Области применения онтологий. Задачи, решаемые с помощью онтологий и тезаурусов
3.3. Интеграция разнородных источников данных
Под базой данных (БД) будем понимать коллекцию согласованных взаимосвязанных данных, которые имеют некоторое "скрытое (внутри) значение". БД похожи на базы знаний (БЗ), поскольку они также используются для описания некоторой предметной области с целью хранения, обработки и доступа к необходимой информации о ней. Однако есть и различия. Базы данных содержат (и способны обрабатывать) большие массивы относительно простой информации (при этом доступ возможен только к этим явно введенным данным). В базах знаний обычно хранится меньший объем информации, но они имеют более сложную структуру, что позволяет использовать возможности логического вывода и получать такие утверждения, которые не были в явном виде введены.
Подразумевается, что к любой БЗ могут быть применимы 3 операции: определить (define), сказать (tell) (т.е. сделать утверждение) и спросить (ask). Каждая из операций может использовать один или более собственных языков, например язык описания схем и ограничений, язык обновления (для новых утверждений), язык запросов и язык описания результата. Преимущества применения дескриптивной логики (DL) для улучшения каждого из языков широко изучены в литературе по базам знаний. Здесь будут рассмотрены три важные задачи, возникающие при управлении данными:
- выражение концептуальной модели предметной области (онтологии) для конкретного источника данных,
- интеграция нескольких источников,
- выражение и выполнение запросов.
Для каждой из задач существует подход с использованием DL.
Сначала - несколько основных понятий из области проектирования БД и их использования.
В первую очередь, еще до создания БД, возникает необходимость описать предметную область таким языком, чтобы описание было понятно как обычным пользователям, так и разработчикам. Это описание выполняется на языке высокого уровня и имеет форму требований. В области БД таким языком являются ER-диаграммы (ER-модель). В рамках ER-модели окружающий мир представляется как набор сущностей ( n -арных отношений). Полученная семантическая модель предметной области может храниться на компьютере, так же как и сами данные, но, как правило, она содержит общую и постоянную информацию (например, о том, что "отдел предприятия имеет ровно одного руководителя") в противоположность конкретным фактам ("Петров является руководителем отдела поставок"). Эта семантическая модель вводит термины для описания предметной области и определяет их значения путем задания взаимосвязей и ограничений. Этот уровень представления данных наиболее близок онтологическому представлению.
Из семантической модели создается логическая схема, описывающая структуры данных в БД, типы данных, взаимосвязи и ограничения. Наиболее популярной и часто используемой для выражения логической схемы является реляционная модель данных. При спецификации логической схемы применяются СУБД. В реляционной модели данные хранятся в таблицах (отношениях), содержащих строки (кортежи), которые, в свою очередь, состоят из ячеек со значениями простых типов данных (целые числа, строки, даты и т.п.). Поэтому для описания логической схемы требуется описать имена таблиц, имена их столбцов (атрибутов) и соответствующие типы данных. Реляционные СУБД требуют, чтобы в каждой таблице был определен набор столбцов (ключ), уникально идентифицирующий строку таблицы. Часто СУБД предлагают средства для поддержания целостности с помощью задания ограничений целостности - утверждений, которые способны отделить корректные состояния базы данных от некорректных.
БД используются для хранения информации о текущем состоянии "окружающего" мира. При этом делается так называемое "предположение о замкнутости". Оно означает, что факт является ложным, пока явно не определен как истинный. Такое предположение работает хорошо, только если БД описывает очень ограниченную область. В частности, в БД не разрешается описывать дизъюнктивную информацию и поддерживается ограниченная форма квантора существования: если нет информации о значении атрибута, то оно считается равным NULL.
Декларативный язык SQL для описания запросов к реляционным БД, определения содержимого таблиц и их структуры является универсальным и мощным практическим средством. Однако с точки зрения теории язык логики предикатов первого порядка имеет более "элегантный" вид, если представить, что таблицы являются предикатами.
Например, формула
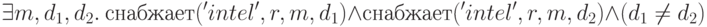
могла бы определять запрос относительно тех получателей (значения свободной переменной  ), которые снабжались поставщиком '
), которые снабжались поставщиком '  ' одним и тем же материалом
' одним и тем же материалом 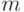 в различные моменты времени (
в различные моменты времени ( 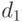 и
и  ).
).
СУБД скрывает от пользователя детали реализации тех или иных функций, делая прозрачным физический уровень: способ организации хранения данных на носителях информации, вспомогательные структуры данных для ускорения доступа и даже тот факт, что БД распределена по нескольким узлам сети. Но у пользователя может возникнуть желание получить информацию сразу из нескольких независимых (и скорее всего разнородных) источников. В такой ситуации возникает проблема связывания различных логических схем в одну (предоставляемую пользователю).
Интеграция разнородных источников данных - фундаментальная проблема, возникшая в последние десятилетия перед сообществом разработчиков БД. Цель интеграции данных состоит в том, чтобы предоставить единый интерфейс к различным источникам и позволить пользователям сосредоточиться на определении того, что они хотят узнать. В результате интеграция должна освободить пользователя от поиска релевантных источников данных, взаимодействия с ними по отдельности, отбора и комбинирования данных из различных источников. Проектирование системы интеграции данных - очень сложная задача.
Рассмотрим "классические" подходы к ее решению. Первый из них состоит в использовании федеративных БД, которые независимо хранят одну и ту же информацию, периодически синхронизируя свои состояния. Для синхронизации  федеративных БД требуется определить
федеративных БД требуется определить 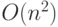 связей. Другой подход состоит в создании единого централизованного хранилища данных. Данные из разнородных источников периодически копируются в хранилище (требуется
связей. Другой подход состоит в создании единого централизованного хранилища данных. Данные из разнородных источников периодически копируются в хранилище (требуется  связей для БД). Третий подход (наиболее эффективный, но и трудоемкий) использует технологию создания программных оболочек, или медиаторов (mediators, wrappers), обеспечивающих единый интерфейс доступа к различным БД.
связей для БД). Третий подход (наиболее эффективный, но и трудоемкий) использует технологию создания программных оболочек, или медиаторов (mediators, wrappers), обеспечивающих единый интерфейс доступа к различным БД.
Задача "проектирование системы интеграции данных" состоит из нескольких подзадач. Онтологический подход может успешно применяться для решения двух подзадач:
- спецификации содержимого разнородных источников данных в виде онтологии;
- получения ответов на запросы, адресованные интегрирующей системе и основанные на спецификации источников.
Спецификация содержимого разнородных источников данных
Обычно архитектура системы интеграции данных позволяет явно моделировать данные и информационные потребности (т.е. определять те данные, которые система предоставляет пользователю) на различных уровнях.
- Концептуальный уровень содержит концептуальное представление источников и согласованных интегрируемых данных вместе с явным декларативным описанием отношений между их компонентами.
- Логический уровень содержит представление источников в терминах логической модели данных.
Концептуальный уровень
Данный уровень содержит формальные описания понятий, отношений между понятиями и дополнительные требования. Эти описания являются независимыми от системы интеграции и ориентированы на описание семантики приложения. На концептуальном уровне выделяют 3 элемента:
- Концептуальная схема уровня предприятия (понимаемого в широком смысле). Здесь представляются наиболее общие понятия, связанные с приложением.
- Концептуальная схема информационного источника является концептуальным представлением данных.
- Концептуальная схема предметной области используется для описания объединения концептуальной схемы уровня предприятия и различных концептуальных схем информационных источников. Кроме того, сюда же входят дополнительные межсхемные отношения.
Элементарные понятия реляционной модели данных, такие как сущности, отношения и атрибуты, могут быть выражены на языке дескриптивной логики (DL) следующим образом. По ER-схеме  создается база знаний
создается база знаний  , которая определяется так:
, которая определяется так:
- множество атомарных концептов состоит из множества сущностей и доменных символов ;
- множество атомарных отношений получается из множества отношений и атрибутных символов ;
- множество аксиом включения состоит из утверждений, которые формализуют иерархические зависимости между сущностями и отношениями, ограничения на сущности, имеющие атрибуты и/или связанные отношениями, и ограничения кардинальности для ролей каждого из отношений.
Важным свойством отображения является его взаимная однозначность, что позволяет строить логические выводы в рамках базы знаний средствами DL, а затем переносить результаты на ER-модель.
Таким образом, моделирование концептуальных схем БД при помощи онтологий не только возможно, но и дает дополнительные преимущества.
Наиболее интересным элементом на концептуальном уровне является схема предметной области, интегрирующая схему предприятия и схемы информационных источников, а также связывающая схемы информационных источников между собой. При этом используются межсхемные отношения. Они формально представляются как утверждения вида

где 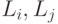 являются некоторыми выражениями в различных схемах. Они могут быть либо отношениями с одинаковым числом аргументов, либо концептами. Первый индекс рядом со знаком включения означает следующее: любой объект, удовлетворяющий выражению
являются некоторыми выражениями в различных схемах. Они могут быть либо отношениями с одинаковым числом аргументов, либо концептами. Первый индекс рядом со знаком включения означает следующее: любой объект, удовлетворяющий выражению  в
в 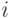 -м источнике, удовлетворяет также выражению
-м источнике, удовлетворяет также выражению 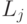 в
в 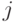 -м источнике. Например, если известно, что множество сотрудников, описанных в источнике 1, является подмножеством сотрудников, описанных в источнике 2, то это может быть выражено так:
-м источнике. Например, если известно, что множество сотрудников, описанных в источнике 1, является подмножеством сотрудников, описанных в источнике 2, то это может быть выражено так:

Второй тип межсхемных утверждений (соответствует индексу  ) указывает, что концепт, описанный выражением в -м источнике, является подконцептом того, который описан выражением в -м источнике. Например, если известно, что концепт "сотрудник", описанный в источнике 1, является подконцептом концепта "личность", который описан в источнике 2, то это может быть выражено так:
) указывает, что концепт, описанный выражением в -м источнике, является подконцептом того, который описан выражением в -м источнике. Например, если известно, что концепт "сотрудник", описанный в источнике 1, является подконцептом концепта "личность", который описан в источнике 2, то это может быть выражено так:

Логический уровень
Данный уровень представляет описание логического содержимого для каждого источника, которое называется схемой источника. Обычно схема источника выражается в терминах набора отношений с использованием логической реляционной модели данных. Связывание логического представления источника и концептуальной схемы предметной области возможно двумя способами:
- подход на основе глобального представления. С каждым концептом концептуальной схемы предметной области ассоциируется запрос над базовыми отношениями источника. Таким образом, каждый концепт можно понимать как представление источника;
- подход на основе локального представления. Каждое отношение в источнике ассоциируется с запросом, описывающим его содержимое в терминах концептуальной схемы предметной области. Другими словами, содержимое каждого базового отношения внутри источника выражается через концепты предметной области.
Для описания содержимого источника используется понятие запрос. Запрос определяется как дизъюнкция конъюнкций над множеством атомов. Каждый из атомов является концептом, отношением или атрибутом.
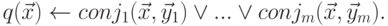
Контрольные вопросы
- Перечислите традиционные подходы к обработке запроса. В чем их недостатки?
- Чем критерий полноты отличается от критерия точности?
- Назовите способы улучшения поиска при помощи тезаурусов и онтологий.
- Перечислите основные элементы ER-модели.
- В чем, на ваш взгляд, проявляется "интеллектуальность" агентов Semantic Web?