Программирование задач для асинхронной ВС архитектуры "data flow"
Численное интегрирование
Найдем методом "трапеций" приближенное значение интеграла функции y(x) (рис. 11.1).

При построении программы вновь воспользуемся оптимальной схемой счета —
способом "пирамиды" (рис. 11.2),
приведенной на рис. 10.7 для
случая n = 5. Здесь 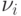 — математические адреса вычислителей, причем
— математические адреса вычислителей, причем  .
(Предполагаем, что либо на адрес вычислителя указывает тег, либо он принадлежит
определенной области адресного пространства.)
.
(Предполагаем, что либо на адрес вычислителя указывает тег, либо он принадлежит
определенной области адресного пространства.)

Программа коммутации приведена на рис. 11.3.

По командам 0—2 коммутируется выполнение инструкций формирования содержимого индексных регистров-модификаторов М1—М4.
По командам 3 и 4 на вычислителе с математическим адресом  формируется значение 0,5 x (y0 + yn).
формируется значение 0,5 x (y0 + yn).
Далее следует основной цикл реализации "пирамиды" — цикл на n - 1 повторений (команда 5).
По команде 6 коммутируется последовательная загрузка вычислителей 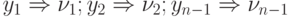 .
.
По команде 7 коммутируются операции 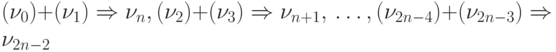 .
.
Команда 8 служит для изменения значений индексных регистров.
По команде 10 коммутируется умножение суммы значений функции,
сформированной на вычислителе с математическим адресом 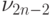 , на величину
, на величину  .
.
Напомним, что порядок использования математических адресов вычислителей обусловлен только требованиями организации циклической обработки массива данных с индексацией и переадресацией, т.е. продиктован законами программирования с учетом распараллеливания. При выполнении программы регистры буферов вычислителей назначаются адресным генератором исходя из требований динамического планирования использования ресурсов.
Умножение матриц
Воспользовавшись формулой вычисления элементов матрицы C = A x B,
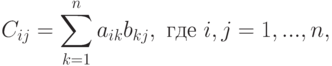
for i := 1 step 1 until n do
for j := 1 step 1 until n do
begin
c[i; j] := a[i; 1] x b[1; j];
for k := 1 step 1 until n do c[i; j] := c[i; j] + a[i; j] x b[k; j]
endПрограмма коммутации приведена на рис. 11.4.
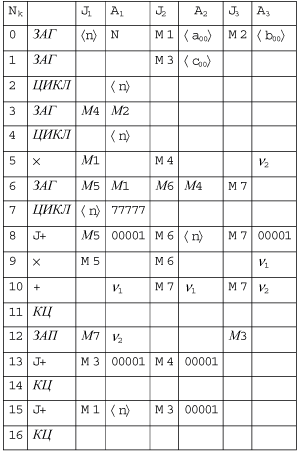
Дадим некоторые пояснения к ходу выполнения программы.
В команде 0 значения <a00> и <b00> являются адресами начала размещения элементов матриц A и B в ОПД, N — имя переменной, содержащей значение их размерности n. По команде 1 происходит загрузка адреса начала размещения элементов матрицы C.
Команда 2 начинает цикл на n повторений (этот цикл заканчивается командой 16). Команда 3 осуществляет настройку на первый столбец матрицы B.
Команда 4 начинает первый вложенный цикл на n повторений. Цикл завершается командой 14. Команда 5 коммутирует счет первого слагаемого суммы (в первый раз должно быть произведено умножение a00x b00 ). По команде 6 производится настройка индексных регистров, в частности, в первый раз будут выполнены действия
(M5):= a00 ; (M6):= b00 ; (M7):=0.
Команда 7 начинает второй вложенный цикл (заканчивается командой 11). По команде 8 производится коммутация переадресации по строке матрицы A, по столбцу матрицы B и переадресации вычислителя. Команда 9 — умножение, в первый раз выполняется коммутация действия
a01 x b10 => 1.
По команде 10 в первый раз (т.е. при ее первом выполнении) закоммутируется
выполнение действия  , во
второй раз —
, во
второй раз —  и т.д.
и т.д.
Команда 12 задает запись элемента матрицы C.
Команда 13 это переадресация по столбцу, а команда 15 переадресация по строке.