Алгоритмы сжатия изображений без потерь
13.5. Алгоритмы статистического кодирования
Алгоритмы статистического кодирования ставят в соответствие каждому элементу последовательности код так, чтобы его длина соответствовала вероятности появления элемента. Таким образом, сжатие происходит за счет замены элементов исходной последовательности, имеющих одинаковые длины (каждый элемент занимает одинаковое количество бит), на элементы разной длины, пропорциональной отрицательному логарифму от вероятности, т.е. элементы, встречающиеся чаще, чем остальные, будут иметь код меньшей длины. Согласно теореме Шеннона о кодировании источника без помех [5], оптимальная длина такого кода есть - logs p, где p - вероятность появления элемента во входной последовательности, а s - основание системы счисления, в которой представляется закодированный элемент (код элемента).
Алгоритм Хаффмена
Алгоритм Хаффмена8Huffman coding. Автор алгоритма - Давид Хаффмен (David A. Huffman). Опубликован в 1952 году. использует особый вид представления элементов - префиксный код. Префиксный код - это код переменной длины, обладающий особым свойством - свойством префикса: менее короткие коды не совпадают с префиксом (начальной частью) более длинных. Такой код позволяет осуществлять взаимно-однозначное кодирование. Соответственно, требуется построить способ сжатия, использующий префиксный код и при этом обеспечивающий максимально возможную степень сжатия. Формализуем задачу.
Дано на входе:
Алфавит A = {a1, . . . , an}.
Множество P = {p1, . . . , pn} - распределение вероятностей появления или таблица количеств элементов из A, pi = Prob(ai),  . Далее
. Далее  будем называть весом ai.
будем называть весом ai.
Необходимо на выходе:
Код (алфавит) H(A, P) = {h1, . . . , hn} - набор кодов (далее бинарных), так что hi = Code(ai), .
Задача:
Пусть  , где l(hi) - длина кода hi. S(H) - взвешенная длина пути (пояснение данного термина см. ниже).
, где l(hi) - длина кода hi. S(H) - взвешенная длина пути (пояснение данного термина см. ниже).
Требуется, чтобы H было оптимально, т.е.

Алгоритм Хаффмена является решением данной задачи [36], [37].
Построение набора кодов обычно осуществляется с помощью так называемых кодовых деревьев. Предположим, что используются бинарные коды, тогда дерево будет бинарным (в общем случае степень ветвления зависит от основания системы счисления представления кодов). Терминальные узлы дерева содержат сам элемент алфавита, его вес, ссылку на родительский узел (впрочем, это зависит от конкретной реализации). Внутренние узлы содержат сумму весов своих узлов-потомков, ссылку на узлы-потомки и, возможно, ссылку на родительский узел. Ребрам дерева сопоставляются ноль и единица, для левых и правых соответственно. Полностью достроенное дерево имеет n терминальных узлов и n - 1 внутренних. Совершая проход от корня до терминального узла и выписывая по пути 0 и 1 для встречающихся ребер, получим код элемента в терминальном узле.
Теперь стал понятен смысл названия S(H), т.к. длина кода l(hi) суть длина пути от корня до соответствующей терминальной вершины.
Опишем алгоритм построения кодового дерева Хаффмена.
- Создать n терминальных узлов по числу элементов в алфавите. В каждый узел записать соответствующие веса.
- Создать родительский узел и соединить с ним два свободных (т.е. не имеющих родителей) узла с минимальными весами, записав в него сумму весов непосредственных потомков.
- Если количество свободных узлов больше одного, то перейти к пункту 2. Иначе данный узел - корень дерева Хаффмена.
Процесс сжатия заключается в замене каждого элемента входной последовательности его кодом. Сожмем следующую строку "TOBEORNOTTOBE".
- Составим таблицу весов:
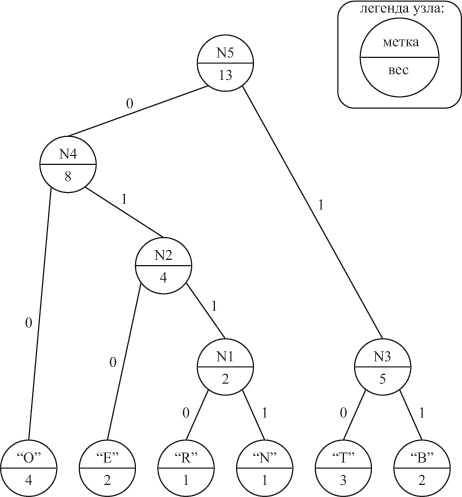
- Построим дерево Хаффмена (см. рис. 13.1):
- проинициализируем дерево терминальными узлами,
- создадим родительский узел N1 для узлов элементов "N" и "R" с весом 2 ;
- создадим родительский узел N2 для узла элемента "E" и узла N1 с весом 4 ;
- создадим родительский узел N3 для узлов элементов "Т" и "B" с весом 5 ;
- создадим родительский узел N4 для узла элемента "O" и узла N2 с весом 8 ;
- создадим родительский узел N5 для узлов N3 и N4 c весом 13.
- Проведем кодирование. Составим для удобства таблицу кодов: Следовательно, получим последовательность "10 00 11 010 00 0110 0111 00 10 10 00 11 010".
Полученная последовательность имеет длину 32 бита. Исходная, если считать алфавитом набор ASCII - 104 бита, если считать алфавитом только набор "TOBERN" - 39 бит.
Заметим, что в процессе построения дерева возникала неоднозначность в выборе двух узлов для обработки. В нашем примере выбор был сделан в пользу наглядности представления, однако никакого влияния на качество сжатия оно не оказывает.
Декодирование осуществляется прямой заменой кода на соответствующий элемент. И в силу того, что использован префиксный код, не нужно отмечать начало и конец очередного кода.
Приведенный выше алгоритм является двухпроходным. Первый проход по изображению создает таблицу количеств (весов) элементов, а во время второго происходит кодирование. Существуют реализации алгоритма с фиксированной таблицей (CCITT Group 3 - используется для передачи факсимильных изображений). Часто бывает, что нам неизвестно априорное распределение вероятностей элементов алфавита, т.к. нам не доступна вся последовательность сразу. Или, например, желательно избавиться от необходимости хранить таблицу весов для декодирования. Соответственно, были предложены адаптивные модификации алгоритма Хаффмена.
Рассмотрим модификацию алгоритма, в которой дерево строится по мере поступления новых элементов так, чтобы сохранялась упорядоченность по весам узлов. Упорядоченность следующего вида: при проходе каждого уровня дерева, начиная с нижнего слева направо, веса узлов не убывают. Построение дерева выполняется следующим образом.
- На первом шаге строится обычное дерево Хаффмена, считая, что веса всех вершин равны (такое дерево будет упорядоченным в указанном выше смысле).
- При поступлении очередного элемента выполняется следующее:
- элемент кодируется;
- увеличивается значение веса в соответствующем терминальном узле;
- увеличиваются значения весов в соответствующих вершинах по пути от этого узла к корню;
- если после этого упорядоченность дерева нарушена, то:
- для такого узла ( А ) среди соседей справа ищется крайний узел ( Б ), вес которого меньше;
- узлы А и Б меняются местами, при этом веса узлов на путях от переставленных до корня корректируются соответствующим образом;
- если дерево опять неупорядочено, то вновь выполняется предыдущий шаг.
Декодирование выполняется по аналогичной схеме: инициализация дерева, получение кода, расшифровка, обновление дерева, перестройка дерева (если необходимо), и т.д.
Алгоритм Хаффмена используется на одной из стадий сжатия в формате JPEG, как составная часть метода DEFLATE, а также во многих других универсальных кодерах. Хотя данный метод уступает по степени сжатия арифметическому кодированию, его простота, скорость и истекший срок действия патентов обеспечивают широкую распространенность.