Спонсор: Intel
Вы можете этот курс.
Опубликован: 11.10.2012 | Доступ: свободный | Студентов: 307 / 58 | Длительность: 07:36:00
Специальности: Программист, Системный архитектор
Теги:
Дополнительный материал 1:
Intel-Cluster-Studio-XE-2013SP1
Основные характеристики
|
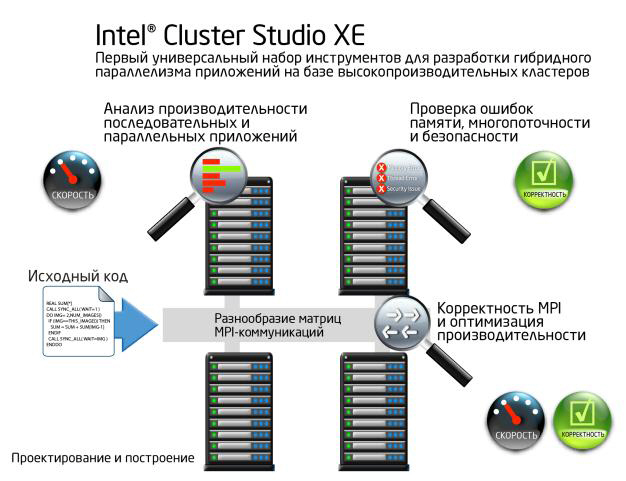
Интегрированный набор инструментов для разработки кластерных приложений Великолепная производительность совместно используемых, распределенных или гибридных приложений обеспечивается ведущими в отрасли компиляторами, параллельными моделями и библиотеками компании Intel, обладающими передовыми оптимизациями производительности для систем высокопроизводительных кластеров с мультиядерными (на сегодняшний день) и многоядерными (в будущем) процессорами. |
|
|
Ведущая в отрасли библиотека MPI Библиотека Intel® MPI Library обеспечивает новые уровни производительности, масштабируемости и гибкости приложениям, исполняемым на кластерах платформ Intel®.
|
|
|
Intel® Trace Analyzer and Collector Intel Trace Analyzer and Collector представляет собой мощный инструмент для определения корректности и режима работы MPI-приложения.
|
|
|
Высокопроизводительные компиляторы и библиотеки языков C, C++ и Fortran Компиляторы Intel® C, C++ и Fortran имеют встроенные технологии оптимизации и поддержку многопоточности, что помогает создавать код, максимально эффективно работающий на новейших мультиядерных процессорах Intel® и многоядерных архитектурах.
|