Опубликован: 23.10.2009 | Доступ: свободный | Студентов: 2795 / 93 | Оценка: 4.28 / 4.22 | Длительность: 17:27:00
Специальности: Программист
Теги:
Лекция 10:
Описание формальных грамматик
10.4. Основные понятия и теоремы
В этом разделе обобщаются сведения, полученные на данной лекции в разделах 10.01 - 10.03, и в "Грамматика" . Прочтите этот раздел внимательно.
10.4.1. Синтаксические деревья и деревья вывода
Синтаксические деревья помогают понять синтаксис предложений. В качестве иллюстрации построим дерево для вывода предложения 22 из грамматики в [примере 01].
<число> => <чс> => <чс><цифра> => <цифра><цифра> => 2<цифра> => 22Листинг 10.19.
Отправившись от символа <число>, нарисуем его куст, чтобы указать его непосредственный вывод (см. рисунок 10.1 a))
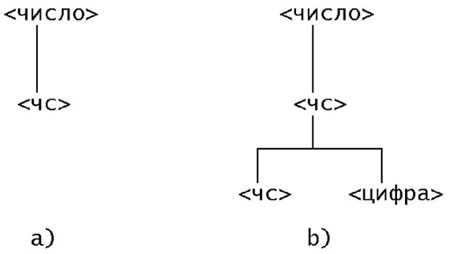
Рис. 10.1. Синтаксические деревья для двух непосредственных выводов. a) первый куст; b) первый и второй куст
Куст узла - это множество подчиненных ему узлов. Чтобы показать второй вывод, из узла, представляющего заменяемый символ, рисуется куст, узлы которого образуют цепочку, заменяющую этот символ ([[#g04fb] рисунок G.04 b)]. Концевые (висящие) узлы синтаксического дерева - это узлы, не имеющие подчиненных узлов. При чтении слева направо концевые узлы образуют цепочку, вывод которой представлен деревом. Концевой куст - это куст, все узлы которого концевые.
Существует и другая терминология. В ней концевые узлы называются "листьями", не концевые узлы - "ветвями". Начальный символ вывода везде называется "корнем".
Пусть N - ветвь (узел) дерева. Сыновьями N называются узлы куста, подчиненного N. N - их отец. Сыновья называются братьями. Самым младшим братом является самый левый из них. На рисунке 10.1, b) ветвь <чс> имеет двух сыновей, <чс> и <цифра>, младшим из них является <чс>.
О п р е д е л е н и е. Пусть N - ветвь синтаксического дерева. Тогда потомками ветви (узла) N будут все выводимые из него узлы, то есть все ветви и листья, лежащие выше нее. Предками узла N будут все ветви (нетерминальные символы, включая корень), приводимые к узлу N (лежащие выше нее в дереве вывода).
Поддерево синтаксического дерева состоит из узлов дерева, вместе с той частью дерева, которая исходит от него. Поддеревья тесно связаны с фразами: концевые узлы образуют фразу для корня данного поддерева.
Т е о р е м а. Концевые узлы образуют фразу для корня данного поддерева.
Д о к а з а т е л ь с т в о.
Пусть <U> - корень поддерева, а u - цепочка из концевых узлов поддерева. Тогда <U> =>+ u.
Пусть x - цепочка концевых узлов, расположенная слева от концевых узлов поддерева u, а y - цепочка концевых узлов справа от u. Тогда xuy - сентенциальная форма, то есть Z =>* xuy. Эти условия соответствуют определению фразы (10.11).
Подводя итог, сформируем следующее положения о синтаксических деревьях:
- для каждого синтаксического дерева существует, по крайней мере, один вывод;
- для каждого вывода есть соответствующее синтаксическое дерево (но несколько выводов может иметь одно дерево);
- куст дерева указывает на непосредственный вывод. Следовательно, в грамматике имеется правило, левой частью которого является имя (корень) куста, а правой - цепочка из узлов куста;
- концевые узлы куста образуют выводимую сентенциальную форму (предложение);
- пусть <U> - корень поддерева сентенциальной формы: w = xuy, где u цепочка конечных узлов этого поддерева. Тогда u - фраза сентенциальной формы w для <U>. Она является простой фразой, если поддерево представлено единственным кустом.
10.4.2. Однозначность грамматик
О п р е д е л е н и е. Предложение грамматики неоднозначно, если для его вывода существует, по крайней мере, два синтаксических дерева.
О п р е д е л е н и е. Грамматика неоднозначна, если она допускает неоднозначные предложения, в противном случае она однозначна.
Пример неоднозначной грамматики смотри ниже.
[Пример 02]
Рассмотрим следующую грамматику арифметических выражений:
<врж> ::= <врж>+<врж> <врж> ::= <врж>*<врж> <врж> ::= (<врж>) <врж> ::= i
Теперь рассмотрим ее сентенциальную форму:
i + i * iЛистинг 10.20.
Для нее возможны следующие деревья вывода (см. рисунок 10.2, {a), (b)):

Дерево, определенное на рисунке 10.2, (a) указывает на приоритет умножения, а на рисунке 10.2, (b) - приоритет сложения. Поэтому оба результата являются с точки зрения этой грамматики правильными, хотя вычисления приводят к разным результатам.
Грамматика, приведенная в примере 03 ниже, является однозначной.
[Пример 03].
Однозначная грамматика разбора арифметических выражений.
<врж> ::= <терм> <врж> ::= <врж>+<терм> <терм> ::= <множ> <терм> ::= <терм>*<множ> <множ> ::= (<врж>) <множ> ::= i
Теперь синтаксическое дерево для сентенциальной формы (10.20) будет единственным и выглядит следующим образом:

Из вышесказанного следует, что в практических целях лучше использовать однозначную грамматику. К сожалению, было доказано, что не существует алгоритма, который определял бы, является ли грамматика однозначной или нет. Поэтому при построении языков используют "достаточные" условия однозначности грамматик.
Следует отметить, что большинство используемых человеческих языков построено на "неоднозначных" грамматиках (в лексическом понимании). Примеры: "Петя взял лук" (какой лук, который едят или которым стреляют?), "Казнить нельзя помиловать" (без запятой непонятно, убить ли надо человека или отпустить на волю?) и т.д. Даже такой популярный язык программирования, как C++, часто реализуется неоднозначной грамматикой. Как правило, с неоднозначностью грамматик борются введением в программу разбора контекста и правил по-умолчанию.
10.4.3. Классификация грамматик по Хомскому
Американский ученый Хомский в [11, 19] определил четыре основных классов языков в терминах грамматик, являющихся упорядоченной четверкой [V, T, P, Z], где:
- V - алфавит, содержащий и терминальные, и нетерминальные символы;
- T (входит в V ) - алфавит терминальных символов;
- P - набор правил подстановок;
- Z - начальный символ, принадлежащий V - T (нетерминальным символам).
Тогда грамматика с фразовой структурой (по-другому, грамматика типа 0) имеет вид:
u ::= v, где u входит в V+, а v входит в V*Листинг 10.21.
то есть левая часть u также может быть последовательностью символов, а правая часть может быть пустой.
Если ввести ограничения на правила подстановки, то получится класс грамматик типа 1. Они называются контекстно-чувствительными, контекстно-зависимыми грамматиками, а в русскоязычной литературе - и грамматикой непосредственно составляющих, или НС-грамматиками. Они имеют вид:
xUy ::= xuy, где U входит в V-T, u входит в V+, а x,y входят в V*Листинг 10.22.
Термин "контекстно-чувствительный" отражает тот факт, что можно заменить U на u только в контексте x … y.
Дальнейшее ограничение дает класс грамматик типа 2, или контекстно-свободной, бесконтекстной или КС-грамматикой. Ее вид следующий:
U ::= u, где U входит в V-T, и u входит в V*Листинг 10.23.
Этот класс грамматик называется контекстно-свободной потому, что U можно изменять, не обращая внимание на контекст, в котором он встретился (то есть символы меняются на цепочки независимо). Однако в КС-грамматике может встретиться правило:
U ::= <пусто>Листинг 10.24.
где <пусто> - пустая цепочка. Поэтому КС-грамматика G, не имеющая правила [G.25], называется неукорачивающейся.
Примечание. Именно КС-грамматики и A-грамматики можно представить с помощью БНФ РБНФ (о которых будет сказано в
"Представление грамматик"
).
И, наконец, введя ограничения:
U ::= N, или U ::= NW, где N входит в T, а U и W входят в V-TЛистинг 10.25.
то получим грамматику типа 3, или регулярную, автоматную грамматику, или А-грамматику. Практически это праворекурсивная грамматика. Регулярные грамматики играют основную роль в теории языков и теории автоматов. Только множество цепочек регулярной грамматики может генерировать автомат с конечным числом состояний (иначе - детерминированная машина Тьюринга или ЭВМ со структурой фон Неймана, т.е. почти все современные компьютеры). Регулярные языки (то есть порожденные А-грамматиками) называются регулярными множествами. Именно их желательно использовать при программировании символьных вычислений на компьютере.
10.4.4. Практические ограничения, налагаемые на грамматику
Чтобы появиться в выводе какого-нибудь предложения, нетерминал <U> должен удовлетворять двум условиям:
Z =>* x<U>y для некоторых (в том числе пустых) цепочек x и yЛистинг 10.26.
<U> =>+ t для некоторой t входящей в VT+Листинг 10.27.
О п р е д е л е н и е. Грамматика G[Z] называется приведенной, если каждый нетерминал <U> удовлетворяет условиям: (10.26) и (10.27).
Также грамматика не должна содержать правила:
<U> ::= <U>Листинг 10.28.