





|
Добрый день! Подскажите пожалуйста как и когда получить диплом, после сдичи и оплаты????? |
Инспектор
Вы можете этот курс.
Опубликован: 07.08.2007 | Уровень: специалист | Доступ: платный | ВУЗ: Московский физико-технический институт
Лекция 2:
Особенности и алгоритмы кодирования голоса
Аннотация: Особенности и методы кодирования голоса. Дифференциальные и адаптивные методы кодирования голоса. Дельта модуляция. Эхо-компенсация, эквилизация, эффект маскирования, VoCoDER, алгоритмы работы каналов.
Ключевые слова: АЦП, поток, бит, функция, law, мощность, очередь, ИКМ, ADPCM, диапазон, модуляция, ЦАП, входной, дифференциальный усилитель, PCM, счетчик, vocoder, adaptive, differential, pulse, кодирование, digital, versatility, disk, DVD, интерфейс, instrument, digital interface, MIDI, байт, masking, pattern, banding, AND, ISO, picture, expert, group, MUSICAM, ПО, определение, разбиение, исполнение, Дополнение, связь, объект, global, system, mobile communications, алгоритм, true, speech, доступ, программное обеспечение, UDP, Интернет, DiffServ, IntServ, RSVP-TE, поиск, запись, процессор, сеть, real, TIME, protocol, real-time control, RTP, resource, разделы, IETF, CLNP, ATM, IPX, безопасность, CSMA/CD, RTCP, RSVP, сетевая инфраструктура, модуль, маршрутизатор, ISDN, gatekeeper, акустические волны, длина, метод модуляции, волновое сопротивление, источники шума, шумы, полоса пропускания, отношение, модем, терминальное оборудование, NEXT, crosstalk, FEXT, кабель, ISI, intersymbol interference, эквалайзер, decision, feedback, equalizer, значение, full duplex, time division, duplex, frequency, division, вычитание, улучшение, эквилизация, Ethernet, транзистор, ключ, быстродействие, pipelining, адрес, конвейерная обработка, качество обслуживания, стоимость, буфер, место, аналогия, TCP, ICMP, скорость передачи, процент, оптимизация, frame relay, маршрут, путь, сценарий, сетевой уровень, канальный уровень, кадр, сетевой интерфейс, таймер, базовая, двусторонний обмен, загрузка, вероятность, группа, список, запрос, NAK, RTT, дисперсия, IBM, Data, link control, ANSI, advanced, communication, control, procedure, high-level, CCITT, HDLC, поле, идентификатор, точка-точка, SUM, CRC, Размещение, равенство, SLIP, PPP, коммутатор, иерархия, граф, кратчайший путь, переключатель, блокировка, TDM, домен, таблица, демультиплексор, ячейка, время доступа, архивация, обратное преобразование
Эмпирически установлено, что для удовлетворительного воспроизведения речи достаточно 4096 уровней квантования сигнала (12 разрядов АЦП). Такое разрешение диктуется большим динамическим диапазоном сигналов. Но упомянутая выше логарифмическая зависимость чувствительности нашего слуха открывает возможность преобразования 12-битных кодов в 8-битные, что формирует информационный поток в 64 Кбит/ c (8 КГц*8 бит). Для этого используется логарифмическое преобразование. Такое преобразование наталкивается на определенные трудности при низких значениях входного сигнала, ведь логарифм для значений меньше 1 имеет отрицательную величину, функция же преобразования должна пройти через нуль. В США принята методика, когда две логарифмические кривые смещаются в направлении оси ординат (вертикальная ось), в результате получается функция вида
 |
(так называемая 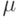 -зависимость [ -law]) -зависимость [ -law]) |
| В Европе используется функция преобразования вида | |
 |
в области значений 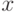 вблизи нуля вблизи нуля |
 |
при "больших" значениях (  -зависимость [ -law], см.
рис.
2.1) -зависимость [ -law], см.
рис.
2.1) |
Для дальнейшего упрощения процесса преобразования реальные кривые аппроксимируются последовательностью отрезков прямых, наклоны которых каждый раз меняется вдвое. На практике функция табулируется (рекомендация G.711), и отличия - и -функций пренебрежимо малы. Здесь используются так называемые look-up таблицы. Но следует учитывать, что при реализации практической связи между Европой и Америкой, например телефонной, необходим 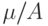 -конвертор.
-конвертор.
Для кодирования применяется симметричный код, у которого первый бит характеризует полярность сигнала. Ограниченная мощность человеческих голосовых связок приводит к тому, что сигнал характеризуется небольшими вариациями производной. А это в свою очередь вызывает довольно большую корреляцию значений результатов последовательных стробирований и цифрового преобразования.
Дальнейшим усовершенствованием схемы ИКМ (импульсно-кодовой модуляции) является адаптивный дифференциальный метод кодовоимпульсной модуляции ( рис. 2.2). Здесь преобразуется в код не уровень сигнала в момент времени ti, а разница уровней — в моменты ti и ti-1.
Так как обычно сигнал меняется плавно, можно заметно сократить необходимое число разрядов АЦП. Принципиальное отличие между ИКМ и ADPCM (1984 год) заключается в использовании адаптивного АЦП и дифференциального кодирования соответственно. Адаптивный АЦП отличается от стандартного ИКМ -преобразователя тем, что в любой момент времени уровни квантования расположены однородно (а не логарифмически), причем шаг квантования меняется в зависимости от уровня сигнала. Применение адаптивного метода базируется на том, что в человеческой речи последовательные уровни сигнала не являются независимыми. Поэтому, преобразуя и передавая лишь разницу между предсказанным и реальным значением, можно заметно снизить загрузку линии, а также требования к широкополосности канала. Следует иметь в виду, что метод не лишен серьезных недостатков: уровень шумов, связанный с квантованием сигнала, выше, а при резких изменениях уровня сигнала, превышающих диапазон АЦП, возможны серьезные искажения.
Расширение диапазона преобразования достигается умножением шага квантования на величину несколько больше (или меньше) единицы.
При дифференциальном преобразовании на вход кодировщика подается не сам сигнал, а разница между текущим значением сигнала и предыдущим ( рис. 2.3).
Блок прогнозирования является адаптивным фильтром, который использует предшествующий код для оценки последующего стробирования. На вход кодировщика поступает сигнал, пропорциональный разнице между входным сигналом и предсказанием. Чем точнее предсказание, тем меньше бит нужно, чтобы с требуемой точностью закодировать эту разницу. Характер человеческой речи позволяет заметно снизить требования к каналу при использовании адаптивного дифференциального преобразователя.
Дельта-модуляция представляет собой вариант дифференциальной импульсно-кодовой модуляции, где для кодирования разностного сигнала используется только один бит. Этот бит служит для того, чтобы увеличить или уменьшить оценочный уровень. Примером реализации дельта-модуляции может служить схема, показанная на рис. 2.4. Сигнал ЦАП отслеживает входной сигнал in(t). Здесь компаратор заменил дифференциальный усилитель, который используется в дифференциальном импульсно-кодовом модуляторе.
Если скорость нарастания входного сигнала велика, то уровень на выходе ЦАП будет отставать и сможет нагнать In(t), только когда входной сигнал начнет уменьшаться. Данный метод не является разумной альтернативой PCM. Для улучшения характеристик дельта-преобразователя реверсивный счетчик можно заменить цифровым процессором, при этом шаг S становится переменным, но кратным некоторому базовому значению.
Существуют много других способов кодирования человеческого голоса, среди них наиболее эффективный реализован в приборах, носящих название "вокодер" (VOCODER).
Для компактных музыкальных дисков ( CD ) характерна полоса 50 Гц - 20 КГц, обычная же речь соответствует полосе 50 Гц - 7 КГц. Только звуки типа Ф или С имеют заметные составляющие в высокочастотной части звукового спектра. Для высококачественной передачи речи используется субдиапазонный ADPCM -преобразователь (Adaptive Differential Pulse Code Modulation). В нем звук сначала стробируется с частотой 16 КГц, производится преобразование в цифровой код с разрешением не менее 14 бит, а затем подается на квадратурный зеркальный фильтр ( QMF ), который разделяет сигнал на два субдиапазона (50 Гц - 4 КГц и 4 КГц - 7 КГц). Диапазоны этих фильтров перекрываются в области 4 КГц. Нижнему диапазону ставится в соответствие 6 бит (48 Кбит/с), а верхнему - 2 бита (16 Кбит/с). Выходы этих фильтров мультиплексируются, формируя поток 64 Кбит/с.
На CD используется 16-битное кодирование с частотой стробирования 44,1 КГц, что создает информационный поток 705 Кбит/c. Следует иметь в виду, что кодирование даже со столь высоким разрешением создает шум дискретизации. В результате достигается качество звука, вполне удовлетворительное для человека. Собаки и дельфины, пожалуй, этого бы не сказали, так как их диапазон чувствительности распространяется до более высоких частот.
Можно подумать, что для стереосигнала этот поток удвоится (1,411 Мбит/с). Практически это не так: сигналы в стереоканалах сильно коррелированы, и можно кодировать и передавать лишь их разницу; на практике высокочастотные сигналы каналов суммируются, для различия каналов передается код их относительной интенсивности. Исследования показывают, что для акустического восприятия тонкие спектральные детали важны лишь в окрестности 2 КГц.
Помимо CD-аудиостандарта появился сначала стандарт Dolby Surround, Dolby ProLogic, а позднее DVD (Digital Versatile Disk), который предлагает 6-канальный звук (для домашних кинотеатров). Стандартный DVD имеет емкость 4,7 Гбайт (133 минуты видеовоспроизведения), имеются версии с емкостью до 27 Гбайт. Конечно, о передаче аудио/видеосигнала в таком формате речь пока не идет — ведь это требует дополнительной полосы пропускания. Но трудно сказать, чего следует ожидать в самом ближайшем будущем.
Многие музыкальные инструменты в настоящее время имеют цифровой интерфейс. Разработан единый стандартный интерфейс музыкальных инструментов MIDI (Music Instrument Digital Interface). Стандарт определяет тип разъема, кабеля и формат сообщений. Каждое сообщение MIDI состоит из статусного байта, за которым следует нуль или более байтов данных. Сообщение MIDI передает данные о музыкально значимом событии. Типичным событием может быть нажатие клавиши, перемещение смычка, нажатие или отпускание педали. Статусный байт индицирует событие, а байты данных определяют параметры события, например код нажатой клавиши или скорость перемещения. Каждый тип инструмента имеет свой уникальный код, например, для фортепьяно — 0, для маримбы — 12, а для скрипки — 40. Всего определено 127 инструментов, хотя некоторые из них не являются собственно инструментами, а представляют собой источники различного типа шума. Центральным узлом каждой MIDI-системы является синтезатор (часто это ЭВМ), который воспринимает сообщения и осуществляет синтез звука. Синтезатор должен воспринимать любой из 127 кодов музыкальных инструментов. Преимущество применения стандарта MIDI при цифровой передаче звука заключается в существенном сокращения потока данных (до 1000 раз). Недостатком MIDI является необходимость наличия соответствующего синтезатора на принимающей стороне. Разные синтезаторы могут выдать несколько разный результирующий сигнал. Музыка, конечно, лишь одна из разновидностей звуков.
Для передачи звуковой информации с учетом этих факторов был разработан стандарт Musicam (Masking pattern Universal Sub-band Integrated Coding And Multiplexing), который согласуется с ISO MPEG (Moving Picture Expert Group; стандарт ISO 11172). Musicam развивает идеологию деления звукового диапазона на субдиапазоны, здесь 20 КГц делится на 32 равных интервала. Логарифмическая чувствительность человеческого уха и эффект маскирования позволяет уменьшить число разрядов кодирования. Эффект маскирования связан с тем, что в присутствии больших звуковых амплитуд человеческое ухо нечувствительно к малым амплитудам близких частот. Причем чем ближе частота к частоте маскирующего сигнала, тем сильнее этот эффект (см. рис. 2.5). Сплошной линией на рисунке показана нормальная зависимость порога чувствительности уха, а пунктиром — зависимость порога чувствительности в присутствии 500-герцного тона с амплитудой в 110 дБ.
При разбиении на субдиапазоны можно оценить эффект маскирования и передавать только ту часть информации, которая этому эффекту не подвержена. При этом уровень ошибок квантования следует держать лишь ниже порога маскирования, что также снижает информационный поток. Для стробирования высококачественных звуковых сигналов используются частоты 32, 44,1 или 48 КГц. Стандартом предусмотрено три уровня кодирования звука, отличающиеся по сложности и качеству. На первом уровне производится разбивка на 32 диапазона, определение диапазонных коэффициентов и формирование кадров, несущих по 384 результата стробирования. Уровень 2 формирует кадры с 1152 результатами стробирования и дополнительными данными. Уровень 3 допускает динамическое разбиение на субдиапазоны и уплотнение данных с использованием кодов Хафмана. Любой декодер способен работать на своем и более низком уровне.
Илья Сидоркин
Наталья Шульга
|
Курс "информационная безопасность" . Можно ли на него записаться на ПЕРЕПОДГОТОВКУ по данному курсу? Выдается ли диплом в бумажном варианте и высылается ли он по почте? |