Приложение. Параллельные вычисления на кластерах из персональных компьютеров в математической физике (В.Е.Карпов, А.И.Лобанов)
5.3. Статическая модель
Как правило, статическая модель характеризуется наименьшим количеством обменов информацией между процессами, но требует тщательной предварительной балансировки загрузки процессоров.
Удобно обеспечить баланс загрузки для случая 6 процессоров, распределяя между ними области ответственности, как показано на рис. 3. Процессор, отвечающий за верхний и нижний срезы, будет загружен меньше, чем остальные, но можно поручить ему отображение текущего состояния решения задачи. Незначительное ухудшение балансировки получается при разделении средних областей ответственности пополам, а верхнего и нижнего срезов между разными компьютерами для 12 процессоров.

Рис. 3. Разделение на области ответственности для 6 процессоров при использовании статической модели вычислений
При идеальной балансировке для N процессоров время выполнения каждой итерации по-прежнему будет 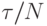 . Для следующей итерации процессоры должны обменяться с соседями значениями потенциалов на граничных слоях, передав два слоя, и приняв два слоя от них. Это займет не более чем
. Для следующей итерации процессоры должны обменяться с соседями значениями потенциалов на граничных слоях, передав два слоя, и приняв два слоя от них. Это займет не более чем

секунд, где nnodesr — количество узлов в одном радиальном слое, а константы 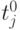 и kj выбираются для объема передаваемой информации nnodesr x 8 байт. Оценка ускорения может быть получена как
и kj выбираются для объема передаваемой информации nnodesr x 8 байт. Оценка ускорения может быть получена как  .
.
Если проводить проверку условия выхода из итераций (4) на каждой итерации, то дополнительно потребуется рассылка значения частичной погрешности по всем процессорам. Это приведет к дополнительным затратам на пересылку, в лучшем случае, 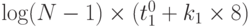 секунд.
секунд.
Исправить ситуацию возможно, вычисляя значение погрешности не на каждой итерации, а, скажем, после каждой 100 -й итерации. Рискуем выполнить лишние 100 итераций, что составляет доли процента от их общего количества, но при этом дополнительные коммуникационные затраты не влияют на эффективность работы программы.
Предварительная оценка ускорения вычислений на имеющемся комплексе с использованием пакета PVM составляет 5,7 раза для 6 процессоров и 10,1 раза для 12 процессоров. Реальное ускорение, естественно, будет несколько меньше из-за невозможности точной предварительной балансировки загрузки процессоров в статической модели. Проведенный расчет с использованием коммуникационного пакета PVM показал реальное ускорение по отношению к последовательному варианту 5,03 раза для 6 процессоров и 8,7 раза — для 12.
На основе расчетов вариантов модернизации установки было принято решение изменить форму компенсаторных колец и распределение потенциала на кольцах. Окончательный вариант приведен на рис. 4. Вычисления показали значительное снижение напряженности внутри диэлектрика в области нижних компенсаторных колец (рис. 5) и позволили сделать вывод об отсутствии пробоя. Данный вариант был принят за основу модернизации установки РС-20.


Рис. 5. Распределение потенциала для этого варианта расположения компенсаторных колец (приведен фрагмент расчетной области)
6. Заключение
Рассмотренный пример относится к решению сравнительно простой задачи математической физики. Динамика плазмы (в частности, в РС-20 ) описывается гораздо более сложной системой уравнений в частных производных. Однако эта задача позволяет проанализировать методы организации параллельных вычислений и отладить технологию применения кластеров для сложных расчетов. В задачах динамики плазмы, например, наиболее эффективной оказывается динамическая модель организации вычислений.
Но и приведенная задача представляла практический интерес. Во-первых, для физиков. Модернизированная установка активно эксплуатируется. Во-вторых, для математиков-прикладников. На примере задачи проведен анализ алгоритмов на наличие внутреннего параллелизма и отработана технология оценок эффективности распараллеливания без предварительного исполнения последовательных вариантов.