Теория языков
Эквивалентность праволинейных грамматик и конечных автоматов
Как упоминалось выше, любой конечно-автоматный язык может быть определен праволинейной грамматикой, и наоборот, так что классы языков, определяемых этими формализмами, эквивалентны. Так, для конструирования праволинейной грамматики, соответствующей данному конечному автомату, достаточно включить в грамматику правила вида 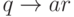 для всех переходов вида
для всех переходов вида  и правила вида
и правила вида 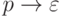 для всех заключительных состояний
для всех заключительных состояний  .
.
Таким образом, класс языков, задаваемых праволинейными грамматиками, очень удобен в задачах компиляции, т.к. ему соответствует простой распознаватель (конечные автоматы), для которого алгоритмически разрешимы такие проблемы, как эквивалентность двух языков, пустота определяемого языка и проверка входной цепочки на принадлежность данному языку. Многие "локальные" свойства языков программирования, такие как константы, слова языка и строки, могут быть определены с помощью праволинейных грамматик - например, в следующей лекции мы покажем как этот формализм может быть использован в задачах лексического анализа.
Однако, класс языков, задаваемых праволинейными грамматиками, слишком узок для описания многих свойств современных языков программирования. Например, в большинстве языков программирования возникает потребность в согласовании подобных скобок и разделителей, таких, как begin-end, (), [], {}. Можно промоделировать подобное согласование с помощью "правильного скобочного языка", в котором алфавит состоит из символов ' ( ' и ' ) ', а количество открывающих скобок совпадает с количеством закрывающих и число закрывающих скобок никогда не превышает число встреченных открывающих скобок. Можно показать, что не существует праволинейной грамматики, описывающий данный язык, но зато его легко записать с помощью следующей контекстно-свободной грамматики:  .
.
По этой причине контекстно-свободные грамматики получили значительно большее распространение в компиляции. С их помощью можно задать очень большую часть синтаксиса языков программирования.
Свойства контекстно-свободных грамматик
Весь процесс синтаксическо анализа можно упрощенно рассматривать как определение принадлежности входной цепочки заданной контекстно-свободной грамматике (в дальнейшем, мы будем использовать сокрещение "КС-грамматика"). Однако надо оговориться, что такая формулировка сильно упрощена, так как процесс вывода цепочки по грамматике нетривиален и к тому же усложняется тем фактом, что далеко не все свойства языков программирования могут быть описаны КС-грамматиками.
Кроме того, КС-грамматики зачастую страдают от проблемы неоднозначности. Грамматика называется неоднозначной (ambiguous grammar) , если существует, по крайней мере, одна выводимая в этой грамматике цепочка, для которой существует более одного вывода. Например, можно рассмотреть язык G0, описывающий простые арифметические выражения со сложением и умножением, и задаваемый КС-грамматикой следующим набором правил:  . Эта грамматика неоднозначна, так как в ней существует два различных вывода для выражения вида a+a+a или a*a+a (левосторонний и правосторонний вывод).
. Эта грамматика неоднозначна, так как в ней существует два различных вывода для выражения вида a+a+a или a*a+a (левосторонний и правосторонний вывод).
В данном случае проблему неоднозначности можно решить путем преобразования грамматики к эквивалентной грамматике  .
Но и у этой грамматики есть серьезный недостаток: операции + и * имеют один и тот же приоритет, и потому выражение a+a*a будет трактоваться как (a+a)*a . Для того, чтобы получить правильный приоритет операций, необходимо продолжить преобразование грамматик и перейти к следующему набору правил:
.
Но и у этой грамматики есть серьезный недостаток: операции + и * имеют один и тот же приоритет, и потому выражение a+a*a будет трактоваться как (a+a)*a . Для того, чтобы получить правильный приоритет операций, необходимо продолжить преобразование грамматик и перейти к следующему набору правил: 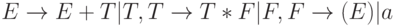 . Более подробно проблемы, связанные с неоднозначными грамматиками, будут рассмотрены в
"Грамматики и YACC"
.
. Более подробно проблемы, связанные с неоднозначными грамматиками, будут рассмотрены в
"Грамматики и YACC"
.
О преобразовании грамматик
Как мы уже видели в предыдущем примере, иногда может возникнуть потребность в преобразовании КС-грамматик.
К сожалению, не существует общего алгоритмического метода приведения КС-грамматик к произвольному виду, как не существует и алгоритма, определяющего равенство языков, задаваемых двумя КС-грамматиками. Однако известен целый ряд преобразований, таких как устранение бесполезных символов и устранение цепных правил, которые позволяют привести грамматику к более удобной форме.
Кроме того, известно, что любая КС-грамматика может быть приведена к нормальному виду Хомского , в котором все правила имеют один из следующих видов:
-
 , где А , B и C - нетерминалы
, где А , B и C - нетерминалы -
 , где a - терминал
, где a - терминал -
 , при условии, что символ
, при условии, что символ  принадлежит языку, а нетерминал S не встречается в правых частях правил
принадлежит языку, а нетерминал S не встречается в правых частях правил
Другим широко распространенным стандартным видом КС-грамматик является нормальная форма Грейбах , в которой все правые части правил начинаются с терминалов.
Перейдем к рассмотрению класса распознавателей, соответствующих классу языков, задаваемых КС-грамматиками - к магазинным автоматам.