Распараллеливание в ВС на уровне исполнительных устройств
Обобщенная процедура динамического распараллеливания в многофункциональном АЛУ
В многопроцессорном вычислительном комплексе "Эльбрус-2" используется динамическое распределение работ между исполнительными устройствами АЛУ. При этом успешно разрешается противоречие между безадресной системой команд, предполагающей их выполнение на стеке, и возможностью одновременной загрузки многих исполнительных устройств.
При ближайшем рассмотрении стек представляется сугубо последовательностной структурой. Работа со стеком, как через "узкое горло", производится с использованием его вершины, и в случае многофункциональных АЛУ (т.е. АЛУ, состоящих из набора нескольких специализированных по операциям исполнительных устройств) представляется проблематичной. Казалось бы, стек по самой своей природе не предназначен для распараллеливания. Однако это не так, что и было продемонстрировано в МВК "Эльбрус-2". Здесь мы обобщим данный опыт.
Формирование потока трехадресных команд
В ИУ АЛУ в основном выполняются двуместные операции. Для выполнения такой
операции надо знать код операции, адреса двух операндов (как правило, — в
СОЗУ) и адрес результата. Т.е. АЛУ в общем случае оперирует трехадресными
командами вида  .
.
Для эффективного использования многофункционального АЛУ надо в каждый момент иметь в рассмотрении большое число таких команд, чтобы на их основе производилась полная загрузка заданиями и параллельная работа всех ИУ.
Значит, надо иметь некоторый буфер команд АЛУ (рис. 3.7), в котором формируется и поддерживается в достаточном количестве множество команд данной структуры. Готовые к выполнению команды из этого буфера назначаются на ИУ. Буфер "снизу" пополняется устройством управления новыми командами взамен назначенных для выполнения.

В ЦП МВК "Эльбрус-2" для загрузки 10 ИУ разной специализации просматривается до 30 команд.
Такой буфер и есть "окно просмотра", через которое проходят исполнительные команды, сформированные на основе выполняемой программы, m — максимальное число команд в "окне просмотра". Буфер может заполняться УУ после базирования и индексации команд.
Выше говорилось, что стек максимально снижает число обращений к ОП. Кроме того, ПОЛИЗ - естественный и простой результат трансляции с любого алгоритмического языка. Однако выполнение операций на стеке заключается в последовательном преобразовании его вершины. Это, казалось бы, исключает параллелизм, но и на ПОЛИЗ он виден. Например, по приведенной выше записи можно выделить первые параллельные операции счета:
![\text{\boldmath{$k l \colorbox[gray]{0.8}{\boldmath$m n \times$} - +
\colorbox[gray]{0.8}{\boldmath$a b -$} \times \text{\itshape\bfseries Зп } Y$}}](/sites/default/files/tex_cache/1784a571c444d7b44ab27eaba150b552.png)
Значит, чтобы распараллелить выполнение программы на стеке, надо выполнить промежуточный перевод

Для этого предполагается, что стек формируется не на основе данных, как выше, а на основе их адресов в СОЗУ, вне стека. Т.е. данные и промежуточные результаты располагаются в регистрах СОЗУ, а их адресами загружается стек; в стеке представлены не данные, а их адреса. Такой стек называется адресным стеком. Расположение же данных (включая промежуточные результаты) в СОЗУ планируется аппаратно, динамически так, чтобы оптимально использовать ограниченный объем СОЗУ (или предоставляемой его области) при достижении максимального параллелизма. Быстрые регистры СОЗУ являются распределяемым ресурсом.
Подобная общая схема работы АЛУ представлена на рис. 3.8.
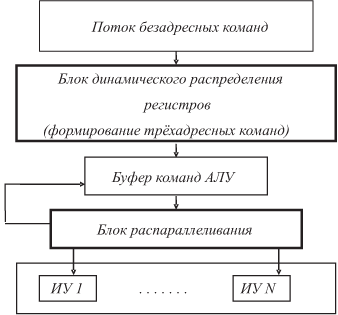
Рассмотрим работу блока динамического распределения регистров.
Он обрабатывает два списка адресов регистров СОЗУ: адресный стек и список свободных регистров.
Ранее мы видели, что в программе ПОЛИЗ есть три вида команд: загрузка стека, выполнение операции, запись из стека. Каждая из этих команд порождает трехадресную команду следующим образом.
Загрузка стека порождает трехадресную команду, в которой адрес считываемой величины в памяти указывается по первому адресу формируемой команды. По третьему адресу указывается первый адрес из списка свободных регистров. Этот адрес образует новую вершину адресного стека. (Т.е. регистр с этим адресом образует новую вершину стека, на котором производится счет.)
Команда выполнения операции порождает трехадресную команду, где одним из операндов является вершина стека. Если операция одноместная, адрес, стоящий в вершине адресного стека, становится первым адресом команды. Если операция двуместная, то адрес из вершины адресного стека становится вторым адресом формируемой команды, а первым адресом становится адрес, составляющий второй уровень адресного стека. Третий адрес берется из списка свободных регистров. Использованные адреса операндов исключаются из адресного стека и переводятся в конец списка свободных регистров. Адрес регистра, составивший третий адрес сформированной команды, т.е. адрес результата, включается в адресный стек как его новая вершина.
Запись из стека порождает трехадресную команду, где первый адрес — адрес из вершины адресного стека, третий адрес — адрес записи (в СОЗУ или ОП). Использованный адрес из вершины адресного стека исключается из этого стека и записывается в конец списка свободных регистров.
Пример.
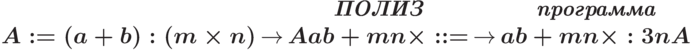
В таблице 3.1 представлен перевод программы из безадресной системы команд в трехадресную.
