Информационно-поисковые тезаурусы и автоматическая обработка текстов
Методы машинного обучения в задачах рубрикации
В задаче рубрикации текстов используются различные методы машинного обучения, иллюстрируемые следующими рисунками (рис. 10.5-10.8).



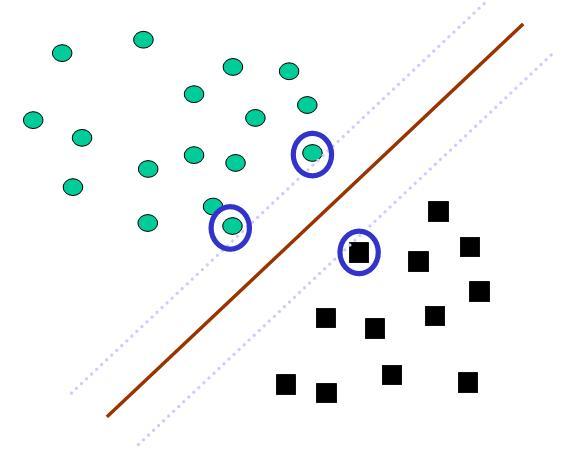
Рис. 10.8. Оптимальный линейный сепаратор SVM (Support Vector Machines). Оптимизация по критерию максимизации расстояния между двумя параллельными поддерживающими плоскостями
Сложные задачи автоматической рубрикации текстов
Реальные задачи рубрикации текстов в значительной мере отличаются от задачи классификации сообщений на тестовой коллекции агентства Рейтер. На практике, если перед достаточно большой компанией встает задача автоматической рубрикации текстов, то обычно используются автоматизированные технологии, основанные на ручном подборе лексики под каждую рубрику рубрикатора с последующим контролем результатов рубрицирования.
Факторами, усложняющими или делающими невозможным применение методов машинного обучения для автоматической рубрикации текстов, являются следующие:
- множество примеров отсутствует и не может быть создано в короткое время;
- множество примеров существует, но при их создании отсутствовали требования к качеству, например, документы отрубрицированы их авторами, то есть людьми, которые не имеют согласованного взляда на содержание каждой конкретной рубрики;
- множество примеров противоречиво и (или) недостаточно для большинства рубрик (очень большие классификаторы) - такая ситуация может возникнуть и при едином руководстве ручной рубрикацией;
- множество примеров для обучения взято из близкой, но другой коллекции.
Применение тезауруса для решения сложных задач рубрикации
В информационной системе УИС РОССИЯ реализована система автоматического рубрицирования, способная рубрицировать тексты различных типов (официальные документы, сообщения информационных агентств, газетные статьи), ее легко можно настроить на новый рубрикатор и новые типы текстов, рубрицирование можно осуществлять сразу по нескольким рубрикаторам.
Реализация такой гибкой технологии автоматического рубрицирования основывается на определенных способах представления знаний о предметной области и представления текстовой информации:
- знания о предметной области хранятся в виде иерархической сети в так называемом Тезаурусе по общественно-политической жизни России;
- рубрикаторы связываются с Тезаурусом посредством небольшого числа опорных терминов, рубрики остальных терминов выводятся по связям внутри Тезауруса, что стало возможным благодаря тщательной предварительной разработке тезаурусных связей, максимально полному отражению различных аспектов описываемых понятий;
- возможность обрабатывать тексты разных типов и размеров базируется на тематическом представлении содержания текста, которое моделирует основную тему и подтемы документа наборами (тематическими узлами) близких по смыслу терминов документа.
Схема описания рубрики
Каждая рубрика R описывается дизъюнкцией альтернатив, каждый дизъюнкт представляет собой конъюнкцию:
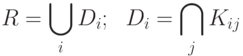
Конъюнкты, в свою очередь, описываются экспертами с помощью так называемых "опорных" понятий тезауруса. Для каждого опорного понятия задается правило его расширения f(•), определяющее, каким образом вместе с опорным понятием учитывать подчиненные ему по иерархии понятия. Выделяются три случая - без расширения (обозначается символом N ), полное расширение по дереву иерархии тезауруса (символ E ) и расширение только по родо-видовым связям (символ L ).
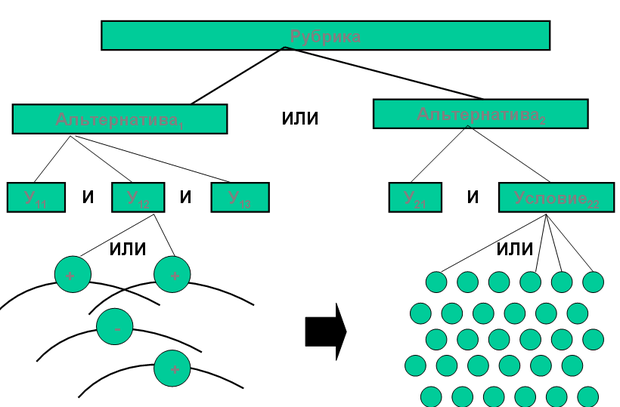
Опорный концепт может быть как "положительным", который добавляет нижерасположенные понятия в описание конъюнкта, так и "отрицательным", который вырезает свои подчиненные понятия. Последовательность учета положительных и отрицательных опорных понятий регулируется заданием специального атрибута. Результатом применения расширения опорных понятий является совокупность понятий тезауруса, полностью описывающая конъюнкт:
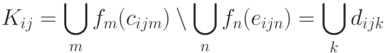
Контрольные вопросы
- Перечислите методы автоматической рубрикации.
- По каким причинам возникают сложности в задачах автоматической рубрикации текстов?
- Какие рубрикаторы вам известны? Опишите их характеристики.