Создание баз данных
После того как вы инсталлировали Microsoft SQL Server 2000, а затем спроектировали размещение баз данных и дисков, можно приступить к созданию баз данных. SQL Server 2000 применяет усовершенствованные методы хранения данных и управления дисковой памятью, появившиеся в SQL Server 7. В более ранних версиях продукта для размещения данных использовались логические устройства и сегменты фиксированного размера, но SQL Server 2000 использует файлы и группы файлов, которые могут быть сконфигурированы на автоматический рост или уменьшение. В данной лекции будет подробно рассказано о файлах и группах файлов, а также рассказано, как управлять ростом базы данных. Вы также познакомитесь с тремя методиками создания баз данных, узнаете, как просматривать информацию о базах данных и как удалять ненужные базы данных.
Структура базы данных
Каждая база данных SQL Server состоит из набора файлов операционной системы. Эти файлы могут группироваться в группы файлов, что облегчает их администрирование, помогает в размещении данных и повышает производительность. В данном разделе вы познакомитесь с файлами и группами файлов SQL Server и узнаете об их значении для создания баз данных.
Файлы
Как мы уже сказали, база данных SQL Server состоит из набора файлов операционной системы. Файл базы данных может быть либо файлом данных, либо файлом журнала. Файлы данных служат для хранения данных и объектов, таких как таблицы, индексы, представления, триггеры и хранимые процедуры. Имеется два типа файлов данных: первичные и вторичные. Файлы журналов служат только для хранения информации из журналов транзакций. Место на диске, отводимое для файлов журналов всегда должно администрироваться отдельно от места, отводимого для данных, и никогда не должно быть частью файла данных.
Каждая база данных должна создаваться хотя бы с одним файлом данных и с одним файлом журнала; файлы не могут быть использованы более чем в одной базе данных – т.е., базы данных не могут разделять файлы (использовать файлы совместно). В приведенном ниже перечне указаны три типа файлов, которые могут быть использованы в базах данных:
- Первичные файлы данных. Первичные файлы данных содержат всю информацию для запуска базы данных и ее системных таблиц и объектов. Они указывают на другие файлы, созданные в базе данных. Они могут также содержать таблицы и объекты, задаваемые пользователем, хотя это и не обязательно. Каждая база данных может иметь ровно один первичный файл. Для этих файлов рекомендуется применять расширение .mdf.
- Вторичные файлы данных. Вторичные файлы данных не являются обязательными. Они могут хранить данные и объекты, которые отсутствуют в первичном файле. База данных может вообще не иметь ни одного вторичного файла (если все ее данные хранятся в первичном файле). Можно иметь ноль, один или несколько вторичных файлов. Для некоторых баз данных требуется иметь несколько вторичных файлов, чтобы размещать данные по нескольким отдельным дискам. (Это не RAID-массивы дисков, как вы увидите из следующего раздела). Для этих файлов рекомендуется применять расширение .ndf.
- Файлы журналов транзакций. Файлы журналов транзакций хранят всю информацию из журнала транзакций, служащую для восстановления базы данных. Каждая база данных должна иметь хотя бы один файл журнала, а может иметь и несколько файлов журналов. Для этих файлов рекомендуется применять расширение .ldf.
 Примечание. Максимальный размер файлов базы данных SQL Server составляет 32 терабайта для файлов данных и 4 терабайта для файлов журналов.
Примечание. Максимальный размер файлов базы данных SQL Server составляет 32 терабайта для файлов данных и 4 терабайта для файлов журналов.Простая база данных может иметь один первичный файл данных, достаточно большой, чтобы в него могли поместиться все данные и объекты и один файл – журнал транзакций. Более сложная база данных может иметь один первичный файл данных, пять вторичных файлов данных и два файла – журнала транзакций.
Но как же данные смогут размещаться по многим файлам данных? А вот для этого и применяются группы файлов.
Группы файлов
При помощи групп файлов можно группировать файлы, это нужно для администрирования и размещения данных. (Группы файлов похожи на сегменты в Microsoft SQL Server 6.5 и в более ранних версиях.) Применение групп файлов позволяет повысить производительность базы данных, т.к. становится возможным создание базы данных, размещенной на многих дисках, на многих контроллерах и на RAID-массивах. (Про RAID-массивы см. "Конфигурирование и планирование подсистемы ввода-вывода" .) При помощи групп файлов можно создавать таблицы и индексы, размещаемые на заданных физических дисках, контроллерах и массивах дисков. В данной лекции мы рассмотрим некоторые примеры такой работы.
Имеются три типа групп файлов со следующими основными свойствами:
- Первичные группы файлов. Содержат первичный файл данных и все остальные файлы, не помещенные в другие группы файлов. К первичной группе файлов базы данных отнесены системные таблицы, задающие пользователей, объекты и полномочия для этой базы данных. SQL Server автоматически создает эти системные таблицы всякий раз, когда вы создаете базу данных.
- Пользовательские группы файлов. Все группы файлов, заданные пользователем в процессе создания (или последующего изменения) базы данных. Создавая таблицу или индекс, вы можете задать, чтобы они помещались в заданную пользовательскую группу файлов.
-
Стандартная группа файлов. Содержит все страницы для таблиц и индексов, у которых при создании не была задана конкретная группа файлов. По умолчанию, стандартной группой файлов является первичная группа файлов. Члены роли db_owner могут менять стандартную группу файлов, делая стандартной ту либо иную группу файлов. В каждый момент времени стандартной может быть лишь какая-то одна группа файлов, и, повторим, если стандартная группа файлов не была задана явно, то первичная группа файлов автоматически будет стандартной. Чтобы изменить стандартную группу файлов, воспользуйтесь следующей командой Transact SQL (T-SQL):(Применять T-SQL вы научитесь в последних лекциях данного курса.) Вы можете пожелать изменить стандартную группу файлов так, чтобы ею стала одна из ваших пользовательских групп файлов, тогда все объекты, создаваемые в вашей базе данных, будут автоматически создаваться в указанной вами группе файлов, и вам не придется всякий раз задавать это.
ALTER DATABASE имя_базы_данных MODIFY FILEGROUP имя_группы_файлов DEFAULT
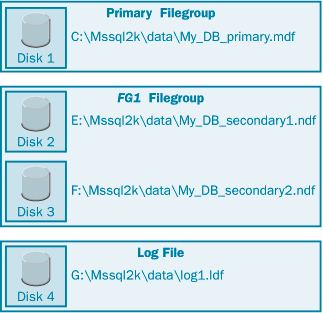
Чтобы повысить производительность, вы можете управлять размещением данных, создавая таблицы и индексы в разных группах файлов. Так, вы можете пожелать поместить таблицу, доступ к которой бывает часто, в группу файлов на большом массиве дисков (например, составленным из 10 дисков), а другую таблицу, доступ к которой бывает реже, поместить в другую группу файлов, расположенную на отдельном, меньшем массиве дисков (например, из 4 дисков). Таким образом, можно размещать таблицы, доступ к которым происходит чаще, по большему количеству дисков, позволяя этим дискам осуществлять параллельный ввод-вывод. Если вы не применяете массивы RAID и у вас имеется несколько дисковых накопителей, то у вас остается возможность применения групп файлов. Например, вы можете создать по отдельному файлу для каждого дискового накопителя, разместив каждый файл в отдельную пользовательскую группу файлов. Тогда вы сможете поместить каждую таблицу или индекс в отдельный файл (и на отдельный диск), назначив группу файлов при создании этой таблицы или индекса. Пример размещения файлов показан на рис. 9.1: один первичный файл данных размещен в первичной группе файлов на диске C, по одному вторичному файлу данных размещено в каждой из пользовательских групп файлов (FG1 и FG2) на дисках E и F и один файл-журнал размещен на диске G. После этого вы можете создавать таблицы и индексы в каждой из пользовательских групп файлов – FG1 или FG2.

А может быть, вы будете применять пользовательскую группу файлов для распределения данных по нескольким дискам. На рис. 9.2 показана пользовательская группа файлов FG1, состоящая из двух вторичных файлов данных, один из которых находится на диске E, а другой – на диске F (диске G размещен файл-журнал, а на C – первичный файл). В этом примере мы снова предполагаем, что каждый файл базы данных создан на отдельном физическом дисковом накопителе, и у нас нет аппаратной реализации RAID. Таблицы и индексы, созданные в этой пользовательской группе файлов, будут размещены сразу на двух дисках, потому что SQL Server применяет стратегию пропорционального расходования ресурсов.
Если вы применяете RAID-систему, то вам может потребоваться распределить данные из большой таблицы по нескольким логическим дискам-массивам, сконфигурированным на двух или на нескольких RAID-контроллерах. Для этого вам надо будет создать пользовательскую группу файлов, с файлами, соответствующими каждому из этих контроллеров. Допустим, вы создали два вторичных файла данных, каждый – на своем массиве дисков, а каждый логический массив состоит из восьми физических дисков и сконфигурирован как RAID 5. Эти два массива обслуживаются двумя отдельными RAID-контроллерами. Чтобы создать таблицу или индекс, располагающуюся на обоих этих контроллерах (т.е. на всех 16 дисковых накопителях), создайте одну пользовательскую группу файлов, в которую поместите оба файла, а затем создайте таблицу или индекс в этой группе файлов. Пользовательская группа файлов FG1 распределена по 16 физическим дискам (двум логическим дискам – RAID-массивам) (см. рис. 9.3). Там также показаны первичный файл данных на другом контроллере (с RAID 1) и файл журнала еще на одном контроллере (с RAID 10).
SQL Server позволяет оптимизировать распределение ваших данных по дисковым накопителям, за счет автоматического пропорционального расслоения (распределения) данных по всем файлам группы файлов. "Расслоение" (striping) – это термин, применяемый для описания распределения данных по нескольким файлам базы данных. Расслоение файлов SQL Server работает независимо от расслоения дисков RAID-массивов и, как вы видели из наших примеров, может применяться как в сочетании с RAID, так и самостоятельно.
Чтобы обеспечить расслоение данных, SQL Server записывает данные в файлы в объемах, пропорциональных свободному месту, остающемуся в файлах (относительно свободному месту в других файлах). Место для таблиц и индексов распределяется в виде экстентов (extents). Экстент – это единица для измерения места на диске, один экстент состоит из 8 страниц, а одна страница состоит из 8 Кб, так что один экстент состоит из 64 Кб. Допустим, нужно распределить 5 экстентов на файл F1, в котором свободно 400 Мб, и на файл F2, в котором свободно 100 Мб; тогда 4 экстента будут распределены на файл F1 и один экстент распределен на файл F2. Оба файла заполнятся до конца примерно одновременно, благодаря чему операции ввода-вывода будут распределяться по дискам более равномерно. Пропорциональное заполнение будет применяться и для пользовательских, и для первичных групп файлов. Если задать все файлы в группе файлов имеющими одинаковый начальный размер, то данные, по мере их загрузки, будут распределяться по файлам равномерно. Этот метод, когда в группах создаются файлы одинакового начального размера, можно порекомендовать для равномерного распределения данных по дисковым накопителям и, одновременно с этим, для равномерного распределения операций ввода-вывода.

Другая польза от применения групп файлов состоит в том, что SQL Server может выполнять резервные копирования базы данных файлами или группами файлов. Если ваша база данных слишком велика, чтобы ее можно было скопировать за один раз, то вы можете копировать ее по частям. (О методике такого резервного копирования см. "Резервное копирование Microsoft SQL Server" .)