




 для
для 


|
В дисциплине "Основы эконометрики" тест 6 дается по теме 7. |
Инспектор
Вы можете этот курс.
Опубликован: 10.09.2016 | Уровень: для всех | Доступ: платный
Лекция 10:
Стационарные временные ряды, модели авторегрессии - скользящего среднего
10.6. Построение АРСС-моделей
Первым шагом в подборе АРСС-модели наблюдаемого временного ряда является оценка среднего - 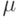 , дисперсии -
, дисперсии -  и автокорреляций
и автокорреляций  . В предположении стационарности и эргодичности (возможности получения оценок по одной реализации процесса) применимы следующие оценки:
. В предположении стационарности и эргодичности (возможности получения оценок по одной реализации процесса) применимы следующие оценки:
и
Выборочные АКФ из (10.46) и ЧАКФ, полученные по формулам (10.39)-(10.43), сравнивают с различными теоретическими функциями, чтобы идентифицировать процесс, породивший данную выборочную реализацию.
Дж. Бокс и Г. Дженкинс (1976) получили формулу для расчета дисперсии выборочной АКФ  в предположении, что
в предположении, что  - стационарны с нормально распределенными ошибками. Тогда
- стационарны с нормально распределенными ошибками. Тогда
при настоящем значении  . Более того, в большой выборке (
. Более того, в большой выборке ( - велико) нормально распределено с нулевым средним. Для коэффициентов ЧАКФ АР(р)-модели доказано, что
- велико) нормально распределено с нулевым средним. Для коэффициентов ЧАКФ АР(р)-модели доказано, что  .
.
На практике полученные выборочные значения АКФ и ЧАКФ тестируются на значимость с использованием (10.47) и (10.48). Например, для 95%-ого доверительного интервала (двух стандартных отклонений), если  превышает
превышает  , то следует отвергнуть нулевую гипотезу о том, что АКФ первого порядка статистически незначимо отличается от нуля. Это означает, что
, то следует отвергнуть нулевую гипотезу о том, что АКФ первого порядка статистически незначимо отличается от нуля. Это означает, что  , где
, где 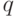 - показатель числа запаздываний в модели
- показатель числа запаздываний в модели  . Затем, пусть
. Затем, пусть  .
.
Если, например,  , то
, то  и
и  . Тогда если вычисленное по выборке значение
. Тогда если вычисленное по выборке значение  превышает
превышает  (два стандартных отклонения), то при принятых ограничениях с 95%-ной вероятностью можно утверждать, что гипотезу
(два стандартных отклонения), то при принятых ограничениях с 95%-ной вероятностью можно утверждать, что гипотезу 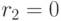 надо отвергнуть. Следовательно,
надо отвергнуть. Следовательно,  . Повторяя процесс проверки гипотез для различных
. Повторяя процесс проверки гипотез для различных  можно пытаться идентифицировать порядок процесса.
можно пытаться идентифицировать порядок процесса.
Однако если просматривать большое число АКФ, то можно обнаружить, что некоторые АКФ превышают  , хотя настоящие
, хотя настоящие  . Это вызвано как 5%-ными ошибками первого рода, так и несоответствием реальных распределений теоретическим предпосылкам нормальности ошибок.
. Это вызвано как 5%-ными ошибками первого рода, так и несоответствием реальных распределений теоретическим предпосылкам нормальности ошибок.
Следующая  -статистика может быть использована для тестирования, когда группа АКФ значимо отличается от нуля. -статистика Бокса - Пирса имеет вид
-статистика может быть использована для тестирования, когда группа АКФ значимо отличается от нуля. -статистика Бокса - Пирса имеет вид
Если данные порождены стационарным АРСС-процессом, то асимптотически  -распределенная с степенями свободы. Интуитивно понятно, что большие значения АКФ ведут к большим значениям . Если выборочное превышает соответствующее табличное значение , то отвергается гипотеза о незначимости группы АКФ. Отметим, что альтернативная гипотеза означает, что хотя бы одна АКФ не равна нулю.
-распределенная с степенями свободы. Интуитивно понятно, что большие значения АКФ ведут к большим значениям . Если выборочное превышает соответствующее табличное значение , то отвергается гипотеза о незначимости группы АКФ. Отметим, что альтернативная гипотеза означает, что хотя бы одна АКФ не равна нулю.
Однако оказалось, что даже в средней величины выборках -статистика работает плохо. Для малых выборок используют модифицированную -статистику Льюиса - Бокса, вычисленную по формуле
Если выборочное значение -статистики превышает критическое значение -распределения с степенями свободы, то по крайней мере одно значение 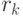 статистически отлично от нуля при данном уровне значимости. Особо полезны эти статистики для проверки гипотезы об образовании остатками вычисленной АРСС(
статистически отлично от нуля при данном уровне значимости. Особо полезны эти статистики для проверки гипотезы об образовании остатками вычисленной АРСС( )-модели белого шума. Поэтому если рассчитывать АКФ для остатков оцененной АРСС()-модели, то число степеней свободы уменьшается на число коэффициентов модели. Следовательно, используя остатки для АРСС()-модели, необходимо проверять с помощью -распределения с
)-модели белого шума. Поэтому если рассчитывать АКФ для остатков оцененной АРСС()-модели, то число степеней свободы уменьшается на число коэффициентов модели. Следовательно, используя остатки для АРСС()-модели, необходимо проверять с помощью -распределения с  степенями свободы. Если включена свободная постоянная, то используем таблицы -распределения с
степенями свободы. Если включена свободная постоянная, то используем таблицы -распределения с  степенями свободы.
степенями свободы.
10.7. Селекция моделей АРСС
Наиболее простой и популярный в настоящее время метод селекции моделей предполагает построение множества моделей с различными 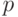 и , а затем выбор модели, минимизирующей выбранный критерий селекции, который характеризует качество модели.
и , а затем выбор модели, минимизирующей выбранный критерий селекции, который характеризует качество модели.
Существующие "внутренние" критерии селекции выражают компромисс между сложностью модели и величиной суммы квадратов остатков. Так, наиболее популярными являются информационный критерий Акайке (AIC) и бестестовый критерий Шварца (SBC), вычисляемые по формулам

где
|
- | число используемых наблюдений; |
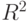 |
- | сумма квадратов остатков (ошибок) модели; |
 |
- | число оцениваемых параметров модели. |
Так как  , то оптимальная модель SBC будет менее сложной, чем оптимальная модель AIC. Стоимость "добавки" лишнего слагаемого больше для SBC-критерия, чем для AIC-критерия. Доказано, что с увеличением выборки SBC-модели асимптотически состоятельны, в то время как AIC-модели становятся слишком сложными.
, то оптимальная модель SBC будет менее сложной, чем оптимальная модель AIC. Стоимость "добавки" лишнего слагаемого больше для SBC-критерия, чем для AIC-критерия. Доказано, что с увеличением выборки SBC-модели асимптотически состоятельны, в то время как AIC-модели становятся слишком сложными.
Рассмотренные выше критерии отбора являются "внутренними", т.е. используют данные, уже ранее использованные для построения моделей. Если позволяет величина выборки, то гораздо надежнее использовать "внешние" критерии селекции, т.е. независимые наблюдения, не вошедшие в первоначальную выборку. Алгоритм построения АРСС()-модели по внешнему критерию минимизации ошибок на "экзаменующей" выборке рассмотрен ниже.