Управление производительностью с использованием NNM
Данные SNMP о производительности в MIB2 и персональных MIB
В промышленном стандарте MIB-2 имеются сотни полезных переменных. Большая их часть располагается в разделе интерфейсов, и еще несколько переменных можно найти в разделе IP. Разумно ограничить объем собираемых данных до абсолютно необходимого минимума. Это позволит избежать перегрузки агентов SNMP, излишнего обременения сети и хранения на жестком диске множества ненужных данных о производительности.
| NNM MIB Expression MIB-выражение NNM | Предлагаемые пороговые установки | Пояснительные замечания |
|---|---|---|
| avgBusy5 | Подать сигнал тревоги при 90% для 4 выборок. Отменить сигнал тревоги при 50% для 2 выборок | Средняя интенсивность нагрузки ЦП маршрутизатора за пять минут. Высокая интенсивность нагрузки ЦП маршрутизатора – не всегда недостаток |
| If%util | Подать сигнал тревоги при 90% для 4 выборок. Отменить сигнал тревоги при 60% для 2 выборок | Интерфейс трактуется как дуплексный. Высокая интенсивность нагрузки сама по себе не является проблемой |
| If%inErrors | Подать сигнал тревоги при 1% для 4 выборок. Отменить сигнал тревоги при 0% для 2 выборок | Постоянное наличие даже небольшого числа ошибок – это плохо |
| If%outErrors | Подать сигнал тревоги при 1% для 4 выборок. Отменить сигнал тревоги при 0% для 2 выборок | Постоянное наличие даже небольшого числа ошибок – это плохо |
| IP%PacketLoss | Подать сигнал тревоги при 1% для 4 выборок. Отменить сигнал тревоги при 0% для 2 выборок | Потери пакетов на маршрутизаторе из-за переполнения буфера и других болезненных ситуаций снижают производительность приложения. Для маршрутизаторов Cisco считается число пакетов, которые маршрутизатор не смог перенаправить, поскольку при попытке пересылки не был получен ответ от ARP |
Часто одна переменная не может сама по себе обеспечить полную картину. Например, число ошибок ввода на интерфейсе само по себе бессмысленно. Прежде чем можно будет судить, является ли частота ошибок слишком большой, нужно разделить число ошибок на число полученных пакетов и умножить на 100.
NNM обеспечивает возможность создавать математические формулы, составленные из MIB-значений. Эти формулы называются MIB-выражениями, и обычно они гораздо более полезны, чем необработанные значения SNMP. В таблице 9.2 перечисляются некоторые рекомендуемые формулы и пороговые установки, которыми можно обойтись поначалу.
Заметим, что первый элемент в этой таблице не является MIB-выражением, это часть корпоративной MIB Cisco. Для всех значений таблицы рекомендуемый интервал взятия образцов составляет пять минут. Приведенные пороговые значения устанавливаются эмпирическими правилами. Сигналы тревоги генерируются на основе четырехкратной выборки образцов, что гарантирует устойчивость соответствующего условия, тогда как отмена сигнала тревоги основывается на двукратной выборке образцов, что обеспечивает быстрое выявление возврата к нормальной ситуации.
Стратегии установки пороговых значений
Следует ли устанавливать пороговые значения для опроса производительности? Что собирается делать персонал с пороговыми событиями?
В чем состоит локальная обработка? Ответ следующий: ничего сделать нельзя и ничего делать не следует. В конце концов, если пользователь загружает по сети большой файл или если выполняется резервное копирование, уместно ли выслеживать систему-нарушительницу и отключать порт коммутатора, к которому она подключена? Такой вид полицейского управления сетью определенно вызовет негативную реакцию пользователей.
Пороговое событие следует расценивать всего лишь как предупреждение, не требующее от персонала незамедлительных действий. Это также позволяет обученному ECS сетевому менеджеру создавать специальные схемы, которые сопоставляют пороговые события и генерируют более целесообразные события. Например, если пороговые события наблюдаются в значительной части сети, то специальная схема сопоставления событий может это выявлять и генерировать некоторое более важное событие.
Если предполагается, что желательно генерировать пороговые события, то каким образом следует устанавливать пороговые значения? Можно рассмотреть три подхода.
Простейший способ основан на использовании опубликованных эмпирических правил, подобных тем, которые приведены в таблице 9.2, и учебников по планированию пропускной способности2John Blommers, Prentice Hall, 1996, Практическое планирование роста сети (Practical Planning for Network Growth), ISBN 0-13-206111-2.
Более сложный подход состоит в повышении уровня пороговых уровней до тех пор, пока интенсивность событий не станет приемлемо низкой. Очевидно, что этот подход является трудоемким, поскольку приходится отслеживать каждый интерфейс и производить индивидуальную наладку. Этот метод еще называют "последовательной оптимизацией". Для каждого устройства показатели производительности отслеживаются на протяжении нескольких недель, и затем соответствующим образом изменяются пороговые уровни. Заметим, что эти пороговые уровни можно вручную добавить в файл $OV_CONF/snmpCol.conf, чтобы избежать утомительной работы с GUI конфигурирования сборщика данных SNMP. Формат этого файла изменен в версии NNM 6.0, так что при модернизации системы NNM следует соблюдать осторожность при миграции этого файлового формата.
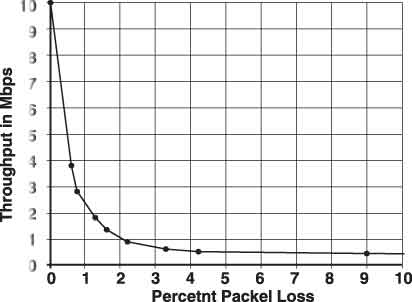
Как показано на этом рисунке, аналитический подход к установке порогов ошибок включает исследование опытных данных. На этом графике показано одно потоковое соединение TCP между рабочими станциями одного сегмента LAN, подверженного потере пакетов. Как видно, самый незначительный процент потери пакетов фактически сводит на нет преимущества потоковой передачи данных на основе TCP. Эти данные обосновывают установку значения порога ошибок в один процент.
И, наконец, существует подход к установке пороговых значений на основе аналитических рассуждений. Например, предположим, что последовательный канал моделируется как простая очередь M/M/1. Напомним, что если эта очередь нагружается на 90%, то среднее время ожидания превышает норму в 10 раз. Это уважительная причина для сигнала тревоги. По поводу частоты ошибок и потери пакетов рассмотрим график, приведенный на рис. 9.7. Он показывает, как падает пропускная способность TCP у приложения, выполняющего непрерывную передачу данных с использованием TCP, при увеличении процентного отношения потерянных пакетов. Наличие всего одного процента потери пакетов фактически снижает пропускную способность до ничтожного уровня.

В примерах, приведенных в тексте, для генерации порогового события требовалось превышение значение порога тревоги в четырех последовательных выборках образцов. Образец B приведет к генерации события, а образец A – нет, поскольку только в одной из последовательных выборок превышено значение порога тревоги. В двух последовательных выборках образцов не должен превышаться порог отмены тревоги, так что образец C является единственно пригодным.
Чтобы избежать генерации сигнала тревоги по причине случайной одиночной ошибки, можно воспользоваться пороговыми опциями NNM. Если указать, что данный показатель должен превысить пороговое значение для четырех последовательных выборок образцов, то можно гарантировать, что сигнал тревоги будет вырабатываться только при продолжительном существовании условия ошибки. При пятиминутных выборках это означает, что для подачи сигнала тревоги требуется 20-минутная продолжительность существования условия ошибки. Чтобы обеспечить быстрое обнаружение восстановления обслуживания, можно установить продолжительность интервала снятия сигнала тревоги всего лишь в две выборки образцов, или в 10 минут. Эти принципы объясняются на рис. 9.8.