
|
Зачем необходимы треугольные нормы и конормы? Как их использовать? Имеется ввиду, на практике. |
Опубликован: 26.07.2006 | Доступ: свободный | Студентов: 3071 / 549 | Оценка: 4.00 / 3.77 | Длительность: 15:27:00
ISBN: 978-5-94774-818-5
Специальности: Программист, Математик
Теги:
Лекция 10:
Теория приближенных рассуждений
Аннотация: В лекции рассматривается композиционное
правило вывода — главное понятие теории приближенных рассуждений.
Описывается работа нечеткой экспертной системы, основанной на принципах теории
приближенных вычислений.
Ключевые слова: интеллект, ПО, высказывание, вывод, композиционное правило вывода, обобщение, значение, интервал, функция, пересечение, подмножество, отношение, нечеткое множество, Универсальное множество, терм, связь, множества, функция принадлежности, gain, лингвистическая переменная, выходные параметры, нечеткая экспертная система, описание системы, универсальность, logical inference, аппроксимация, универсум, переменная, ордината, графика, прямой, максимум, минимум, нечеткая переменная, минимизация, center, mean, Абсциссой, функциональная схема, алгоритм, отрезок, определение
Под приближенными рассуждениями понимается процесс, при котором из нечетких посылок получают некоторые следствия, возможно, тоже нечеткие. Приближенные рассуждения лежат в основе способности человека понимать естественный язык, разбирать почерк, играть в игры, требующие умственных усилий, в общем, принимать решения в сложной и не полностью определенной среде. Эта способность рассуждений в качественных, неточных терминах отличает интеллект человека от интеллекта вычислительной машины.
Основным правилом вывода в традиционной логике является правило modus
ponens,
согласно которому мы судим об истинности высказывания 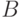 по
истинности высказываний
по
истинности высказываний  и
и 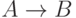 .
Например, если — высказывание "Джон в
больнице", — высказывание "Джон
болен", то если истинны высказывания "Джон в больнице" и
"Если Джон в больнице,
то он болен", то истинно и высказывание "Джон болен".
.
Например, если — высказывание "Джон в
больнице", — высказывание "Джон
болен", то если истинны высказывания "Джон в больнице" и
"Если Джон в больнице,
то он болен", то истинно и высказывание "Джон болен".
Во многих привычных рассуждениях, однако, правило modus ponens
используется не в точной, а в приближенной форме. Так, обычно мы знаем,
что истинно и что  , где
, где 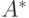 есть, в некотором смысле,
приближение . Тогда из мы можем сделать
вывод о том,
что приближенно истинно.
есть, в некотором смысле,
приближение . Тогда из мы можем сделать
вывод о том,
что приближенно истинно.
Далее мы обсудим способ формализации приближенных рассуждений, основанный на понятиях, введенных нами на предыдущей лекции. Однако, в отличие от традиционной логики, нашим главным инструментом будет не правило modus ponens, а так называемое композиционное правило вывода, весьма частным случаем которого является правило modus ponens.
Композиционное правило вывода
Композиционное правило вывода — это всего лишь обобщение
следующей знакомой процедуры. Предположим, что имеется кривая  (см. рис. 10.1(А)) и задано значение
(см. рис. 10.1(А)) и задано значение 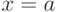 . Тогда из того, что и ,
мы можем заключить, что
. Тогда из того, что и ,
мы можем заключить, что  .
.
Обобщим теперь этот процесс, предположив, что 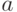 — интервал,
а
— интервал,
а 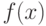 —
функция, значения которой суть интервалы, как на рисунке 10.1(Б). В этом
случае,
чтобы найти интервал
—
функция, значения которой суть интервалы, как на рисунке 10.1(Б). В этом
случае,
чтобы найти интервал  , соответствующий интервалу , мы сначала
построим цилиндрическое множество
, соответствующий интервалу , мы сначала
построим цилиндрическое множество  с основанием и
найдем его
пересечение
с основанием и
найдем его
пересечение  с кривой, значения которой суть интервалы. Затем
спроектируем это пересечение на ось
с кривой, значения которой суть интервалы. Затем
спроектируем это пересечение на ось 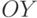 и получим желаемое
значение
и получим желаемое
значение  в виде
интервала
в виде
интервала 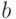 .
.
Чтобы продвинуться еще на один шаг по пути обобщения, предположим, что —
нечеткое подмножество оси 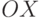 , а
, а 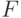 — нечеткое
отношение в
— нечеткое
отношение в  (см. рис. 10.1(В)). Вновь образуя цилиндрическое нечеткое
множество
(см. рис. 10.1(В)). Вновь образуя цилиндрическое нечеткое
множество  с основанием и его пересечение с нечетким
отношением , мы получим нечеткое множество
с основанием и его пересечение с нечетким
отношением , мы получим нечеткое множество  ,
которое
является аналогом точки пересечения I на рис. 10.1(А). Таким образом, из того,
что и
,
которое
является аналогом точки пересечения I на рис. 10.1(А). Таким образом, из того,
что и 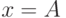 — нечеткое подмножество оси , мы получаем значение в виде
нечеткого подмножества оси .
— нечеткое подмножество оси , мы получаем значение в виде
нечеткого подмножества оси .
Правило. Пусть 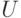 и
и 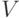 — два универсальных множества с базовыми
переменными
— два универсальных множества с базовыми
переменными  и
и 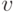 , соответственно. Пусть и — нечеткие подмножества
множеств и
, соответственно. Пусть и — нечеткие подмножества
множеств и  . Тогда композиционное правило вывода утверждает,
что из нечетких множеств и следует нечеткое
множество
. Тогда композиционное правило вывода утверждает,
что из нечетких множеств и следует нечеткое
множество 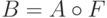 . Согласно определению композиции нечетких множеств, получим
. Согласно определению композиции нечетких множеств, получим
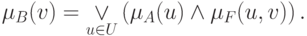
Пример.
Пусть  ,
,
A = МАЛЫЙ  ,
,
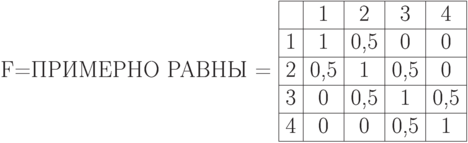
Тогда получим
![B = [1\quad 0,6\quad 0,2\quad 0] \circ \left[
{\begin{array}{*{20}c}
1 & {0,5} & 0 & 0 \\
{0,5} & 1 & {0,5} & 0 \\
0 & {0,5} & 1 & {0,5} \\
0 & 0 & {0,5} & 1 \\
\end{array} } \right] = [1\quad 0,6\quad 0,5{\kern 1pt} {\kern 1pt} \quad
0,2],](/sites/default/files/tex_cache/1e56743b0c35a968e9b10ec09e0c4ebf.png)
B = БОЛЕЕ ИЛИ МЕНЕЕ МАЛЫЙ,
если терм БОЛЕЕ ИЛИ МЕНЕЕ определяется как оператор увеличения нечеткости.
Словами этот приближенный вывод можно записать в виде
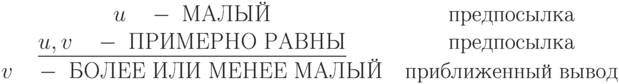
Владимир Власов