Нормальные алгоритмы Маркова
Определение нормального алгоритма и его выполнение
В середине прошлого века выдающийся русский математик А.А. Марков ввел понятие нормального алгоритма (алгорифма) с целью уточнения понятия "алгоритм", что позволяет решать задачи по определению алгоритмически неразрешимых проблем. Позже это понятие получило название нормального алгоритма Маркова (НАМ). Язык НАМ, с одной стороны, намеренно беден, что необходимо для цели введения понятия "алгоритм". Однако, с другой стороны, идеи НАМ положены в основу большой группы языков программирования, получивших название языки логического программирования, которые являются темой данного пособия.
Для определения НАМ вводится произвольный алфавит - конечное непустое множество символов, при помощи которых описывается алгоритм и данные. В алфавит также включается пустой символ, который мы будем обозначать греческой буквой  . Под словом понимается любая последовательность непустых символов алфавита либо пустой символ, который обозначает пустое слово.
. Под словом понимается любая последовательность непустых символов алфавита либо пустой символ, который обозначает пустое слово.
Всякий НАМ определяется конечным упорядоченным множеством пар слов алфавита, называемых подстановками . В паре слов подстановки левое (первое) слово непустое, а правое (второе) слово может быть пустым символом. Для наглядности левое и правое слово разделяются стрелкой. Например,

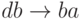


В качестве данных алгоритма берется любая непустая строка символов. Работа НАМ состоит из последовательности совершенно однотипных шагов. Шаг работы алгоритма может быть описан следующим образом:
- В упорядоченной последовательности подстановок ищем самую первую подстановку, левое слово которой входит в строку данных.
- В строке данных ищем самое первое (левое) вхождение левого слова найденной подстановки.
- Это вхождение в строке данных заменяем на правое слово найденной подстановки (преобразование данных).
Шаг работы алгоритма повторяется до тех пор, пока
- либо не возникнет ситуация, когда шаг не сможет быть выполнен из-за того, что ни одна подстановка не подходит ( левое слово любой подстановки уже не входит в строку данных ) - правило остановки ;
- либо не будет установлено, что процесс подстановок не может остановиться.
В первом случае строка данных, получившаяся при остановке алгоритма, является выходной (результатом) и алгоритм применим к входным данным, а во втором случае алгоритм не применим к входным данным.
Так, определенный выше в примере нормальный алгоритм Маркова преобразует слово 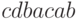 в слово
в слово  следующим образом (над стрелкой преобразования мы пишем номер применяемой подстановки, а в преобразуемой строке подчеркиваем левое слово применяемой подстановки ):
следующим образом (над стрелкой преобразования мы пишем номер применяемой подстановки, а в преобразуемой строке подчеркиваем левое слово применяемой подстановки ):

а при преобразовании слова abbc этот же алгоритм будет неограниченно работать, так как имеет место цикличное повторение данных:

Таким образом, всякий нормальный алгоритм Маркова определяет функцию, которую мы назовем нормальной (или вычислимой по Маркову), которая может быть частичной и которая в области определения входному слову ставит в соответствие выходное слово.
Возможности нормальных алгоритмов и тезис Маркова
Прежде всего рассмотрим возможности реализации арифметических операций с помощью нормальных алгоритмов Маркова. Сначала обратим внимание на одно обстоятельство, связанное с работой любого НАМ: нужно либо вводить дополнительное правило остановки работы нормального алгоритма (иначе в примере увеличения числа на 1 алгоритм продолжит работу и снова будет увеличивать полученный результат еще на 1 и т.д. неограниченное число раз), либо перед началом работы нормального алгоритма добавлять к входной строке специальные символы, отличные от других символов строки, которые учитываются подстановками алгоритма в начале его работы и которые удаляются в конце работы алгоритма. Мы будем придерживаться второго способа, как и одна из наиболее успешных реализаций нормальных алгоритмов Маркова в виде языка программирования Рефал. В качестве добавляемого символа возьмем символ "@".
Пример 1. Рассмотрим простейшую операцию увеличения десятичного числа на 1. В этом случае почти всегда необходимо увеличить последнюю цифру на 1, а последняя цифра отличается тем, что после нее идет символ "@". Поэтому первыми подстановками должны быть подстановки типа
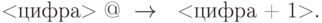
Но если это цифра 9, то ее нужно заменить 0 и увеличение на 1 перенести в предыдущий разряд. Этому отвечает подстановка

Наконец, если число начинается с 9 и перед этой цифрой нужно поставить 1, то этому будет отвечать подстановка
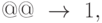
а если это не так, то в конце работы алгоритма символы @ надо стереть, что выполнит подстановка

Таким образом, мы получаем следующий НАМ увеличения десятичного числа на 1:

Приведем работу построенного алгоритма для чисел 79 и 99:

Аналогичным образом разрабатывается нормальный алгоритм Маркова для уменьшения числа на 1 (см. упражнение 1.3.1).
Пример 2. Прежде, чем перейти к другим арифметическим операциям, рассмотрим как довольно типичный пример, используемый часто в других алгоритмах, алгоритм копирования двоичного числа. В этом случае прежде всего исходное и скопированное числа разделим символом "*". В разрабатываемом алгоритме мы будем копировать разряды числа по очереди, начиная с младшего, но нужно решить 2 проблемы: как запоминать значение символа, который мы копируем, и как запоминать место копируемого символа. Для решения второй проблемы используем символ "!", которым мы будем определять еще не скопированный разряд числа, после которого и стоит этот символ. Для запоминания значения копируемого разряда мы будем образовывать для значения 0 символ "a", а для значения 1 - символ "b". Меняя путем подстановок эти символы "a" или "b" с последующими, мы будем передвигать разряды "a" или "b" в начало копируемого числа (после "*"), но для того, чтобы пока не происходило копирование следующего разряда справа, мы перед передвижением разряда временно символ "!" заменим на символ "?", а после передвижения сделаем обратную замену. После того как все число окажется скопированным в виде символов "a" и "b", мы заменим эти символы на 0 и 1 соответственно. В результате нормальный алгоритм копирования двоичного числа можно определить следующей последовательностью подстановок:

Продемонстрируем работу алгоритма для числа 10:

Для построения алгоритма сложения двух чисел можно использовать идею уменьшения одного числа на 1 с последующим увеличением другого числа на 1 и повторением этого до тех пор, пока уменьшаемое число не исчезнет после того, как станет равным 0. Но можно использовать и более сложную идею поразрядного сложения с переносом 1 в разряд слева. Построение этих алгоритмов, а также алгоритмов вычитания, умножения и деления выделено для самостоятельной работы в упражнениях 2 - 9 (см. 1.3).
Приведенные примеры показывают также возможности аппарата нормальных алгоритмов Маркова по организации ветвления и цикличных процессов вычисления. Это показывает, что всякий алгоритм может быть нормализован т. е. задан нормальным алгоритмом Маркова. В этом и состоит тезис Маркова, который следует понимать как определение алгоритма.
Вместе с тем построение алгоритма в последнем приведенном примере подсказывает следующую методику разработки НАМ:
- Произвести декомпозицию (разбиение на части) строящегося алгоритма. В примере это следующие части:
- разделение исходного числа и копии;
- копирование разряда;
- повторение предыдущей части до полного копирования всех разрядов.
- Решение проблем реализации каждой части. В примере это следующие проблемы:
- запоминание копируемого разряда - разряд 1 запоминается как символ "a", а разряд 0 - как символ "b";
- запоминание места копируемого разряда - пометка еще не скопированного символа дополнительным символом "!" с заменой его на символ "?" при передвижении копируемого разряда и обратной заменой после передвижения.
- Если часть для реализации является сложной, то она также подвергается декомпозиции.
- Сборка реализации в единый алгоритм.
Упражнения
- Определите нормальный алгоритм, который уменьшает число на единицу.
- Определите нормальный алгоритм сложения двух двоичных чисел методом уменьшения одного числа на 1 и увеличением другого числа на 1 до тех пор, пока уменьшаемое число не станет равным 0.
- Определите нормальный алгоритм логического сложения двух двоичных чисел.
- Определите нормальный алгоритм логического умножения двух двоичных чисел.
- Определите нормальный алгоритм сложения по модулю 2 двух двоичных чисел.
- Определите нормальный алгоритм поразрядного сложения двух двоичных чисел.
- Определите нормальный алгоритм вычитания двоичных чисел.
- Определите нормальный алгоритм умножения двух двоичных чисел столбиком.
- Определите нормальный алгоритм деления двух двоичных чисел с определением частного и остатка.
- Определите нормальный алгоритм вычисления наибольшего общего делителя двух двоичных чисел.
- Определите нормальный алгоритм вычисления наименьшего общего кратного двух двоичных чисел.