
| Россия |
Инспектор
Вы можете этот курс.
Опубликован: 27.07.2006 | Уровень: специалист | Доступ: платный
Лекция 5:
Процедура обратного распространения (анализ алгоритма)
Предостережения
Несмотря на многочисленные успешные применения обратного распространения, оно не является панацеей. Больше всего неприятностей доставляет неопределенно долгий процесс обучения. В сложных задачах для обучения сети могут потребоваться дни или даже недели, она может и вообще не обучиться. Длительное время обучения может быть результатом неоптимального выбора длины шага. Неудачи в обучении обычно возникают по двум причинам: паралича сети и попадания в локальный минимум.
Паралич сети
В процессе обучения сети значения весов могут в результате коррекции
стать очень большими величинами. Это может привести к тому, что все или
большинство нейронов будут функционировать при очень больших
значениях OUT, в области, где производная сжимающей функции очень
мала. Так как посылаемая обратно в процессе обучения ошибка
пропорциональна этой производной, то процесс обучения может практически
замереть. Теоретически эта проблема изучена плохо. Обычно пытаются
уменьшать размера шага 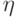 , но это увеличивает время обучения.
Различные эвристики использовались для предохранения от паралича
или для восстановления после него, но пока что они могут рассматриваться
лишь как экспериментальные.
, но это увеличивает время обучения.
Различные эвристики использовались для предохранения от паралича
или для восстановления после него, но пока что они могут рассматриваться
лишь как экспериментальные.
Локальные минимумы
В прошлой лекции было описано, как с помощью алгоритма обратного распространения осуществляется градиентный спуск по поверхности ошибок. Короче говоря, происходит следующее: в данной точке поверхности находится направление скорейшего спуска, затем делается прыжок вниз на расстояние, пропорциональное коэффициенту скорости обучения и крутизне склона, при этом учитывается инерция, то есть стремление сохранить прежнее направление движения. Можно сказать, что метод ведет себя как слепой кенгуру — каждый раз прыгает в направлении, которое кажется ему наилучшим. На самом деле, шаг спуска вычисляется отдельно для всех обучающих наблюдений, взятых в случайном порядке, но в результате получается достаточно хорошая аппроксимация спуска по совокупной поверхности ошибок. Существуют и другие алгоритмы обучения, однако все они используют ту или иную стратегию скорейшего продвижения к точке минимума.
Обратное распространение использует разновидность градиентного спуска, т. е. осуществляет спуск вниз по поверхности ошибки, непрерывно подстраивая веса в направлении к минимуму. Поверхность ошибки сложной сети сильно изрезана и состоит из холмов, долин, складок и оврагов в пространстве высокой размерности. Сеть может попасть в локальный минимум (неглубокую долину), когда рядом имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх и сеть неспособна из него выбраться. Статистические методы обучения могут помочь избежать этой ловушки, но они медленны. П.Д.Вассерман предложил метод, объединяющий статистические методы машины Коши с градиентным спуском обратного распространения и приводящий к системе, которая находит глобальный минимум, сохраняя высокую скорость обратного распространения. Это будет обсуждаться в следующих лекциях.
Размер шага
Внимательный разбор доказательства сходимости показывает, что коррекции весов предполагаются бесконечно малыми. Ясно, что это неосуществимо на практике, так как ведет к бесконечному времени обучения. Размер шага должен браться конечным, и при определении его приходится полагаться только на опыт. Если размер шага очень мал, то сходимость слишком медленная, если же очень велик, то может возникнуть паралич или постоянная неустойчивость. П.Д.Вассерман описал адаптивный алгоритм выбора шага, автоматически корректирующий размер шага в процессе обучения.
Временная неустойчивость
Если сеть учится распознавать буквы, то нет смысла учить "Б", если при этом забывается "А". Процесс обучения должен быть таким, чтобы сеть обучалась на всем обучающем множестве без пропусков того, что уже выучено. В доказательстве сходимости это условие выполнено, но требуется также, чтобы сети предъявлялись все векторы обучающего множества, прежде чем выполняется коррекция весов. Необходимые изменения весов должны вычисляться на всем множестве, что требует дополнительной памяти; после ряда таких обучающих циклов веса сойдутся к минимальной ошибке. Этот метод может оказаться бесполезным, если сеть находится в постоянно меняющейся внешней среде, так что второй раз один и тот же вектор может уже не повториться. В этом случае процесс обучения может никогда не сойтись, бесцельно блуждая или сильно осциллируя. В этом смысле обратное распространение не похоже на биологические системы. Как будет указано на следующих лекциях, это несоответствие (среди прочих) привело к системе ART, принадлежащей Гроссбергу.
Фанис Галимянов
| Россия, Казань, Татарский государственный гуманетарно-педагогический уневерситет, 2009 |