








|
В дисциплине "Основы эконометрики" тест 6 дается по теме 7. |
Опубликован: 10.09.2016 | Доступ: свободный | Студентов: 947 / 166 | Длительность: 15:27:00
Тема: Экономика
Специальности: Менеджер, Руководитель, Экономист, Бухгалтер
Лекция 3:
Множественная регрессия
3.8. Процедура шаговой регрессии
Частный 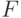 -критерий, предназначенный для включения фактора в модель, позволяет сравнить прирост факторной дисперсии за счет дополнительно включенного фактора с остаточной дисперсией, приходящейся на одну степень свободы по регрессионной модели в целом,
-критерий, предназначенный для включения фактора в модель, позволяет сравнить прирост факторной дисперсии за счет дополнительно включенного фактора с остаточной дисперсией, приходящейся на одну степень свободы по регрессионной модели в целом,
где  -
-  - доля вариации
- доля вариации  , объясненная регрессией за счет введения фактора
, объясненная регрессией за счет введения фактора  ;
;
- доля остаточной вариации модели, включающей полный набор факторов.
Если числитель и знаменатель формулы (3.34) умножить на  , то получим отношение не долей, а отношение прироста факторной объясняющей суммы квадратов отклонений к остаточной сумме квадратов. Так как прирост факторной суммы квадратов обусловлен включением в модель одного фактора, число степеней свободы для него равно
, то получим отношение не долей, а отношение прироста факторной объясняющей суммы квадратов отклонений к остаточной сумме квадратов. Так как прирост факторной суммы квадратов обусловлен включением в модель одного фактора, число степеней свободы для него равно  .
.
Для остаточной суммы квадратов  . Фактическое значение частного -критерия сравнивается с табличным при некотором уровне значимости
. Фактическое значение частного -критерия сравнивается с табличным при некотором уровне значимости  . Если наблюдаемый -критерий превышает табличное значение, то фактор признают значимым и оставляют в модели, если наблюдаемый -критерий меньше табличного, то фактор признается незначимым и принимается гипотеза
. Если наблюдаемый -критерий превышает табличное значение, то фактор признают значимым и оставляют в модели, если наблюдаемый -критерий меньше табличного, то фактор признается незначимым и принимается гипотеза  .
.
Аналогичную процедуру можно применять и для усложнения модели путем решения вопроса о включении в нее нового фактора. В пакетах прикладных программ, например в пакете STATISTICA, реализованы как процедура включения, так и процедура исключения фактора из модели. Критические значения критериев для включения и исключения факторов 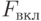 и
и  пользователь определяет самостоятельно.
пользователь определяет самостоятельно.
В методе исключения анализ начинается с включения в регрессионную модель всех переменных. Затем для каждой переменной вычисляют частную -статистику и ту переменную, для которой -статистика минимальна, исключают из рассмотрения. Затем строят новую модель по оставшимся переменным и после вычисления частных -статистик вновь удаляют одну из переменных. И так до тех пор, пока не будет достигнуто заранее заданное число переменных в модели или все -статистики не станут больше заданного порога.
В методе включения начинают с построения модели, включающей лишь одну переменную, имеющую наибольший по абсолютной величине парный коэффициент корреляции с переменной выхода. Затем вычисляют частные -статистики для всех оставшихся переменных и включают в модель переменную с наибольшей -статистикой. Это эквивалентно включению переменной, имеющей наибольший частный коэффициент корреляции с переменной выхода. Процесс продолжают до тех пор, пока в модели не наберется определенное число переменных или -статистики не станут меньше заданного порога.
Более сложной процедурой является комбинация методов включения и исключения. Выбирают фиксированные пороговые уровни  и и на каждом шаге рассматривают возможности добавить переменную, исключить переменную, заменить одну переменную другой, остановить процесс. На каждом шаге вычисляются -статистики переменных, величина
и и на каждом шаге рассматривают возможности добавить переменную, исключить переменную, заменить одну переменную другой, остановить процесс. На каждом шаге вычисляются -статистики переменных, величина 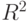 и степень допустимой коррелированности переменных, вошедших в регрессионное уравнение. Последняя определяется по формуле
и степень допустимой коррелированности переменных, вошедших в регрессионное уравнение. Последняя определяется по формуле  . Обычно задают уровень допуска -
. Обычно задают уровень допуска - , а и подбирают в ходе решения задачи. Переменную с максимальным значением включают в модель при условии, что значения
, а и подбирают в ходе решения задачи. Переменную с максимальным значением включают в модель при условии, что значения не превышают
не превышают (степень коррелированности системы не должна быть слишком большой), но при этом
(степень коррелированности системы не должна быть слишком большой), но при этом  . Если оказывается, что
. Если оказывается, что 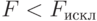 , то переменную исключают из модели.
, то переменную исключают из модели.
Преимуществами шаговых методов являются простота алгоритмов, автоматизация выбора наилучшей модели, быстрота вычислений; недостатком - раздельный анализ переменных (по отдельности переменные могут не являться значимыми, но их совместное использование может улучшить показатели регрессионной модели).
Другой способ пошагового отбора факторов состоит в использовании скорректированного коэффициента детерминации, определяемого по формуле
В отличие от обычного коэффициента детерминации , который всегда увеличивается при добавлении новых факторов, скорректированный коэффициент детерминации может уменьшаться при добавлении новых переменных, не оказывающих существенного влияния на выходную переменную . Однако даже увеличение скорректированного коэффициента детерминации не всегда означает, что вводимый в модель фактор значим. Поэтому описанный выше метод шаговой регрессии, основанный на использовании и , предпочтительнее.
Рассмотрим пример. В таблице 3.2 представлены данные для исследования зависимости урожайности семян люцерны от следующих факторов:
-
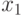 - количество осадков в период сентябрь - 20 апреля (мл);
- количество осадков в период сентябрь - 20 апреля (мл); -
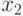 - количество осадков в период 20 апреля - 20 мая (мл);
- количество осадков в период 20 апреля - 20 мая (мл); -
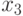 - температура воздуха в фазе цветения (°С);
- температура воздуха в фазе цветения (°С); -
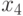 - относительная влажность воздуха в фазе цветения (%);
- относительная влажность воздуха в фазе цветения (%); -
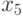 - количество осадков в фазе цветения (мл);
- количество осадков в фазе цветения (мл); -
 - температура почвы на глубине 20 см 20 мая (°С);
- температура почвы на глубине 20 см 20 мая (°С); -
 - высота растения 20 мая (мм).
- высота растения 20 мая (мм).
Представленные данные получены в результате 12 опытов, проведенных в 1986-1989 гг. в учебном хозяйстве "Березовский" Воронежского аграрного университета.
| Номер опыта | |
|
|
|
|
|
|
| 1 | 282 | 30 | 17,3 | 65,3 | 65,4 | 20 | 50 |
| 2 | 326 | 80 | 20,2 | 61,0 | 43,0 | 17 | 80 |
| 3 | 374 | 76 | 18,9 | 73,0 | 131,6 | 17 | 46 |
| 4 | 374 | 109 | 18,8 | 66,0 | 55,1 | 17 | 40 |
| 5 | 424 | 104 | 18,1 | 72,0 | 171,9 | 11 | 84 |
| 6 | 522 | 99 | 22,0 | 62,1 | 46,6 | 14 | 61 |
| 7 | 212 | 30 | 19,0 | 73,2 | 95,7 | 20 | 50 |
| 8 | 411 | 50 | 17,3 | 66,3 | 119,7 | 14 | 52 |
| 9 | 164 | 30 | 17,3 | 65,3 | 65,4 | 20 | 50 |
| 10 | 411 | 50 | 17,3 | 66,3 | 149,1 | 14 | 52 |
| 11 | 438 | 102 | 18,0 | 69,3 | 63,0 | 21 | 65 |
| 12 | 364 | 69 | 22,0 | 76,0 | 219,0 | 12 | 70 |
С целью выбора наилучшего варианта набора переменных применим комбинированный вариант включения и исключения неизвестных в процедуре шаговой регрессии, реализованный в модуле "Множественная регрессия" пакета STATISTICA.
Дополним наше множество следующими переменными:

Матрицу данных зададим в табл. 3.3.
Таблица 3.3
Рассчитаем частные коэффициенты корреляции (Partial Correlations) и значения частной -статистики ( ) на каждом шаге регрессии. Всего было задано пять шагов регрессии при
) на каждом шаге регрессии. Всего было задано пять шагов регрессии при  и
и  . Результаты расчетов представлены в табл. 3.4-3.6.
. Результаты расчетов представлены в табл. 3.4-3.6.
Таблица 3.4
Таблица 3.5
Таблица 3.6
Результаты расчетов показывают, что хотя некоторые переменные  имеют незначимые уровни значимости (
имеют незначимые уровни значимости ( ), их желательно оставить в уравнении регрессии, так как при их включении прирост коэффициента детерминации
), их желательно оставить в уравнении регрессии, так как при их включении прирост коэффициента детерминации  составил 0,193364, т.е. 20% всего возможного диапазона изменения .
составил 0,193364, т.е. 20% всего возможного диапазона изменения .
Выпишем полученное уравнение, сначала используя исходные переменные:
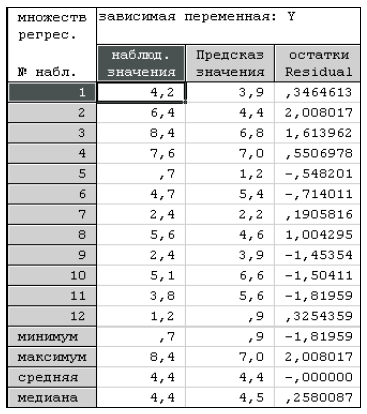
Составим таблицу наблюдаемых, расчетных значений и остатков урожайности семян люцерны (табл. 3.7).
Качество предсказания получилось посредственное: средняя абсолютная ошибка предсказания равна 1,0; средняя относительная ошибка равна почти 30%.
Рассмотрим вопрос о ранжировании факторов по силе их влияния на формирование урожая. Для этого необходимо переписать уравнение (3.36) через стандартизированные факторы вида  .
.
Таблица 3.7
Кроме того, следует отметить, что в пакете STATISTICA коэффициенты модели со стандартизированными факторами приводятся в графе BETA таблицы REGRESSION SUMMARY (см. табл. 3.6). Стандартизированный коэффициент регрессии 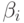 показывает, на сколько величин
показывает, на сколько величин  изменится в среднем зависимая переменная y при увеличении переменной на
изменится в среднем зависимая переменная y при увеличении переменной на  . Имеем
. Имеем
Из свойств уравнения в стандартизированных переменных заключаем, что наибольшее влияние на выходную переменную при изменении каждого фактора 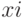 на величину окажет фактор в отдельности и в сочетании факторов
на величину окажет фактор в отдельности и в сочетании факторов  . Следующий по силе влияния - фактор , затем фактор
. Следующий по силе влияния - фактор , затем фактор  и, наконец, фактор .
и, наконец, фактор .
По уравнению (3.37) можно ранжировать факторы по силе влияния на . Количественно сравнить силу этого влияния можно, используя коэффициенты эластичности модели  . Коэффициенты эластичности показывают, на сколько процентов от среднего значения изменится зависимая переменная при увеличении переменной на 1%. Вычислим коэффициенты эластичности каждого фактора. Для этого вычислим в модуле Basic Statistic пакета STATISTICA средние факторов и зависимой переменной y (табл. 3.8).
. Коэффициенты эластичности показывают, на сколько процентов от среднего значения изменится зависимая переменная при увеличении переменной на 1%. Вычислим коэффициенты эластичности каждого фактора. Для этого вычислим в модуле Basic Statistic пакета STATISTICA средние факторов и зависимой переменной y (табл. 3.8).
| Факторы | Средние | Факторы | Средние |
|
358,50 |  |
26 806,33 |
|
69,08 |  |
1 321,17 |
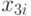 |
18,85 | 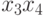 |
1 282,14 |
|
67,98 | 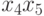 |
7 126,24 |
|
102,13 | |
1 557,70 |
|
16,42 |  |
938,42 |
|
58,33 | |
4,37 |
Отсюда: