

|
Добрый день можно поинтересоваться где брать литературу предложенную в курсе ?Большинство книг я не могу найти в известных источниках |
Московский государственный университет путей сообщения
Опубликован: 06.09.2012 | Доступ: свободный | Студентов: 1233 / 168 | Оценка: 5.00 / 5.00 | Длительность: 35:22:00
Темы: САПР, Аппаратное обеспечение
Специальности: Разработчик аппаратуры
Теги:
Лекция 15:
Приближенные методы моделирования неисправностей
15.2 Статистический анализ неисправностей.
Статистический метод STAFAN [15.4,15.5] позволяет получить оценку полноты тестовой последовательности без моделирования всех неисправностей. Он использует данные, полученные при логическом моделировании исправной схемы, и позволяет приблизительно найти вероятность обнаружения неисправностей. В течение моделирования собирается статистика данных моделирования на внутренних линиях схемы. Для каждой линии схемы вычисляются следующие характеристики:
-
 - управляемость линии
- управляемость линии  , т. е. вероятность появления на этой линии единицы на случайно выбранном входном наборе;
, т. е. вероятность появления на этой линии единицы на случайно выбранном входном наборе;
-
 - 0-управляемость линии , вероятность появления на линии значения 0 на случайно выбранном входном наборе;
- 0-управляемость линии , вероятность появления на линии значения 0 на случайно выбранном входном наборе;
-
 - 1-наблюдаемость линии , вероятность наблюдения линии
на внешнем выходе схемы при значении
- 1-наблюдаемость линии , вероятность наблюдения линии
на внешнем выходе схемы при значении  (фактически условная вероятность активизации пути от линии
до внешнего выхода схемы при );
(фактически условная вероятность активизации пути от линии
до внешнего выхода схемы при );
-
 - 0-наблюдаемость линии ,
вероятность активизации пути от линии до внешнего выхода линии схемы при
- 0-наблюдаемость линии ,
вероятность активизации пути от линии до внешнего выхода линии схемы при  .
.
Для каждой линии схемы определим два счетчика. Первый 0-счетчик предназначен для подсчета нулевых значений на данной линии в процессе моделирования и 1-счетчик для подсчета единичных значений. Когда в процессе моделирования данная линия принимает значение 0 (1) , то ее 0 (1) -счетчик увеличивается на единицу. Если значение сигнала на линии неопределенное  , то счетчики не изменяются. Если на линии получается значение, соответствующее высокому импедансу, то обычно увеличивается значение того счетчика, чье значение изменялось в последний раз.
, то счетчики не изменяются. Если на линии получается значение, соответствующее высокому импедансу, то обычно увеличивается значение того счетчика, чье значение изменялось в последний раз.
После логического моделирования исправной схемы на  входных наборах значения 1-управляемости и 0-управляемости можно определить следующим образом:
входных наборах значения 1-управляемости и 0-управляемости можно определить следующим образом:
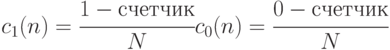
Фактически 0-управляемость характеризует частоту (вероятность) установки данной линии схемы в нулевое значение, а 1-управляемость соответственно в единичное.
Для вычисления наблюдаемости определим для каждого входа логического вентиля дополнительно свой счетчик активизации. Этот счетчик увеличивается на 1, если на данном наборе этот вход активизируется до выхода своего вентиля.
После моделирования на входных наборах вероятность активизации входа до выхода вентиля можно оценить следующим образом

В начале моделирования значения наблюдаемости полагаются равными  . для всех внешних выходов схемы. Значения наблюдаемости остальных линии схемы последовательно вычисляются, двигаясь от выходов схемы к ее входам, с помощью специальных формул. Рассмотрим их на примере вентиля И с распределением сигналов, показанным на рис.15.3.
. для всех внешних выходов схемы. Значения наблюдаемости остальных линии схемы последовательно вычисляются, двигаясь от выходов схемы к ее входам, с помощью специальных формул. Рассмотрим их на примере вентиля И с распределением сигналов, показанным на рис.15.3.
Проблема состоит в том, как по данному значению 1-наблюдаемости  выхода вентиля И получить 1-наблюдаемость его входа . Для этого используем формулу Байеса:
выхода вентиля И получить 1-наблюдаемость его входа . Для этого используем формулу Байеса:
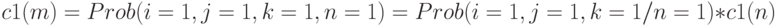
Из этого выражения получаем:
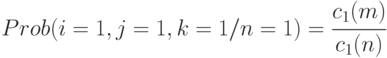
Поэтому:
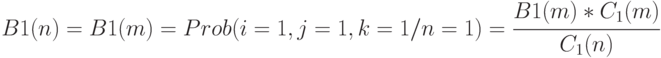
Из полученной формулы видно, что 1-наблюдаемость вычисляется на основании значения 1-наблюдаемости выхода элемента и значений 1-управляемости этого входа и выхода.
Далее найдем выражение для расчета 0-наблюдаемости этого же вентиля И.
Поскольку  - вероятность активизации входа , то
- вероятность активизации входа , то
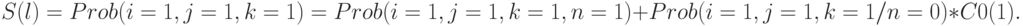
Отсюда следует:
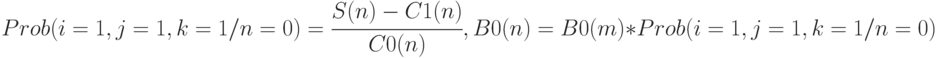
Окончательно получаем следующую формулу для вычисления 0-наблюдаемости.
![B0(n)=B0(m)\left [\cfrac{S(n)-C1(m)}{C0(n)}\right ]](/sites/default/files/tex_cache/b9b242096fabb79f2658ffbfdd35227a.png)
Таким образом, 0-наблюдаемость входа вычисляется, исходя из значений 0-наблюдаемости выхода 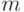 , значения счетчика активизации этого входа и двух значений управляемости
, значения счетчика активизации этого входа и двух значений управляемости 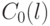 и
и  (0-управляемость и 1-управляемость выхода).
(0-управляемость и 1-управляемость выхода).
Аналогично можно получить формулы вычисления 0-, 1- наблюдаемости для:
![B1(n)=B_1(m) \left [\cfrac{S(l)-C0(m)}{C1(l)} \right ],\\
B0(n)=B_0(m) \cdot C0(m) / C1(n),](/sites/default/files/tex_cache/10e5d971589c10f8bcede9bdd8496c33.png)
![B1(n)=B0(m)\cdot C0(m) / C1(n),\\
B0(l)=B1(m)\left [\cfrac{S(l)-C0(m)}{C0(n)} \right ],](/sites/default/files/tex_cache/e7a419a1a2a639fccaaa1b9008bfa442.png)
![B1(n)=B0(m)\left [\cfrac{S(n)-C1(m)}{C1(n)} \right ], \\
B0(n)=B1(m)\cdot C1(m) / C0(n),](/sites/default/files/tex_cache/8399caeb5418276f0ad8288131965a50.png)
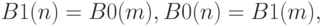
Кроме вентилей при вычислении наблюдаемости мы должны обрабатывать также узлы разветвления, которые показаны на рис. 15.4.
При этом известны значения 0- (1-) наблюдаемости на ветвях разветвления 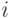 ,
, 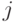 . Требуется определить значение 0- (1-) наблюдаемости в узле . Очевидно, так как линия может наблюдаться только через линии , , то:
. Требуется определить значение 0- (1-) наблюдаемости в узле . Очевидно, так как линия может наблюдаться только через линии , , то:
 ,
,
 и
и
![B1(n)>=max[B1(i),B1(j)]](/sites/default/files/tex_cache/9187cd8db068467175f7d96788d6ac5b.png) .
.
Если пути наблюдения линии через линии и независимы, то:
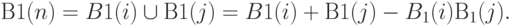
В общем виде имеет место следующая оценка
![max{[B_1(i);B_1(j)]}\le B_1(l)\le\bigcup\limits_{k=i,j}{B_1(i_k)}](/sites/default/files/tex_cache/2462054426766ff972d310c3c78006ad.png)
Для многих ветвей разветвлении эта оценка имеет следующий вид
![max{[B_1(i_k)]}\le B_1(l)\le\bigcup\limits_{k=1}^m{B_1(i_k)}](/sites/default/files/tex_cache/f0ff75a1e70367c055a5202e3a55a3c0.png)
На практике для вычисления значения узла разветвления чаще пользуются приближенной формулой, где вводится коэффициент  ,
который для каждого вида схем определяется экспериментально
,
который для каждого вида схем определяется экспериментально
![B_1(n)=(1-\alpha)max[B_1(j_k)]+\alpha[\bigcup\limits_{k=1}^{m}{B_1(j_k)}]](/sites/default/files/tex_cache/cfb0fcab1f8c14642a447230e882ac25.png)
Здесь  обозначает ветвь разветвления узла . При
обозначает ветвь разветвления узла . При  значение
значение  наблюдается независимо через каждую ветвь разветвления и поэтому наблюдаемость определяется суммой значений наблюдаемости этих ветвей. При
наблюдается независимо через каждую ветвь разветвления и поэтому наблюдаемость определяется суммой значений наблюдаемости этих ветвей. При  значение
значение  наблюдается сходящиеся ветви разветвления и поэтому значение , по крайней мере, не меньше максимального значения наблюдаемости отдельной ветви.
наблюдается сходящиеся ветви разветвления и поэтому значение , по крайней мере, не меньше максимального значения наблюдаемости отдельной ветви.
До сих пор мы неявно предполагали, что обрабатываются комбинационные схемы. В последовательностных схемах при вычислении наблюдаемости есть проблемы с обработкой линий обратной связи. Они могут быть решены с применением полученных расчетных формул, но требуют дополнительных усилий [15.4,15.5].
Далее рассмотрим оценку вероятности обнаружения неисправности. Для проверки одиночной константной неисправности 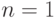 надо подать на эту линию значение 0 и обеспечить распространение влияния неисправности до внешнего выхода схемы. Поэтому вероятность проверки константной неисправности
надо подать на эту линию значение 0 и обеспечить распространение влияния неисправности до внешнего выхода схемы. Поэтому вероятность проверки константной неисправности  можно оценить с помощью совместной вероятности установки линии в 0 и наблюдения на внешнем выходе:
можно оценить с помощью совместной вероятности установки линии в 0 и наблюдения на внешнем выходе:
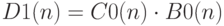
Аналогично для констатной неисправности  вероятность ее проверки можно оценить с помощью
вероятность ее проверки можно оценить с помощью
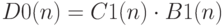
Таким образом можно найти для каждой неисправности ее вероятность обнаружения на данном одном тестовом наборе. Далее необходимо оценить вероятность обнаружения неисправности на всех 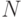 наборах проверяющего теста. Пусть
наборах проверяющего теста. Пусть 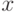 обозначает вероятность проверки данной неисправности на одном тестовом наборе (определяется
обозначает вероятность проверки данной неисправности на одном тестовом наборе (определяется  или
или  в зависимости от типа неисправности). Тогда вероятности проверки этой неисправности на тестовой последовательности из входных наборов можно оценить по известной формуле:
в зависимости от типа неисправности). Тогда вероятности проверки этой неисправности на тестовой последовательности из входных наборов можно оценить по известной формуле:
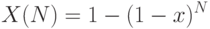
(вероятность равна 1 минус вероятность не обнаружения этой неисправности любым из входных наборов. Поскольку число наборов конечно, то случайные ошибки дают смещенную оценку проверки неисправности. Поэтому второе слагаемое приведенной формулы необходимо разделить на корректирующий фактор:

Здесь 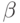 - коэффициент пропорциональности, который определяется эмпирически. С учетом корректирующего фактора вероятность проверки неисправности
- коэффициент пропорциональности, который определяется эмпирически. С учетом корректирующего фактора вероятность проверки неисправности  тестовой последовательностью , содержащей входных наборов, определяется следующим выражением:
тестовой последовательностью , содержащей входных наборов, определяется следующим выражением:
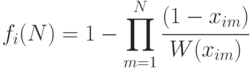
Если вероятность проверки каждой неисправности на наборах известна, то интегральная полнота для всех 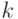 неисправностей и тестовых наборов можно определить следующей формулой
неисправностей и тестовых наборов можно определить следующей формулой
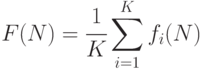
Анализ этой процедуры показывает, что она имеет линейную сложность, т.е. сложность пропорциональна , в отличие от предыдущих, со сложностью пропорциональной  . Этот метод является приближенным. Авторы данного метода провели экспериментальное сравнение с результатами детерминированного моделирования неисправностей [15.5] схемы 64-разрядного АЛУ с 4376 неисправностями.
Проверяющий тест из 155 наборов согласно данным детерминированного моделирования с неисправностями дал полноту проверки неисправностей 75.09%. Затем было проведено статистическое моделирование неисправностей, по результатам которого неисправности ранжированы по значениям вероятности проверки. Исходя из полноты 75.09% 3286 неисправностей, имеющих большие значения вероятности проверки считались обнаруженными, а оставшиеся 1090 неисправностей признаны непроверенными.
Из этих 1090 неисправностей 1036 неисправностей не проверялись и детерминированном моделировании. Из3286 неисправностей, проверяемых по данным STAFAN, все, кроме 46 неисправностей, проверялись и детерминированным методом. В експериментах использовались следующие значения параметров: (независимые пути разветвления) и
. Этот метод является приближенным. Авторы данного метода провели экспериментальное сравнение с результатами детерминированного моделирования неисправностей [15.5] схемы 64-разрядного АЛУ с 4376 неисправностями.
Проверяющий тест из 155 наборов согласно данным детерминированного моделирования с неисправностями дал полноту проверки неисправностей 75.09%. Затем было проведено статистическое моделирование неисправностей, по результатам которого неисправности ранжированы по значениям вероятности проверки. Исходя из полноты 75.09% 3286 неисправностей, имеющих большие значения вероятности проверки считались обнаруженными, а оставшиеся 1090 неисправностей признаны непроверенными.
Из этих 1090 неисправностей 1036 неисправностей не проверялись и детерминированном моделировании. Из3286 неисправностей, проверяемых по данным STAFAN, все, кроме 46 неисправностей, проверялись и детерминированным методом. В експериментах использовались следующие значения параметров: (независимые пути разветвления) и  , которые дали хорошое совпадение с данными детерминированного моделирования.
, которые дали хорошое совпадение с данными детерминированного моделирования.
Дмитрий Медведевских