Методы глобальной оптимизации
Метод виртуальных частиц
Метод виртуальных (случайных) частиц может надстраиваться почти над любым методом оптимизации. Он создан для:
- повышения устойчивости обученных сетей;
- вывода сетей из возникающих при обучении локальных минимумов оценки.
Основная идея метода - использование случайных сдвигов аргумента и суммирование полученных значений функции для усреднения. Ожидается, что в результате уменьшится влияние рельефа минимизируемой функции на процесс минимизации и откроется более прямой путь к её глобальному минимуму.
Метод случайных частиц состоит в том, что к оптимизируемой точке (частице) добавляется несколько других, траектории которых получаются из траектории данной частицы сдвигом на случайный вектор. Эти "виртуальные" частицы время от времени уничтожаются и рождаются новые. Спуск (минимизация) строится так, чтобы уменьшилось значение суммы значений оптимизируемой функции в указанных точках.
Рассмотрим один из вариантов алгоритма виртуальных частиц. Пусть требуется
найти минимум функции  .Параметры сети разбиваются на
группы
структурно эквивалентных. Для каждой группы задается свой интервал
случайных сдвигов. Определяется число виртуальных частиц
.Параметры сети разбиваются на
группы
структурно эквивалентных. Для каждой группы задается свой интервал
случайных сдвигов. Определяется число виртуальных частиц  и
генерируется
и
генерируется  случайных векторов
случайных векторов  . Их
координаты независимо и равномерно
распределены в заданных интервалах.
. Их
координаты независимо и равномерно
распределены в заданных интервалах.
Начальное положение основной частицы -  . Начальное
положение
. Начальное
положение 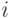 -ой
виртуальной частицы
-ой
виртуальной частицы  . Случайный вектор
для -й
виртуальной частицы строится так:
. Случайный вектор
для -й
виртуальной частицы строится так:
 |
( 1) |
и её положение задается вектором  . Всем частицам, кроме -й,
присваивается вес
. Всем частицам, кроме -й,
присваивается вес 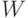 ,
,  , -я
получает вес
, -я
получает вес  . Далее
минимизируется функция
. Далее
минимизируется функция

Алгоритм локальной оптимизации может быть выбран любой - от наискорейшего
спуска и партан-методов до метода сопряженных градиентов. Выбор 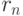 в виде
в виде  и определяется двумя
обстоятельствами:
и определяется двумя
обстоятельствами:
- для каждой координаты вектора дисперсия будет
совпадать с
дисперсией координат векторов
 ;
; - для квадратичных точки минимума и
 совпадут.
совпадут.
В методе виртуальных частиц возникает важный вопрос: когда уничтожать имеющиеся виртуальные частицы и порождать новые?
Есть три варианта:
- Функция минимизируется до тех пор, пока скорость
обучения не
упадет ниже критической. После этого вновь производят случайные сдвиги
частицы, и обучение продолжается.
- Порождение новых частиц производится после каждого цикла базового алгоритма оптимизации - при рестартах. Например, после каждого шага метода наискорейшего спуска, после партан-шага итерационного партан-метода и т.п.
- При каждом вычислении оценок и градиентов.
Первый способ наиболее консервативен. Он долго сохраняет все достоинства и недостатки предшествующего спуска, хотя направление движения может существенно измениться при порождении новых виртуальных частиц.
Третий способ вносит случайный процесс внутрь базового алгоритма, в результате возможны колебания даже при одномерной оптимизации. Его преимущество - экономия памяти.
Наиболее перспективным представляется второй способ. Он, с одной стороны, не разрушают базового алгоритма, а с другой - за счет многократного порождения виртуальных частиц позволяет приблизиться к глобальному множеству. Метод виртуальных частиц имеет все достоинства методов глобальной оптимизации, не использующих случайные возмущения, но лишен многих их недостатков.
Хорошие результаты обучения приносит объединение алгоритмов глобальной оптимизации с детерминированными методами локальной оптимизации. На первом этапе обучения сети применяется выбранный алгоритм глобальной оптимизации, а после достижения целевой функцией определенного уровня включается детерминированная оптимизация с использованием какого-либо локального алгоритма.