Создание и использование индексов
Понятия индексирования
Теперь, когда вы получили представление о структуре индексов, рассмотрим некоторые из наиболее общих понятий индексирования. В этом разделе вы узнаете об индексных ключах, уникальности индексов и типах индексов.
Индексные ключи
Индексным ключом называется колонка или колонки, которые используются для формирования индекса. Индексный ключ – это значение, позволяющее быстро находить строку, содержащую нужные вам данные (подобно статье индекса [алфавитного указателя] в книге, указывающей определенную тему в тексте). Для доступа к данным строки через индекс вы должны включить значение или значения индексного ключа в предложение WHERE нужного оператора SQL. Способ выполнения этого процесса зависит от того, какой это индекс – простой или составной.
Простые индексы
Простой индекс определяется только по одной колонке таблицы (рис. 17.4). Чтобы индекс использовался оператором SQL, ссылка на эту колонку должна быть включена в предложение WHERE данного оператора.
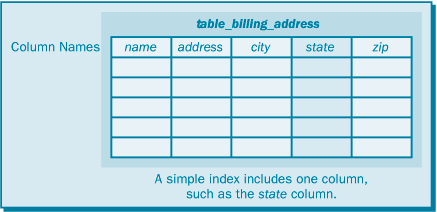
В зависимости от типа сохраняемых данных, количества уникальных элементов в колонке и типа используемых операторов SQL простой индекс может оказаться весьма эффективен. В других случаях необходим составной индекс. Например, если вы строите индекс для адресной книги с тысячами имен и адресов, то колонка state (штат) не слишком подходит для простого индекса, поскольку для каждого штата будет много записей. Однако, добавив к индексу колонки street (улица) и city (город), вы делаете его составным индексом, после чего почти каждая запись становится уникальной. Это может оказаться полезным, если у вас используются запросы поиска строк в соответствии с адресом.
Составные индексы
Составной индекс – это индекс, определенный более чем по одной колонке (рис. 17.5). Доступ к составному индексу может осуществляться с помощью одного или нескольких индексных ключей. В рамках SQL Server 2000 индекс может содержать до 16 колонок, и колонки ключей могут иметь длину до 900 байтов.

Для запросов, включающих составной индекс, вам не требуется помещать все индексные ключи в предложение WHERE оператора SQL, но имеет смысл использовать более одного ключа. Например, если индекс создается по колонкам a, b и c какой-либо таблицы, то доступ к этому индексу можно осуществлять с помощью оператора SELECT, содержащего выражение ( a АND b АND c ), или ( a АND b ), или a. Конечно, использование более ограничивающего предложения WHERE, содержащего, например, выражение a АND b АND c, обеспечит более высокую производительность. Скорее всего, из базы данных будет считано меньшее количество строк, поскольку строки будет указаны более точно. Если использовать a АND b или просто a, то будет инициировано сканирование индекса.
Сканирование индекса возникает потому, что критерию поиска соответствует более чем одна запись индекса. При сканировании индекса происходит сканирование узлов внутри индекса для считывание нескольких записей данных. Кроме того, индекс лишь частично соответствует выбранному значению. Например, если индекс создан по колонкам a, b и c, а в запросе указано значение только для колонки a, то будут возвращены все удовлетворяющие этому значению строки для всех значений колонок b и c.
Поскольку колонки, по которым строится индекс, упорядочиваются числовым образом, то оптимизатор запросов SQL Server может определить диапазон индексных страниц, которые могут содержать нужные данные. Если известны начальная и конечная страницы, то будут считаны все страницы, содержащие значения данных, после чего будет выполнено сканирование этих данных для выбора запрошенных данных.
Таблица местоположения заказчиков
Предположим, что у нас имеется таблица, содержащая информацию о местоположении заказчиков вашего предприятия. По колонкам state (штат), country (графство) и city (город) создается структура B-дерева в следующем порядке: state, country, city. Если в запросе в предложении WHERE указано значение Texas (Техас) колонки state, то будет использован индекс. Но поскольку значения колонок country и city не заданы в запросе, то индекс возвратит набор строк, исходя из всех записей индекса, содержащих значение Texas в колонке state. Для считывания диапазона индексных страниц используется сканирование индекса и последующее сканирование страниц данных, исходя из значений колонки state. Страницы индекса считываются последовательно таким же образом, как при сканировании таблицы для доступа к страницам данных.
 Примечание. Индекс может быть использован только в том случае, если хотя бы один из индексных ключей указан в предложении WHERE запроса SQL. Если в предложении WHERE запроса для предыдущего примера указано значение только колонки name (имя) или колонки phone number (номер телефона), то индекс использоваться не будет.
Примечание. Индекс может быть использован только в том случае, если хотя бы один из индексных ключей указан в предложении WHERE запроса SQL. Если в предложении WHERE запроса для предыдущего примера указано значение только колонки name (имя) или колонки phone number (номер телефона), то индекс использоваться не будет.В большинстве случаев сканирование индекса будет достаточно эффективным; но если происходит доступ к более чем 20 процентам строк таблицы, то более эффективным является сканирование таблицы, при котором из таблицы считываются все строки. Эффективность запросов, использующих индекс, зависит от того, как вы используете индекс (см. раздел "Использование индексов" далее), а также от степени уникальности индекса (см. следующий раздел).
Уникальность индекса
Вы можете определить индекс SQL Server как уникальный или неуникальный. В уникальном индексе каждое значение индексного ключа должно быть уникальным. В неуникальном индексе допускается дублирование индексных ключей в таблице данных. Эффективность неуникального индекса зависит от избирательности (селективности) данного индекса.
Уникальный индекс
Уникальный индекс содержит только одну строку данных для каждого индексного ключа; иными словами, значения индексного ключа не могут присутствовать в индексе более одного раза. Использование уникальных индексов гарантирует, что для поиска запрошенных данных требуется всего одна дополнительная операция ввода-вывода. SQL Server обеспечивает уникальность индекса по колонкам или комбинации колонок, образующих ключ индекса. SQL Server не допускает занесения дублированных значений ключа в базу данных. Если вы попытаетесь сделать это, появится сообщение об ошибке. SQL Server создает уникальные индексы, если задали по таблице ограничение PRIMARY KEY или ограничение UNIQUE. (Об ограничениях PRIMARY KEY и UNIQUE см. "Создание и использование умолчаний, ограничений и правил" ).
Индекс можно сделать уникальным, только если уникальны сами данные. Если данные какой-либо колонки не обладают свойством уникальности, то вы можете все же создать уникальный индекс, используя составной индекс. Например, колонка last name (фамилия), возможно, не будет уникальной, но комбинация данных этой колонки с колонками first name (имя) и middle name (отчество) может образовать уникальный индекс по данной таблице.
Примечание. Если вы попытаетесь вставить в таблицу строку, которая дает дублированное значение индексного ключа в уникальном индексе, то вставка не будет выполнена.