|
поддерживаю выше заданые вопросы
|
Спонсор: Intel
Вы можете этот курс.
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 02.10.2012 | Доступ: свободный | Студентов: 1753 / 198 | Длительность: 17:47:00
Специальности: Программист
Теги:
Лекция 7:
Умножение разреженных матриц
Приложение. Моделирование и анализ параллельных вычислений
При разработке параллельных алгоритмов решения сложных научнотехнических задач принципиальным моментом является анализ эффективности использования параллелизма, состоящий обычно в оценке получаемого ускорения процесса вычислений (сокращения времени решения задачи). Формирование подобных оценок ускорения может осуществляться применительно к выбранному вычислительному алгоритму (оценка эффективности распараллеливания конкретного алгоритма). Другой важный подход может состоять в построении оценок максимально возможного ускорения процесса решения задачи конкретного типа (оценка эффективности параллельного способа решения задачи).
В данной главе описывается модель вычислений в виде графа "операции-операнды", которая может использоваться для описания существующих информационных зависимостей в выбираемых алгоритмах решения задач, приводятся оценки эффективности максимально возможного параллелизма, которые могут быть получены в результате анализа имеющихся моделей вычислений. Примеры использования излагаемого теоретического материала приводятся при рассмотрении параллельных алгоритмов в завершающих разделах настоящего учебного материала.
Модель вычислений в виде графа "операции–операнды"
Для описания существующих информационных зависимостей в выбираемых алгоритмах решения задач может быть использована модель в виде графа "операции–операнды" Для уменьшения сложности излагаемого материала при построении модели будет предполагаться, что время выполнения любых вычислительных операций является одинаковым и равняется 1 (в тех или иных единицах измерения). Кроме того, принимается, что передача данных между вычислительными устройствами выполняется мгновенно без какихлибо затрат времени (что может быть справедливо, например, при наличии общей разделяемой памяти в параллельной вычислительной системе).
Представим множество операций, выполняемых в исследуемом алгоритме решения вычислительной задачи, и существующие между операциями информационные зависимости в виде ациклического ориентированного графа

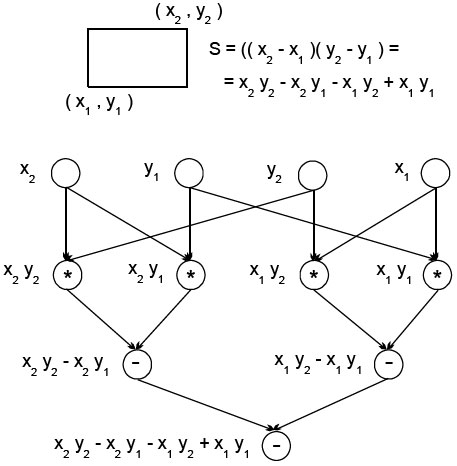
где  есть множество вершин графа, представляющих выполняемые операции алгоритма, а R есть множество дуг графа (при этом дуга
есть множество вершин графа, представляющих выполняемые операции алгоритма, а R есть множество дуг графа (при этом дуга  принадлежит графу только в том случае, если операция j использует результат выполнения операции i). Для примера на рис. p.1 показан граф алгоритма вычисления площади прямоугольника, заданного координатами двух противолежащих углов. Как можно заметить по приведенному примеру, для выполнения выбранного алгоритма решения задачи могут быть использованы разные схемы вычислений и построены соответственно разные вычислительные модели. Как будет показано далее, разные схемы вычислений обладают различными возможностями для распараллеливания и, тем самым, при построении модели вычислений может быть поставлена задача выбора наиболее подходящей для параллельного исполнения вычислительной схемы алгоритма.
принадлежит графу только в том случае, если операция j использует результат выполнения операции i). Для примера на рис. p.1 показан граф алгоритма вычисления площади прямоугольника, заданного координатами двух противолежащих углов. Как можно заметить по приведенному примеру, для выполнения выбранного алгоритма решения задачи могут быть использованы разные схемы вычислений и построены соответственно разные вычислительные модели. Как будет показано далее, разные схемы вычислений обладают различными возможностями для распараллеливания и, тем самым, при построении модели вычислений может быть поставлена задача выбора наиболее подходящей для параллельного исполнения вычислительной схемы алгоритма.
В рассматриваемой вычислительной модели алгоритма вершины без входных дуг могут использоваться для задания операций ввода, а вершины без выходных дуг – для операций вывода. Обозначим через  множество вершин графа без вершин ввода, а через
множество вершин графа без вершин ввода, а через  диаметр (длину максимального пути) графа.
диаметр (длину максимального пути) графа.
Описание схемы параллельного выполнения алгоритма
Операции алгоритма, между которыми нет пути в рамках выбранной схемы вычислений, могут быть выполнены параллельно (для вычислительной схемы на рис. p.1 , например, параллельно могут быть реализованы сначала все операции умножения, а затем первые две операции вычитания). Возможный способ описания параллельного выполнения алгоритма может состоять в следующем.
Пусть p есть количество процессоров, используемых для выполнения алгоритма. Тогда для параллельного выполнения вычислений необходимо задать множество (расписание)

в котором для каждой операции  указывается номер используемого для выполнения операции процессора
указывается номер используемого для выполнения операции процессора 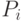 и время начала выполнения операции
и время начала выполнения операции 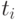 . Для того, чтобы расписание было реализуемым, необходимо выполнение следующих требований при задании множества
. Для того, чтобы расписание было реализуемым, необходимо выполнение следующих требований при задании множества  :
:
-
 , т. е. один и тот же процессор не должен назначаться разным операциям в один и тот же момент времени,
, т. е. один и тот же процессор не должен назначаться разным операциям в один и тот же момент времени, -
 , т. е. к назначаемому моменту выполнения операции все необходимые данные уже должны быть вычислены.
, т. е. к назначаемому моменту выполнения операции все необходимые данные уже должны быть вычислены.
Определение времени выполнения параллельного алгоритма
Вычислительная схема алгоритма G совместно с расписанием может рассматриваться как модель параллельного алгоритма  , исполняемого с использованием p процессоров. Время выполнения параллельного алгоритма определяется максимальным значением времени, используемым в расписании
, исполняемого с использованием p процессоров. Время выполнения параллельного алгоритма определяется максимальным значением времени, используемым в расписании

Для выбранной схемы вычислений желательно использование расписания, обеспечивающего минимальное время исполнения алгоритма

Уменьшение времени выполнения может быть обеспечено и путем подбора наилучшей вычислительной схемы
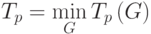
Оценки  ,
, 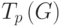 и
и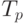 могут быть использованы в качестве показателей времени выполнения параллельного алгоритма. Кроме того, для анализа максимально возможного параллелизма можно определить оценку наиболее быстрого исполнения алгоритма
могут быть использованы в качестве показателей времени выполнения параллельного алгоритма. Кроме того, для анализа максимально возможного параллелизма можно определить оценку наиболее быстрого исполнения алгоритма

Оценку  можно рассматривать как минимально возможное время выполнения параллельного алгоритма при использовании неограниченного количества процессоров (концепция вычислительной системы с бесконечным количеством процессоров, обычно называемой паракомпьютером, широко используется при теоретическом анализе параллельных вычислений).
можно рассматривать как минимально возможное время выполнения параллельного алгоритма при использовании неограниченного количества процессоров (концепция вычислительной системы с бесконечным количеством процессоров, обычно называемой паракомпьютером, широко используется при теоретическом анализе параллельных вычислений).
Оценка 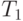 определяет время выполнения алгоритма при использовании одного процессора и представляет, тем самым, время выполнения последовательного варианта алгоритма решения задачи. Построение подобной оценки является важной задачей при анализе параллельных алгоритмов, поскольку она необходима для определения эффекта использования параллелизма (ускорения времени решения задачи). Очевидно, что
определяет время выполнения алгоритма при использовании одного процессора и представляет, тем самым, время выполнения последовательного варианта алгоритма решения задачи. Построение подобной оценки является важной задачей при анализе параллельных алгоритмов, поскольку она необходима для определения эффекта использования параллелизма (ускорения времени решения задачи). Очевидно, что

где  , напомним, есть количество вершин вычислительной схемы G без вершин ввода. Важно отметить, что если при определении оценки ограничиться рассмотрением только одного выбранного алгоритма решения задачи и использовать величину
, напомним, есть количество вершин вычислительной схемы G без вершин ввода. Важно отметить, что если при определении оценки ограничиться рассмотрением только одного выбранного алгоритма решения задачи и использовать величину

то получаемые при использовании такой оценки показатели ускорения будут характеризовать эффективность распараллеливания выбранного алгоритма. Для оценки эффективности параллельного решения исследуемой задачи вычислительной математики время последовательного решения следует определять с учетом различных последовательных алгоритмов, т. е. использовать величину

где операция минимума берется по множеству всех возможных последовательных алгоритмов решения данной задачи.
Приведем без доказательства теоретические положения, характеризующие свойства оценок времени выполнения параллельного алгоритма.
Теорема 1. Минимально возможное время выполнения параллельного алгоритма определяется длиной максимального пути вычислительной схемы алгоритма, т. е.

Теорема 2. Пусть для некоторой вершины вывода в вычислительной схеме алгоритма существует путь из каждой вершины ввода. Кроме того, пусть входная степень вершин схемы (количество входящих дуг) не превышает 2. Тогда минимально возможное время выполнения параллельного алгоритма ограничено снизу значением

где n есть количество вершин ввода в схеме алгоритма.
Теорема 3. При уменьшении числа используемых процессоров время выполнения алгоритма увеличивается пропорционально величине уменьшения количества процессоров, т. е.

Теорема 4. Для любого количества используемых процессоров справедлива следующая верхняя оценка для времени выполнения параллельного алгоритма

Теорема 5. Времени выполнения алгоритма, которое сопоставимо с минимально возможным временем , можно достичь при количестве процессоров порядка  , а именно,
, а именно,

При меньшем количестве процессоров время выполнения алгоритма не может превышать более, чем в 2 раза, наилучшее время вычислений при имеющемся числе процессоров, т. е.
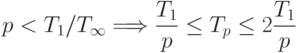
Приведенные утверждения позволяют дать следующие рекомендации по правилам формирования параллельных алгоритмов:
- при выборе вычислительной схемы алгоритма должен использоваться граф с минимально возможным диаметром (см. теорему 1);
- для параллельного выполнения целесообразное количество процессоров определяется величиной
 (см. теорему 5);
(см. теорему 5); - время выполнения параллельного алгоритма ограничивается сверху величинами, приведенными в теоремах 4 и 5.
Для вывода рекомендаций по формированию расписания по параллельному выполнению алгоритма приведем доказательство теоремы 4.
Доказательство теоремы 4. Пусть 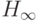 есть расписание для достижения минимально возможного времени выполнения . Для каждой итерации
есть расписание для достижения минимально возможного времени выполнения . Для каждой итерации  ,
,  , выполнения расписания обозначим через
, выполнения расписания обозначим через  количество операций, выполняемых в ходе итерации . Расписание выполнения алгоритма с использованием p процессоров может быть построено следующим образом. Выполнение алгоритма разделим на шагов; на каждом шаге следует выполнить все операций, которые выполнялись на итерации расписания . Выполнение этих операций может быть выполнено не более, чем за
количество операций, выполняемых в ходе итерации . Расписание выполнения алгоритма с использованием p процессоров может быть построено следующим образом. Выполнение алгоритма разделим на шагов; на каждом шаге следует выполнить все операций, которые выполнялись на итерации расписания . Выполнение этих операций может быть выполнено не более, чем за 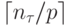 итераций при использовании p процессоров. Как результат, время выполнения алгоритма может быть оценено следующим образом
итераций при использовании p процессоров. Как результат, время выполнения алгоритма может быть оценено следующим образом

Доказательство теоремы дает практический способ построения расписания параллельного алгоритма. Первоначально может быть построено расписание без учета ограниченности числа используемых процессоров (расписание для паракомпьютера). Затем, согласно схеме вывода теоремы, может быть построено расписание для конкретного количества процессоров.
Павел Каширин
|
Скачал архив и незнаю как ничать изучать материал. Видео не воспроизводится (скачено очень много кодеков, различных плееров -- никакого эффекта. Максимум видно часть изображения без звука). При старте ReplayMeeting и Start в браузерах google chrome, ie возникает script error с невнятным описанием. В firefox ситуация еще интереснее. Выводится: Meet Now: Кукаева Светлана Александровна. Meeting Start Time: 09.10.2012, 16:58:04 Downloading... Your Web browser is not configured to play Windows Media audio/video files. Make sure the features are enabled and available.
|