поддержка работы с высокоскоростными последовательными портами SERDES (загрузка и исполнение кода).