

|
Подскажите, пожалуйста, планируете ли вы возобновление программ высшего образования? Если да, есть ли какие-то примерные сроки? Спасибо! |
Инспектор
Вы можете этот курс.
Опубликован: 14.12.2009 | Уровень: специалист | Доступ: платный
Лекция 7: Принципы целостного целенаправленного распознавания и их реализация в программах компании ABBYY FineReader-рукопись и FormReader
Предварительная обработка изображений
Структурный уровень системы FineReader -рукопись, также как и системы FormReader работает на векторном представлении изображения, полученном после его утончения. Утончение и векторизация изображения делаются на этапе, предшествующем распознаванию. Это нарушает основной исходный принцип - ничего не делать до распознавания и вне распознавания, то есть без "понимания". Действительно, в результате "слепого" утончения и векторизации может получаться результат, в определенной (иногда значительной) степени не совпадающий по форме и структуре с исходным изображением.
В описываемой системе это частично компенсируется возможностью при необходимости обращаться непосредственно к исходному растровому изображению. Кроме того, перспективным представляется рассмотрение вопросов о разработке алгоритмов целенаправленной, то есть ориентированной на гипотезу, векторизации либо целенаправленного выделения структурных элементов непосредственно на растровом изображении.
Создание максимально развитого верхнего уровня, в пределе имеющего полную семантическую модель проблемной среды, является общей проблемой для систем моделирования интеллекта.
Априорная векторизация изображения - это не единственный потенциальный источник ошибок. В последнее время в статьях и докладах часто используется придуманное кем-то красивое наукообразное выражение "приведение изображения к виду, удобному для распознавания". Эти слова означают то же самое, что и давно употребляющийся термин "предварительная обработка". Однако в предварительной обработке речь должна идти не об удобстве, а о необходимости или как минимум о целесообразности, т. е. об улучшении качества работы системы. При этом всегда нужно помнить, что априорная предварительная обработка изображения, состоящая в каком-то его изменении еще до распознавания, может быть источником ошибок.
К предварительной обработке относится все, что делается с изображением до его распознавания: считывание, бинаризация, фрагментация, фильтрация, векторизация, отделение объектов от фона и т. п. Для программ, распознающих тексты, это часто еще выравнивание, выделение строк, выделение слов, выделение отдельных символов.
Принятый в описываемой системе чтения рукописных символов общий принцип состоит в том, что "слепые" априорные операции над изображением нужно делать только по необходимому минимуму, поскольку они могут приводить к необратимой потере информации и ошибкам, либо нужно иметь возможность в зависимости от текущего результата возвращаться к исходному изображению.
Считывание изображения происходит с определенным пространственным разрешением. Обычно это около 10 точек на миллиметр. При распознавании маленьких объектов этого разрешения может быть недостаточно, и нужно иметь возможность в зависимости от результатов получать новое изображение с большим пространственным разрешением.
Бинаризация состоит в преобразовании многоградационного по яркости изображения в двоичное, то есть такое, в котором точки фона имеют значение "0", а точки изображения - "1". Преобразование по фиксированному порогу яркости обычно дает плохой результат: на изображении появляются разрывы и заливки в таких местах, где человек воспринимает изображение правильно.
Для улучшения бинаризации применяется переменный порог, выставляемый для каждой точки по результатам анализа свойств изображения в некоторой локальной окрестности. Однако и это может приводить к ошибкам, которые могут исправляться если есть возможность при необходимости обращаться к исходному растровому изображению.
Фильтрация - это очистка изображения от помех - лишних точек и каверн (дырочек) - и, в некоторых случаях, сглаживание контура. Понятно, что в процессе фильтрации может портиться изображение, например, исчезают точки над ё или i. Поэтому фильтрация должна быть осторожной и, как всегда, должна существовать возможность обращения к исходному, не испорченному изображению.
Априорное отделение объекта от других объектов и фона (для текстов - выделение строк, слов и отдельных символов) может быть неоднозначным. В некоторых случаях правильный вариант может попросту отсутствовать. Для описанного выше целенаправленного структурного распознавания выделение отдельных распознаваемых объектов в принципе не нужно - была бы правильная гипотеза в списке гипотез, при этом необязательно на первом месте. Для работы признакового и растрового уровней выделение отдельных объектов нужно. Неоднозначность на этих уровнях может компенсироваться перебором вариантов.
Фрагментация - это выделение на изображении отдельных, последовательно читаемых блоков: заголовков, столбцов, подписей к рисункам, текста в графах таблицы или формы, отделение рисунков и графики от текста и т. п. Уменьшение вероятности ошибки при фрагментации может достигаться за счет использования на этом уровне целостных структурных описаний типов документов и организации целенаправленного процесса их интерпретации. В системе FormReader это в определенной степени реализовано для анализа форм, например, таких как банковские платежные документы.
Одним из источников гипотез для структурного распознавания является предварительное распознавание на растровом уровне. Для растрового распознавания необходима предварительная нормализация размеров и ориентации растрового изображения. Кроме того, важно, чтобы обучение и распознавание проводились не только при одинаковых размерах и ориентации изображений объектов, но и при одной (стандартной) толщине линий. Все это может быть отнесено к предварительной обработке.
Определение толщины линий можно делать различными способами. Если выполнена векторизация изображения, то среднюю толщину линий можно определить, разделив число черных точек (площадь) на длину векторного изображения. Точность этого метода в значительной степени зависит от качества векторизации.
Если изображение состоит из линий (например, графика или текст), то вне зависимости от того, выполнялась или нет векторизация, толщину линий можно вычислять по формуле:

где :  - толщина линий,
- толщина линий,
 - площадь изображения (число черных точек),
- площадь изображения (число черных точек),
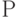 - число точек контура изображения.
- число точек контура изображения.
Длина контура в пикселах может определяться по числу переходов с черного на белое по горизонтали и по вертикали. При RLE -представлении изображения (кодирование сериями) длина контура может определяться по числу горизонтальных и вертикальных RLE -отрезков.
Формула дает удовлетворительную точность, особенно если была выполнена предварительная фильтрация контура.
Практические результаты
Входящая в FormReader программа чтения рукописных текстов была выпущена в 1998 году одновременно с системой ABBYY FineReader 4.0. В настоящее время разработана новая версия, которая входит в состав системы FormReader 6.O. Эта программа может читать все рукописные строчные и заглавные Handprint -символы, имеющиеся на клавиатуре компьютера. Пример читаемых программой символов приведен на рисунке 7.1.
Допускаются ограниченные соприкосновения символов между собой и с графическими линиями. Читаются символы, входящие в алфавиты 15 языков, и при этом учитываются особенности национального письма. Основное практическое применение - распознавание и ввод информации с машиночитаемых бланков.
Достоверность правильного распознавания зависит от качества распознаваемой информации. Для цифр это 99.6-99.8 %. Для русских или английских букв с контекстной обработкой достоверность правильного распознавания в среднем превышает 99 %.
Область возможного применения описанного подхода не ограничивается задачей автоматического анализа изображений, содержащих символьную и графическую информацию. Целостность и целенаправленность на основе предвидения важны при любом восприятии и тем более при восприятии более сложных изображений, например, изображений трехмерных сцен. Эти же принципы важны и при восприятии информации незрительной модальности.
Возможность практической реализации подхода применительно к конкретной задаче зависит от нескольких факторов.
Во-первых, необходима возможность построения полных целостных структурно-метрических описаний классов объектов восприятия, включающих не только элементы целого, но и отношения между ними. Уже отмечалось, что принципиальная отображаемость - это критерий целостности и полноты описаний зрительных образов. Описания должны быть принципиально отображаемыми в объекты своего и только своего класса. Каков критерий целостности и полноты описаний для незрительных,
например, речевых, образов? По-видимому, таким критерием может быть принципиальная воспроизводимость. Слово "принципиальная" говорит о том, что в описаниях достаточно информации для отображения (воспроизведения) и что реальное отображение (воспроизведение) в принципе могло бы быть реализовано.
Во-вторых, для реализации целостного целенаправленного восприятия должна иметься возможность выделять структурные элементы и проверять отношения между ними непосредственно в среде восприятия.
И наконец, желательно, чтобы в системе было максимально полное описание проблемной среды, используемое как на этапе формирования гипотез, так и на этапе их проверки. В пределе описание среды должно стать активной моделью среды. Связанные с этим вопросы подробно рассматриваются в последующих разделах.
Владислав Нагорный
Лариса Парфенова
|
1) Можно ли экстерном получить второе высшее образование "Программная инженерия" ? 2) Трудоустраиваете ли Вы выпускников? 3) Можно ли с Вашим дипломом поступить в аспирантуру?
|