Optimizing compiler. Auto parallelization
Admissibility of auto parallelization
Auto parallelization is a loop permutation optimization.
Initial order of instruction execution becomes unspecified.
A necessary conditions for its applicability are:
- Loop is identified and its class match the requirements
- The absence of dependencies within the loop
- Heuristic model considers parallelization as profitable
/Qpar-report{0|1|2|3} control the auto-parallelizer diagnostic level
/Qpar-report3 option informs if the compiler parallelizes or doesn’t parallelize a loop, including reports which problem prevents auto parallelization. For example:
- par.c(11): (col. 1) remark: LOOP WAS AUTO-PARALLELIZED
- par.c(101): (col. 3) remark: loop was not parallelized: existence of parallel dependence.
- par.c(27) (col. 1): remark: loop was not parallelized: insufficient computational work.
- par.c(34): (col. 3) remark: loop was not parallelized: insufficient inner loop.
- par.c(77): (col. 1) remark: DISTRIBUTED LOOP WAS AUTO-PARALLELIZED.
- par.c(133): (col. 1) remark: FUSED LOOP WAS AUTO-PARALLELIZED.
- Loop identification
- Loop optimization can be performed only for loops with a certain number of iterations with successively changing iteration variables that have no hits outside of the loop and calls the unknown functions.
- recommendations
- Use -Qpar_report3 to identify a problem. The absence of loop in the report or unsupported loop structure is the reason for the following steps:
- Avoid loops with an uncertain number of iterations, the conversion outside the loop, unknown functions calls
- Interprocedural analysis can help with additional information. (-Qipo )
- Use -ansi-alias for C/C++
- Use "restrict" attribute inside C/C++ code (-Qstd = c99)
- Dependencies
- One of hardest problems for compiler is resolving the memory disambiguation task or performing the alias analysis.
- The compiler assumptions are conservative. It means that different location of memory objects must be proved, they assumed as aliased by default.
- recommendations:
- Use -Qpar_report3 to identify a problem.
- Use -ansi-alias for C/C++
- Use attribute to restrict inside C/C++ code (-Qstd=c99)
int sub (int *a, float *b, int n) => int sub (int *restrict a, float *restrict b, int n)
- -Qipo
- Directives #pragma ivdep
- The ivdep pragma tells the compiler to ignore assumed vector dependencies.
- Profitability of auto parallelization
- /Qpar_report3: loop was not parallelized: insufficient computational work.
- To estimate optimization profit is a difficult task. There are performance effects that are difficult to predict at compile time. Number of loop iteration can be unknown.
- For instance, unknown probability of branches inside the loop can lead to wrong work estimation.
- recommendations:
- Use compiler parallelization directives
# pragma parallel, # pragma parallel always, # pragma noparallel
-
Compiler Options
- / Qpar-threshold [n] threshold for avtoparallelizatsii from 0 to 100
- / Qpar-runtime-control [n] the level of generating run-time checks from 0 to 3
- / Qpar-num-threads = <n> installation of various numbers of threads
- Use –O3 . Some loop optimizations can make loops more profitable for parallelization. (fusion, distribution)
- -Qprof_gen/-Qprof_use Compile with profiling could open more optimizations
- Use compiler parallelization directives
Automatic parallelization is done using the OpenMP interface. OpenMP (Open Multi-Processing) is a software interface that supports multi-platform programming for multiprocessor computation systems with shared memory on C/C++ and Fortran.
The number of used threads is defined by the environment variable OMP_NUM_THREADS and can be modified before application launch (by default application will use all available cores)


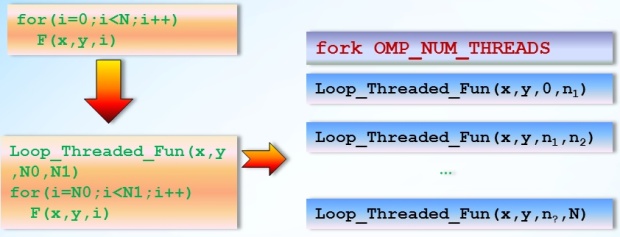
Loop parallelization looks like creating a function taking all used objects and loop iteration space part as arguments.
The multiple instances of loop thread function are executed in different streams with different values of the boundaries. Iterative loop space is divided into several parts and each is given to the separate thread.
Optimizing compiler is able to create several versions of code by adding some run-time checks to resolve dependences issues, to make estimation of loop iterations, etc.
/Qpar-runtime-control[n]
Control parallelizer to generate runtime check code for effective automatic parallelization.
- n=0 no runtime check based auto-parallelization
- n=1 generate runtime check code under conservative mode (DEFAULT when enabled)
- n=2 generate runtime check code under heuristic mode
- n=3 generate runtime check code under aggressive mode
Interaction with other loop optimizations
An optimizing compiler makes loop parallelization together with other optimizations. Because thread creation has its price it is more profitable to has large loops for processing. So order of optimizations canbe:
- Loop fusion (creation of large loops).
- Loop interchange and other loop optimizations for improving memory access.
- Auto parallelization.
- Loop optimizations in the threaded functions in accordance with the usual considerations. (loop distribution, loop unrolling, auto vectorization, etc.).
These considerations can be used during creating a program design to simplify following threadization with usage of compiler autoparallelization or OPENMP directives.