
|
При прохождении теста 1 в нем оказались вопросы, который во-первых в 1 лекции не рассматривались, во-вторых, оказалось, что вопрос был рассмаотрен в самостоятельно работе №2. Это значит, что их нужно выполнить перед прохождением теста? или это ошибка? |
Инспектор
Спонсор: Intel
Вы можете этот курс.
Опубликован: 20.08.2013 | Уровень: для всех | Доступ: платный | ВУЗ: Новосибирский Государственный Университет
Лекция 5:
Введение в библиотеку IPP
Аннотация: В лекции приводится подробное описание структуры библиотеки IPP, модели ее использования. Описываются основные типы данных и функций, даны примеры работы с ними. Приведен пример создания приложения в среде MICROSOFT VISUAL STUDIO 2010.
Презентацию к лекции Вы можете скачать здесь.
1. Обзор библиотеки Intel IPP
1.1. Обзор библиотеки
Одним из популярных вариантов использования современных ЭВМ является выполнение мультимедийных приложений. Кодирование и декодирование видео- и аудиоданных, обработка изображений и сигналов зачастую требует значительного объема вычислительных ресурсов, что может накладывать определенные ограничения на используемое программное обеспечение. Другим немаловажным фактором, требующим эффективного использования вычислительных ресурсов, является время автономной работы мобильного устройства (ноутбука, планшетного компьютера, смартфона).
Необходимо отметить, что многие высокоуровневые алгоритмы обработки мультимедиа данных в итоге сводятся к базовым операциям над простыми структурами (например, массивами), прич?м производительность этих операций существенно влияет на производительность алгоритма в целом. Некоторые из базовых операций могут использоваться различными высокоуровневыми алгоритмами. Исходя из этих факторов, представляется целесообразным выполнять оптимизацию именно низкоуровневых функций. Данный подход лежит в основе разработанной компанией Intel библиотеки Integrated Performance Primitives [ 1 ], которая представляет собой набор кроссплатформенных библиотек, содержащих большое количество низкоуровневых оптимизированных под Intel CPU функций, которые могут быть использованы при разработке различных мультимедийных приложений таких как:
- Видео-кодеки: H.264, MPEG2, MPEG4, VC-1
- Аудио-кодеки: AAC, AC3, MP3
- Сжатие изображений (кодеки JPEG, JPEG2000, JPEGXR)
- Обработка изображений
- Обработка сигналов
- Сжатие естественной речи (кодеки AMR, AMR-WBE, G.711, G.722, G.723. G.726, G.728, G.729, GSM-AMR, GSM-MFR)
- Криптографические приложения
1.2. Структура библиотеки и модель использования
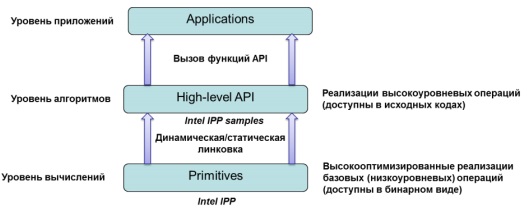
Как было сказано выше, библиотека Intel IPP представляет собой набор оптимизированных реализаций базовых (низкоуровневых) операций (данные реализации поставляются в бинарном виде). Логически библиотеку можно разделить на 3 больших модуля: обработка сигналов (одномерных массивов), обработка изображений и видео, операции над матрицами небольшого размера и реалистичный рендеринг. Для того чтобы облегчить процесс разработки ПО с использованием библиотеки, отдельно в виде исходных кодов поставляются высокоуровневые API для аудио и видеокодеков, функций обработки изображений и речи. Данные API могут быть использованы при разработке собственных приложений. Графически модель использования библиотеки представлена на Рис. 1.
1.3. Типы данных и именование функций
Имена функций в библиотеке Intel IPP имеют следующую структуру:
ipp<data-domain><name>|_<datatype>||_<descriptor>|(<parameters>)
Рассмотрим подробнее назначение отдельных частей в данной структуре.
<data-domain> - тип обрабатываемых данных:
- s (signal) – одномерный массив
- i (image, video) – двухмерный массив пикселей
- m (matrice) – матрицы или вектора
- r – исходные данные для функций реалистичного рендеринга изображений и обработки 3D данных (представление данных зависит от используемой функции)
Примеры: ipps, ippi, ippm, ippr
<name> = <operation>[_modifier] - имя функции:
- <operation> - символическое название выполняемой операции
- modifier (дополнительный параметр) – дополнительная спецификация функции
Примеры: Copy, Malloc, DCTFwd_CToC (прямое дискретное косинус-преобразование, в котором входные и выходные значения являются комплексными)
<datatype> = <bit_depth><bit_interpretation> – тип обрабатываемых данных:
- <bit_depth> = 1|8|16|32|64 (размер элемента данных (в битах))
- <bit_interpretation> = <u|s|f>[c]
- u – целые числа без знака
- s – целые числа со знаком
- f – вещественные числа
- c – комплексные числа
Intel IPP поддерживает следующие типы данных:
| Тип | Тип C/++ | Тип Intel IPP |
|---|---|---|
| 8u | unsigned char | Ipp8u |
| 8s | signed char | Ipp8s |
| 16u | unsigned short | Ipp16u |
| 16s | signed short | Ipp16s |
| 16sc | complex short | Ipp16sc |
| 32u | unsigned int | Ipp32u |
| 32s | signed int | Ipp32s |
| 32f | float | Ipp32f |
| 32fc | complex float | Ipp32fc |
| 64s | __int64 (long long) | Ipp64s |
| 64f | double | Ipp64f |
| 64fc | complex double | Ipp64fc |
В случае, если у функции есть несколько аргументов разных типов (или тип выходных данных отличается от типа входных данных), используется следующий формат типа обрабатываемых данных: <datatype> = <src1Datatype>[src2Datatype][dstDatatype]
<descriptor> - описание дополнительных особенностей данных, обрабатываемых функцией
Примеры:
M – используется маска, определяющая пиксели изображения, которые будут обработаны функцией
R – функция обрабатывает определенную область изображения (ROI – region of interest)
<parameters> – параметры функции; указываются в следующем порядке:
- входные аргументы
- выходные аргументы
- дополнительные аргументы
Рассмотрим функцию ippiCopy_8u_C3R. Согласно описанной выше структуре, данная функция копирует ( <name> = Copy) изображение (ippi, <data_domain> = i), элементами которого являются 8-битные целые числа без знака (<data_type> = 8u). Изображение является трехканальным (C3, <descriptor> = C3R), копирование осуществляется из заданной области изображения (R, <descriptor> = C3R).
Александра Максимова
Алена Борисова
|
В лекции по обработке полутоновых изображений (http://www.intuit.ru/studies/courses/10621/1105/lecture/17979?page=2) увидела следующий фильтр:
В описании говорится, что он "делает изображение более чётким, потому что, как видно из конструкции фильтра, в однородных частях изображение не изменяется, а в местах изменения яркости это изменение усиливается". Что вижу я в конструкции фильтра (скорее всего ошибочно): F(x, y) = 2 * I(x, y) - 1/9 I(x, y) = 17/9 * I(x, y), где F(x, y) - яркость отфильтрованного пикселя, а I(x, y) - яркость исходного пикселя с координатами (x, y). Что означает обычное повышение яркости изображения, при этом без учета соседних пикселей (так как их множители равны 0). Объясните, пожалуйста, как данный фильтр может повышать четкость изображения? |
