Инспектор

Вы можете этот курс.
Опубликован: 25.11.2008 | Уровень: для всех | Доступ: платный
Лекция 9:
Физические модели баз данных
Структуры хранения данных в SQL Server 7.0
В новой версии сервера баз данных фирма Microsoft реализовала абсолютно новый механизм хранения.
SQL Server 7.0 организует следующую иерархию хранения:
- База данных — некоторый объем физического пространства, на котором размещаются данные, принадлежащие одной логической базе данных.
- Файл. Каждая база данных содержит не менее двух файлов. Один из них отводится под журнал транзакций. И в отличие от версии 6.5 в новой версии журнал транзакций не может располагаться в одном файле с данными. И еще одно принципиальное отличие — в новой версии каждый файл может принадлежать только одной базе данных, у нас не может быть разделяемых файлов.
- Страница. Файлы делятся на страницы размером по 8 Кбайт каждая. Логический номер страницы складывается из внутреннего номера базы данных, номера файла и номера страницы в файле. В рамках БД файлы нумеруются, начиная с 1, и так же нумеруются страницы в рамках файла.
- Блоки (экстенты, extents). Пространство под объекты отводится блоками по 8 следующих друг за другом страниц. Блок является основной единицей отведения пространства. Поэтому при создании БД можно указывать размер файла с точностью до 64 Кбайт. Для суперкомпьютеров заложена возможность увеличения размера блоков до 128 страниц.
В отличие от версии 6.5 объекты БД не обязательно занимают целый блок. На начальном этапе заполнения объект может занимать внутри блока несколько страниц. Поэтому существуют два типа блоков:
- Однородные (Uniform). Все страницы однородного блока принадлежат одному объекту БД.
- Смешанные (Mixed). Разные страницы в блоке принадлежат разным объектам.
Когда объект создается, то обычно его первые страницы отводятся в смешанном блоке, по мере роста объекта он уже размещается в однородных блоках.
В SQL 7.0 существуют уже 7 типов страниц:
- страница данных (Data page);
- индексные страницы (Index page);
- страницы журнала транзакций (Log page);
- текстовые страницы (Text/image page);
- карты распределения блоков (Global allocation map page);
- карты свободного пространства (Page free space page);
- индексные карты размещения (Index allocation map page).
Все страницы имеют заголовок размером 96 байтов. В заголовке хранится общая информация, используемая ядром СУБД для работы со страницами. На странице в отличие от блока хранится однородная информация. Поэтому среди параметров страницы задаются:
- номер страницы в формате <номер файла, номер страницы>;
- идентификатор объекта, которому принадлежит страница;
- номер индекса, которому принадлежит страница;
- уровень внутри индексного дерева, которому принадлежит страница;
- количество отведенных строк на странице, количество заполненных слотов;
- общий объем свободного пространства на странице;
- указатель на расположение свободного пространства после последней строки на странице;
- минимальная длина строки на странице;
- объем зарезервированного пространства.
После заголовка следует информация о статусе страницы в картах распределения блоков и карте свободного пространства.
Новыми в архитектуре дисковой памяти являются страницы размещения. В этих страницах хранятся сведения о размещении данных. SQL Server 7.0 использует три типа страниц размещения: карты распределения блоков, карты свободного пространства, индексные карты размещения. SQL Server 7.0 хранит информацию размещения на разных уровнях: на уровне блоков, на уровне страниц, на уровне объектов. Такой разносторонний мониторинг помогает СУБД оптимизировать работу в соответствии с требованиями конкретного запроса.
Карты распределения блоков
В данных картах хранится информация о распределении блоков. Карта распределения блоков состоит из стандартного заголовка и одного битового массива в 64 000 битов. Каждый бит характеризует один блок. Поэтому одна страница карты распределения описывает пространство в 64 000 блоков или 4 Гбайт данных.
Карты распределения блоков делятся на два типа:
- Глобальная карта распределения (Global allocation map, GAM) хранит информацию об использовании блоков. Если бит установлен в 0, то блок занят данными, если в 1 — то блок свободен.
- Вторичная глобальная карта распределения (Secondary global allocation map, SGAM) хранит информацию о типе блоков. Если бит установлен в 1, то блок смешанный и минимум одна страница в нем свободна, в остальных случаях (блок свободен, блок смешанный, но свободных страниц нет, блок однородный) бит равен 0.
При отведении пространства сервер использует обе карты распределения.
Карты свободного пространства
Степень заполнения страниц в SQL 7.0 отслеживает специальный механизм — карты свободного пространства (Page free space page, PFS). Каждая PFS-страни-ца хранит информацию о 8000 страниц, по 1 байту на страницу. Каждый байт представляет собой битовую карту, которая сообщает о степени занятости страницы и о том, принадлежит ли она объекту.
Первые страницы файла БД всегда используются под карты распределения. Страница 1 состоит из двух частей. После стандартного заголовка страницы следует заголовок файла, содержащий его описание, затем размещается блок PFS. Страницы PFS повторяются через каждые 8000 страниц, если размер файла превосходит один блок. Страница 2 — это GAM, страница ? 3 — это SGAM. Карты распределения блоков повторяются через каждые 512 000 страниц. Кроме того, каждая девятая страница первичного файла — это загрузочная страница БД (database boot page), содержащая описание БД и параметры конфигурации.
Карты размещения
Для организации связи между блоками и расположенными на них объектами используются индексные карты размещения (Index Allocation Map, IAM). Каждая таблица или индекс имеют одну или более страниц IAM. В каждом файле, в котором размещаются таблица или индекс, существует минимум одна карта размещения для этой таблицы или индекса. Страницы IAM размещаются произвольно внутри файла и отводятся по мере необходимости. IAM объединены друг с другом в цепочку двунаправленными ссылками. Указатель на первую карту размещения содержится в поле FirstIAM системной таблицы Sysindex.
Каждая IAM описывает некоторый диапазон блоков и представляет собой битовую карту: если бит установлен в 1, то в данном блоке есть страницы, принадлежащие данному объекту, если в 0 — то нет.
Все страницы размещения не связаны напрямую с некоторым объектом БД, они соответствуют некоторой системной информации, поэтому параметр "идентификатор объекта" для всех этих страниц одинаков и равен 99.
Страницы данных
На самом общем уровне здесь, так же как и в предыдущей версии, страница данных делится на 3 зоны: заголовок, область данных и таблицу смещений, но размер страницы увеличен, размер заголовка также и некоторые отличия существуют и в структуре остальных зон.
Прежде всего стоит отметить, что в отличие от SQL Server 6.5 в новой версии страницы данных не связаны друг с другом в цепочки. За связь между страницами и объектами отвечает новая специальная структура — карты размещения.
Кроме того, ранее данные на странице хранились непрерывно. При удалении строки данные внутри страницы перемещались так, чтобы не оставалось пустот. Однако такой подход затруднял строчные блокировки. И в новой версии данные на странице не обязательно хранятся непрерывно. Здесь допустимы пропуски. При удалении строки пустое пространство помечается и потом его может занять новая строка, но перемещения строк не происходит.
В SQL Server 7.0 теперь поддерживается классический термин слот (Slot), и это место размещения строки на странице. Если таблица не имеет кластеризованного индекса, то номер слота является идентификатором строки и не меняется, пока не будет удалена соответствующая строка. Если же таблица имеет кластеризованный индекс, то слоты располагаются в порядке, задаваемом индексом.
Строки данных
Строки данных претерпели существенное изменение. Отметим наиболее важные моменты.
- Номера строки больше нет — строка идентифицируется номером слота, который ее определяет, либо значением кластерного ключа.
- В версии 6.5 поля, допускающие NULL, хранятся точно так же, как поля переменной длины. В версии 7.0 поля фиксированной длины всегда занимают свою полную длину, значение NULL задается специальным флагом. Это облегчает замену неопределенного значения на некоторое конкретное без перемещения строк на странице.
- Фиксированные поля вместе с описателями хранятся до полей переменной длины, так же как и в 6.5.
- В каждой строке хранится общая длина строки и текущие длины полей переменной длины. Отсутствуют таблицы смещений и подстройки смещений. Данные считываются последовательно с начального адреса.
- Максимальное количество полей в строке 1024, в версии 6.5 только 256.
Текстовые страницы
В версии 7.0 изменены принципы хранения текстовых полей. Строки данных по-прежнему содержат 16-байтные указатели на текстовые данные. Однако хранение самих текстовых данных производится иначе.
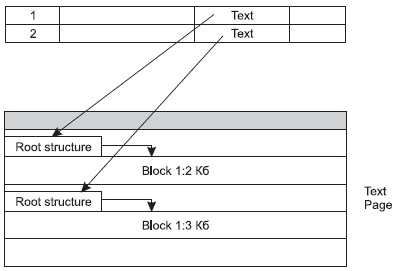
Текстовая страница теперь может содержать несколько текстовых полей. Собственно данные хранятся в виде сбалансированного дерева (B-tree). Строка данных содержит указатель на корневую структуру (Root structure) размером 84 байта.
Данные длиной менее 64 байт хранятся в корневой структуре. Для данных до 32 Кбайт корневая структура (Root structure) может адресовать 4 блока данных (это не блоки страниц) до 8 Кбайт каждый. Блоки наращиваются до 8 Кбайт (реально на одной текстовой странице может быть размещено 8080 байт). Например, если первая порция данных составляет 4 Кбайта, то отводится один блок. Если в дальнейшем данные увеличиваются до 6 Кбайт, то первый блок увеличивается до 6 Кбайт, а второй блок имеет размер всего 2 Кбайта.
Если же длина текстового поля более 32 Кбайт, то строятся промежуточные узлы.
В версии 7.0 текстовая страница может содержать данные нескольких текстовых полей (рис. 9.18).
Страницы журнала транзакций
В отличие от версии 6.5 в новой версии под журнал транзакций отводится всегда отдельный файл. В предыдущей версии журнал транзакций являлся системной таблицей и хранился в системном сегменте LOG. Несмотря на настоятельные рекомендации располагать журнал транзакций и файлы базы данных на разных физических устройствах, СУБД автоматически не контролировала этот факт. В новой версии журнал транзакций всегда хранится в отдельном файле.
Архитектура разделяемой памяти
По причинам объективно существующей разницы в скорости работы процессоров, оперативной памяти и устройств внешней памяти (эта разница в скорости существовала, существует и будет существовать всегда) буферизация страниц базы данных в оперативной памяти — единственный реальный способ достижения удовлетворительной эффективности СУБД.
Операционные системы создают специальные системные буферы, которые служат для кэширования пользовательских процессов. Однако стратегия буферизации, применяемая в операционных средах, не соответствует целям и задачам СУБД, поэтому для оптимизации обработки данных одной из главных задач СУБД является создание эффективной системы управления процессом буферизации.
Разделяемая память, управляемая СУБД, состоит из нескольких типов буферов:
- Буферы страниц данных, которые содержат копии страниц данных, с которыми работает СУБД.
- Буферы страниц журнала транзакций, которые отражают процесс выполнения транзакции — последовательности операций над БД, переводящей БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
- Системные буферы, которые содержат общую информацию о БД, о пользователях, о физической структуре БД, о базе метаданных.
Информация в буферах взаимосвязана, и требуется эффективная система поддержки единой работы всех частей разделяемой памяти.
Если бы запись об изменении базы данных реально немедленно записывалась во внешнюю память, это привело бы к существенному замедлению работы системы.
Поэтому записи в журнал тоже буферизуются: при нормальной работе очередная страница выталкивается во внешнюю память журнала только при полном заполнении записями.
Но реальная ситуация является более сложной. Имеются два вида буферов — буфер журнала и буфер страниц оперативной памяти, которые содержат связанную информацию. И те и другие буферы могут выталкиваться во внешнюю память. Проблема состоит в выработке некоторой общей политики выталкивания, которая обеспечивала бы возможности восстановления состояния базы данных после сбоев.
Буфера не выделяются для каждого пользовательского процесса, они выделяются для всех процессов сервера БД. Это позволяет увеличить степень параллелизма при исполнении клиентских процессов.
Разделяемая память наиболее эффективно используется вспомогательными процессами сервера, иногда называемыми демонами, которые используются для синхронизации взаимодействующих процессов на сервере.
На этом мы закончили рассмотрение физических моделей, применяемых в базах данных. Физические модели большей частью скрыты от пользователей. Однако в SQL существует команда создания индексных файлов. При этом по умолчанию стандартно создаются индексные файлы для первичных ключей, для вторичных ключей индексные файлы создаются дополнительной командой CREATE INDEX, которая имеет следующий формат:
CREATE [UNIQUE] INDEX <имя_индекса> ON <имя_таблицы>
( <имя_столбца>[<признак упорядочения>] |
[,<имя_столбца>[<признак упорядочения>]...])
<имя_индекса > — уникальный идентификатор в системе.
<Признак упорядочения>::={ASC | DESC}Здесь ASC — признак упорядочения по возрастанию, DESC — признак упорядочения по убыванию значений соответствующего столбца в индексе.
Индекс может быть удален командой DROP, которая имеет следующий формат: DROP INDEX <имя_индекса>
Елена Сидорова
| Россия, Чебоксары, Чувашский государственный университет им. И.Н. Ульянова, 2005 |