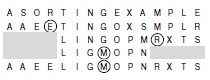

|
Здравствуйте прошла курсы на тему Алгоритмы С++. Но не пришел сертификат и не доступен.Где и как можно его скаачат? |
Опубликован: 05.01.2015 | Доступ: свободный | Студентов: 2178 / 0 | Длительность: 63:16:00
Специальности: Программист, Системный архитектор, Тестировщик, Архитектор программного обеспечения
Лекция 7:
Быстрая сортировка
Выборка
Одним из важных приложений, связанных с сортировкой, но не требующим полной упорядоченности, является операция нахождения медианы некоторого множества чисел. В статистических, а также в других приложениях обработки данных, это весьма распространенный вид вычислений. Один из способов решения этой задачи заключается в том, что числа упорядочиваются, и выбирается число из середины, но можно сделать лучше, воспользовавшись процессом разбиения быстрой сортировки.
Операция нахождения медианы представляет собой частный случай операции выборки (selection): нахождения к-го наименьшего числа из некоторого множества чисел. (Не спутайте эту выборку со случайной выборкой (sample), введенной в разделе 7.5 - прим. перев.) Поскольку алгоритм не может гарантировать, что конкретный элемент является к-ым наименьшим, без проверки к - 1 меньших элементов и N - к больших элементов, большинство алгоритмов выборки может возвратить все к наименьших элементов файла без существенных дополнительных вычислений.
Выборки часто применяются при обработке экспериментальных и других данных. Широко практикуется использование медианы и других характеристик положения (order statistics) для деления файла на меньшие группы. Нередко для дальнейшей обработки нужно сохранить лишь небольшую часть большого файла; в таких случаях программа, способная выбрать, скажем, 10% наибольших элементов файла, может оказаться предпочтительнее полной сортировки. Другим важным примером является использование разбиения по медиане в качестве первого шага во многих алгоритмах вида " разделяй и властвуй " .
Мы уже знакомы с алгоритмом, который может быть приспособлен непосредственно для выборки. Если к очень мало, то хорошо будет работать сортировка выбором (см. "Элементарные методы сортировки" ), с затратами времени, пропорциональными N к: сначала находится наименьший элемент, затем наименьший из оставшихся элементов после первого выбора и т.д. Для несколько больших к в главе 9 "Очереди с приоритетами и пирамидальная сортировка" мы ознакомимся с методами, которые можно адаптировать, чтобы время их выполнения было пропорциональным N log к.
Метод выборки, выполняющийся в среднем за линейное время для всех значений к, следует непосредственно из процедуры разбиения, используемой в быстрой сортировке. Вспомним, что этот метод переупорядочивает массив a[1], ..., a[r] и возвращает целое i такое, что элементы a[1], ..., a[i-1] меньше или равны a[i], а элементы a[i+1], ..., a[r] больше или равны a[i]. Если k равно i, то задача решена. Иначе, если k < i, нужно продолжать обработку левого подфайла, а если k > i, нужно продолжать обработку правого подфайла. Этот подход непосредственно приводит к рекурсивной программе нахождения выборки, т.е. к программе 7.6. Пример работы этой процедуры для небольшого файла показан на рис. 7.13.
Для ключей из данного примера выборка разбиением требует только три рекурсивных вызова на поиск медианы. В первом вызове ищется восьмой наименьший элемент в файле из 15 элементов, а разбиение дает четвертый наименьший (элемент E). Поэтому во втором вызове ищется четвертый наименьший элемент в файле из 11 элементов (элемент R). И поэтому в третьем вызове ищется четвертый наименьший элемент в файле из 7 элементов - и он находится (элемент M). Файл переупорядочивается таким образом, что медиана находится на своем месте, меньшие элементы - слева от нее, а большие - справа (равные элементы могут находиться с любой стороны), но полной упорядоченности нет.
Программа 7.6. Выборка
Данная процедура разбивает массив по (k-1-му наименьшему элементу (который находится в a[k]): она переупорядочивает массив так, что a[1], ..., a[k-1] меньше или равны a[k], а a[k+1], ..., a[r] больше или равны a[k].
Например, можно вызвать select(a,0,N-1,N/2) для разбиения массива по медиане так, чтобы медиана осталась в a[N/2].
template <class Item>
void select(Item a[], int l, int r, int k)
{
if (r <= l) return;
int i = partition(a, l, r);
if (i > k) select(a, l, i-1, k);
if (i < k) select(a, i+1, r, k);
}
Программа 7.7 является нерекурсивной версией, непосредственно вытекающей из рекурсивной версии в программе 7.6. Поскольку программа 7.6 всегда завершается одиночным вызовом самой себя, мы просто переустанавливаем параметры и возвращаемся в начало. Таким образом мы избавились от рекурсии, не используя стек, а также избавились от вычислений, использующих k, храня его как индекс массива.
Лемма 7.4. Выборка, основанная на быстрой сортировке, в среднем выполняется за линейное время.
Как и в случае быстрой сортировки, можно (грубо) предположить, что для очень больших файлов каждое разбиение делит массив приблизительно пополам, так что весь процесс потребует примерно N + N/2 + N/4 + N/8 + ... = 2N операций сравнения. И так же, как и для быстрой сортировки, это грубое приближение недалеко от истины. Анализ, подобный приведенному в разделе 7.2 для быстрой сортировки, но гораздо более сложный (см. раздел ссылок), приводит к тому, что порядок среднего количества сравнений равен выражению
2 N + 2kln (N/ k) + 2(N - k) ln (N / (N - k)) ,
которое линейно для любого допустимого значения к. При к = N/ 2 из этой формулы следует, что для нахождения медианы требуется порядка (2 + 2 ln 2) N сравнений. 
Программа 7.7. Нерекурсивная выборка
Нерекурсивная реализация выборки просто разбивает массив, затем смещает левый индекс, если разбиение попало слева от искомой позиции, или смещает правый индекс, если разбиение попало справа от искомой позиции.
template <class Item>
void select(Item a[], int l, int r, int k)
{
while (r > l)
{ int i = partition(a, l, r);
if (i >= k) r = i-1;
if (i <= k) l = i+1;
}
}
Пример того, как этот метод находит медиану в большом файле, приведен на рис. 7.14. Здесь имеется лишь один подфайл, размер которого при каждом вызове уменьшается в одно и то же число раз, так что эта процедура завершается за O(log N) шагов. Программу можно ускорить, введя в нее разбиение по случайной выборке, но при этом следует соблюдать осторожность (см. упражнение 7.45).
В процессе выборки выполняется разбиение подфайла, который содержит искомый элемент. В зависимости от того, куда попадает разбиение, левый индекс перемещается вправо или правый индекс перемещается влево.
Наихудший случай здесь почти тот же, что и для быстрой сортировки: использование этого метода для нахождения наименьшего элемента уже упорядоченного файла приводит к квадратичному времени выполнения. Можно модифицировать процедуру выборки, основанную на быстрой сортировке так, что время ее выполнения будет гарантировано линейным. Однако эти модификации, будучи важными теоретически, очень сложны и неприемлемы на практике.
Упражнения
7.41. Оцените среднее количество операций сравнения, требуемое для нахождения наименьшего из N элементов при использовании метода select.
7.42. Оцените среднее количество операций сравнения, требуемое для нахождения aN-го наименьшего элемента при использовании метода select, для a = 0.1, 0.2, ... , 0.9.
7.43. Сколько потребуется операций сравнения в худшем случае для нахождения медианы из N элементов при использовании метода select?
7.44. Напишите эффективную программу, переупорядочивающую файл так, чтобы все элементы с ключами, равными медиане, оказались в окончательной позиции, меньшие элементы находились слева, а элементы, большие медианы - справа.
7.45. Обдумайте идею усовершенствования выборки с помощью оценки по случайной выборке. Совет: использование медианы помогает не всегда.
7.46. Реализуйте алгоритм выборки на базе трехчастного разбиения для больших случайно упорядоченных файлов с ключами, принимающими t различных значений, для t = 2, 5 и 10.
Бактыгуль Асаинова
Александра Боброва
|
Я прошла все лекции на 100%. Но в https://www.intuit.ru/intuituser/study/diplomas ничего нет. Что делать? Как получить сертификат? |