Параллельное программирование с использованием OpenMP
7.2. Выделение параллельно-выполняемых фрагментов программного кода
Итак, параллельная программа, разработанная с использованием OpenMP, представляется в виде набора последовательных ( однопотоковых ) и параллельных ( многопотоковых ) фрагментов программного кода (см. рис. 7.2).
7.2.1. Директива parallel для определения параллельных фрагментов
Для выделения параллельных фрагментов программы следует использовать директиву parallel:
#pragma omp parallel [<параметр> ...] <блок_программы>
Для блока (как и для блоков всех других директив OpenMP) должно выполняться правило "один вход - один выход", т.е. передача управления извне в блок и из блока за пределы блока не допускается.
Директива parallel является одной из основных директив OpenMP. Правила, определяющие действия директивы, состоят в следующем:
- Когда программа достигает директиву parallel, создается набор ( team ) из N потоков; исходный поток программы является основным потоком этого набора ( master thread ) и имеет номер 0.
- Программный код блока, следующий за директивой, дублируется или может быть разделен при помощи директив между потоками для параллельного выполнения.
- В конце программного блока директивы обеспечивается синхронизация потоков - выполняется ожидание окончания вычислений всех потоков; далее все потоки завершаются - дальнейшие вычисления продолжает выполнять только основной поток (в зависимости от среды реализации OpenMP потоки могут не завершаться, а приостанавливаться до начала следующего параллельного фрагмента - такой подход позволяет снизить затраты на создание и удаление потоков).
7.2.2. Пример первой параллельной программы
Подчеркнем чрезвычайно важный момент - оказывается, даже такого краткого рассмотрения возможностей технологии OpenMP достаточно для разработки пусть и простых, но параллельных программ. Приведем практически стандартную первую программу, разрабатываемую при освоению новых языков программирования - программу, осуществляющую вывод приветственного сообщения "Hello World !" Итак:
#include <omp.h>
main () {
/* Выделение параллельного фрагмента*/
#pragma omp parallel
{
printf("Hello World !\n");
}/* Завершение параллельного фрагмента */
}
7.1.
Первая параллельная программа на OpenMP
В приведенной программе файл omp.h содержит определения именованных констант, прототипов функций и типов данных OpenMP - подключение этого файла является обязательным, если в программе используются функции OpenMP. При выполнении программы по директиве parallel будут созданы потоки (по умолчанию их количество совпадает с числом имеющихся вычислительных элементов системы - процессоров или ядер), каждый поток выполнит программный блок, следуемый за директивой, и, как результат, программа выведет сообщение "Hello World !" столько раз, сколько будет иметься потоков.
7.2.3. Основные понятия параллельной программы: фрагмент, область, секция
После рассмотрения примера важно отметить также, что параллельное выполнение программы будет осуществляться не только для программного блока, непосредственно следующего за директивой parallel, но и для всех функций, вызываемых из этого блока (см. рис. 7.3). Для обозначения этих динамически-возникающих параллельно выполняемых участков программного кода в OpenMP используется понятие параллельных областей ( parallel region ) - ранее, в предшествующих версиях стандарта использовался термин динамический контекст ( dynamic extent ).
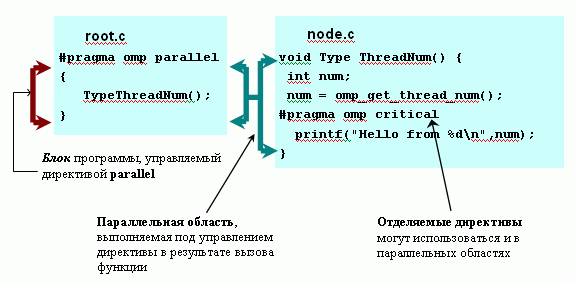
Ряд директив OpenMP допускает использование как непосредственно в блоках директивы, так и в параллельных областях. Такие директивы носят наименование отделяемых директив ( orphaned directives ).
Для более точного понимания излагаемого учебного материала сведем воедино введенные термины и понятия (в скобках даются названия, используемые в стандарте 2.5):
- Параллельный фрагмент ( parallel construct ) - блок программы, управляемый директивой parallel ; именно параллельные фрагменты, совместно с параллельными областями, представляют параллельно-выполняемую часть программы; в предшествующих стандартах для обозначения данного понятия использовался термин лексический контекст ( lexical extent ) директивы parallel.
- Параллельная область ( parallel region ) - параллельно выполняемые участки программного кода, динамически-возникающие в результате вызова функций из параллельных фрагментов - см. рис. 7.3.
- Параллельная секция ( parallel section ) - часть параллельного фрагмента, выделяемая для параллельного выполнения при помощи директивы section - см. подраздел 7.6.
7.2.4. Параметры директивы parallel
Приведем перечень параметров директивы parallel:
- if (scalar_expression)
- private (list)
- shared (list)
- default (shared | none)
- firstprivate (list)
- reduction (operator: list)
- copyin (list)
- num_threads (scalar_expression)
Список параметров приведен только для справки, пояснения по использованию этих параметров будут даны позднее по мере изложения учебного материала.
7.2.5. Определение времени выполнения параллельной программы
Практически сразу после разработки первой параллельной программы появляется необходимость определения времени выполнения вычислений, поскольку в большинстве случаев основной целью использования параллельных вычислительных систем является сокращений времени выполняемых расчетов. Используемые обычно средства для измерения времени работы программ зависят, как правило, от аппаратной платформы, операционной системы, алгоритмического языка и т.п. Стандарт OpenMP включает определение специальных функций для измерения времени, использование которых позволяет устранить зависимость от среды выполнения параллельных программ.
Получение текущего момента времени выполнения программы обеспечивается при помощи функции:
double omp_get_wtime(void),
результат вызова которой есть количество секунд, прошедших от некоторого определенного момента времени в прошлом. Этот момент времени в прошлом, от которого происходит отсчет секунд, может зависеть от среды реализации OpenMP и, тем самым, для ухода от такой зависимости функцию omp_get_wtime следует использовать только для определения длительности выполнения тех или иных фрагментов кода параллельных программ. Возможная схема применения функции omp_get_wtime может состоять в следующем:
double t1, t2, dt; t1 = omp_get_wtime (); … t2 = omp_get_wtime (); dt = t2 - t1;
Точность измерения времени также может зависеть от среды выполнения параллельной программы. Для определения текущего значения точности может быть использована функция:
double omp_get_wtick(void),
позволяющая определить время в секундах между двумя последовательными показателями времени аппаратного таймера используемой компьютерной системы.
7.3. Распределение вычислительной нагрузки между потоками (распараллеливание по данным для циклов)
Как уже отмечалось ранее, программный код блока директивы parallel по умолчанию исполняется всеми потоками. Данный способ может быть полезен, когда нужно выполнить одни и те же действия многократно (как в примере 7.1) или когда один и тот же программный код может быть применен для выполнения обработки разных данных. Последний вариант достаточно широко используется при разработке параллельных алгоритмов и программ и обычно именуется распараллеливанием по данным. В рамках данного подхода в OpenMP наряду с обычным повторением в потоках одного и того же программного кода - как в директиве parallel - можно осуществить разделение итеративно-выполняемых действий в циклах для непосредственного указания, над какими данными должными выполняться соответствующие вычисления. Такая возможность является тем более важной, поскольку во многих случаях именно в циклах выполняется основная часть вычислительно-трудоемких вычислений.
Для распараллеливания циклов в OpenMP применяется директива for:
#pragma omp for [<параметр> ...] <цикл_for>
После этой директивы итерации цикла распределяются между потоками и, как результат, могут быть выполнены параллельно (см. рис. 7.4) - понятно, что такое распараллеливание возможно только, если между итерациями цикла нет информационной зависимости.

Важно отметить, что для распараллеливания цикл for должен иметь некоторый "канонический" тип цикла со счетчиком2Смысл требования "каноничности" состоит в том, чтобы на момент начала выполнения цикла существовала возможность определения числа итераций цикла :
for (index = first; index < end; increment_expr)
Здесь index должен быть целой переменной; на месте знака " < " в выражении для проверки окончания цикла может находиться любая операция сравнения " <= ", " > " или " >= ". Операция изменения переменной цикла должна иметь одну из следующих форм:
- index++, ++index,
- index--, --index,
- index+=incr, index-=incr,
- index=index+incr, index=incr+index,
- index=index-incr
И, конечно же, переменные, используемые в заголовке оператора цикла, не должны изменяться в теле цикла.
В качестве примера использования директивы рассмотрим учебную задачу вычисления суммы элементов для каждой строки прямоугольной матрицы:
#include <omp.h>
#define CHUNK 100
#define NMAX 1000
main () {
int i, j, sum;
float a[NMAX][NMAX];
<инициализация данных>
#pragma omp parallel shared(a) private(i,j,sum)
{
#pragma omp for
for (i=0; i < NMAX; i++) {
sum = 0;
for (j=0; j < NMAX; j++)
sum += a[i][j];
printf ("Сумма элементов строки %d равна %f\n",i,sum);
} /* Завершение параллельного фрагмента */
}
7.2.
Пример распараллеливания цикла
В приведенной программе для директивы parallel появились два параметра - их назначение будет описано в следующем подразделе, здесь же отметим, что параметры директивы shared и private определяют доступность данных в потоках программы - переменные, описанные как shared, являются общими для потоков; для переменных с описанием private создаются отдельные копии для каждого потока, эти локальные копии могут использоваться в потоках независимо друг от друга.
Следует отметить, что если в блоке директивы parallel нет ничего, кроме директивы for, то обе директивы можно объединить в одну, т.е. пример 7.2 может быть переписан в виде:
#include <omp.h>
#define NMAX 1000
main () {
int i, j, sum;
float a[NMAX][NMAX];
<инициализация данных>
#pragma omp parallel for shared(a) private(i,j,sum)
{
for (i=0; i < NMAX; i++) {
sum = 0;
for (j=0; j < NMAX; j++)
sum += a[i][j];
printf ("Сумма элементов строки %d равна %f\n",i,sum);
} /* Завершение параллельного фрагмента */
}
7.3.
Пример использования объединенной директивы parallel for
Параметрами директивы for являются:
- schedule (type [,chunk])
- ordered
- nowait
- private (list)
- shared (list)
- firstprivate (list)
- lastprivate (list)
- reduction (operator: list)
Последние пять параметров директивы будут рассмотрены в следующем подразделе, здесь же приведем описание оставшихся параметров.