|
поддерживаю выше заданые вопросы
|
Спонсор: Intel
Вы можете этот курс.
Нижегородский государственный университет им. Н.И.Лобачевского
Опубликован: 02.10.2012 | Доступ: свободный | Студентов: 1753 / 198 | Длительность: 17:47:00
Специальности: Программист
Теги:
Лекция 2:
Архитектурные аспекты параллелизма
Аннотация: В лекции приводится классификация архитектур ВС, рассказывается о конвейеризации и ее основных принципах. Освещаются некоторые вопросы статической конвейеризации и динамического планирования. Рассматривается архитектура векторного конвейера, модели многопоточных процессоров. Рассматриваются многопроцессорные системы с общей шиной памяти, массивно-параллельные, кластерные системы.
Ключевые слова: параллелизм, организация памяти, исполнение, распараллеливание, суперскалярность, SIMD, архитектура, VLIW, потоки данных, SISD, MISD, MIMD, класс, поток инструкций, поток, программирование, множества, GFLOPS, процессор, декодирование, MMX, SSE, cell, IBM, power, processor, element, RISC, vector, multimedia, нотация, ассемблер, стековая архитектура, стек, бит, ISA, CISC, подмножество, CPU, система команд, x86, Java, поддержка, интерпретация, производительность, ядро, morphing
Цель лекции: Лекция направлена на знакомство слушателей с классами вычислительных систем, устройством многоядерных процессоров, возможностями оптимизирующей компиляции на уровне инструкций, динамическим планированием.
![]() Видеозапись лекции - (объем - 216 МБ).
Видеозапись лекции - (объем - 216 МБ).
Параллелизм в работе ЭВМ
Параллелизм – основа высокопроизводительной работы всех подсистем вычислительных машин. Организация памяти любого уровня иерархии, организация системного ввода/вывода, организация мультиплексирования шин и т.д. базируются на принципах параллельной обработки запросов. Современные операционные системы являются многозадачными и многопользовательскими, имитируя параллельное исполнение программ посредством механизма прерываний.
Развитие процессоростроения также ориентировано на распараллеливание операций, т.е. на выполнение процессором большего числа операций за такт. Ключевыми ступенями развития архитектуры процессоров стали гиперконвейеризация, суперскалярность, неупорядоченная модель обработки, векторное процессирование (технология SIMD), архитектура VLIW. Все ступени были ориентированы на повышение степени параллелизма исполнения.
В настоящее время мощные сервера представляют собой мультипроцессорные системы, а в процессорах активно используется параллелизм уровня потоков. Основное внимание нашего семинара будет уделено многопоточным и многоядерным процессорам.
Уровни параллелизма
Распараллеливание операций – перспективный путь повышения производительности вычислений. Согласно закону Мура число транзисторов экспоненциально растет, что позволяет в настоящее время включать в состав CPU большое количество исполнительных устройств самого разного назначения. Прошли времена, когда функционирование ЭВМ подчинялось принципам фон Неймана.
В 70-е годы стал активно применяться принцип конвейеризации вычислений. Сейчас конвейер Intel Pentium 4 состоит из 20 ступеней. Такое распараллеливание на микроуровне – первый шаг на пути эволюции процессоров. На принципах конвейеризации базируются и внешние устройства. Например, динамическая память (организация чередования банков) или внешняя память (организация RAID).
Но число транзисторов на чипе росло. Использование микроуровневого параллелизма позволяло лишь уменьшать CPI (Cycles Per Instruction), так как миллионы транзисторов при выполнении одиночной инструкции простаивали. На следующем этапе эволюции в 80-е годы стали использовать параллелизм уровня команд посредством размещения в CPU сразу нескольких конвейеров. Такие суперскалярные CPU позволяли достигать CPI<1. Параллелизм уровня инструкций (ILP) породил неупорядоченную модель обработки, динамическое планирование, станции резервации и т.д. От CPI перешли к IPC (Instructions Per Clock). Но ILP ограничен алгоритмом исполняемой программы. Кроме того, при увеличении количества ALU сложность оборудования экспоненциально растет, увеличивается количество горизонтальных и вертикальных потерь в слотах выдачи. Параллелизм уровня инструкций исчерпал свои резервы, а тенденции Мура позволили процессоростроителям осваивать более высокие уровни параллелизма. Современные методики повышения ILP основаны на использовании процессоров класса SIMD. Это векторное процессирование, матричные процессоры, архитектура VLIW.
Параллелизм уровня потоков и уровня заданий применяется в процессорах класса MIMD. Многопоточные процессоры позволяют снижать вертикальные потери в слотах выдачи, а Simultaneous Multithreading (SMT) процессоры – как вертикальные, так и горизонтальные потери. Закон Мура обусловил также выпуск многоядерных процессоров (CMP). Лучшие современные вычислители – это мультикомпьютерные мультипроцессорные системы.
Параллелизм всех уровней свойственен не только процессорам общего назначения (GPP), но и процессорам специального назначения (ASP (Application-Specific Processor), DSP (Digital Signal Processor)).
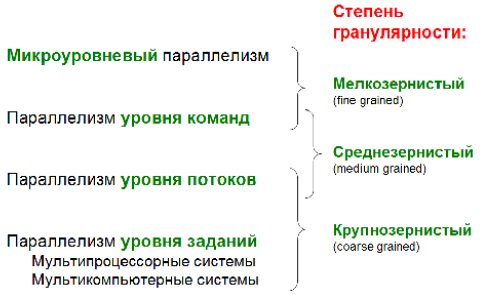
Иногда классифицируют параллелизм по степени гранулярности как отношение объема вычислений к объему коммуникаций. Различают мелкозернистый, среднезернистый и крупнозернистый параллелизм. Мелкозернистый параллелизм обеспечивает сам CPU, но компилятор может и должен ему помочь для обеспечения большего IPC. Среднезернистый параллелизм – прерогатива программиста, которому необходимо разрабатывать многопоточные алгоритмы. Здесь роль компилятора заключается в выборе оптимальной последовательности инструкций (с большим IPC) посредством различных методик (например, символическое разворачивание циклов). Крупнозернистый параллелизм обеспечивает ОС.
Метрики параллелизма
Допустим, имеется в наличии вычислительная система с неограниченными вычислительными ресурсами (в которой количество процессоров неограниченно). Как поведут себя программы в этой системе? Ускорятся ли они в неограниченное количество раз? Конечно, нет! Скорость работы простейшей однопоточной программы не изменится, так как она не использует параллелизм высокого уровня. Ее вычислительная нагрузка ляжет исключительно на один из процессоров. В отличие от микроуровневого параллелизма, который обеспечивается самим процессором, или в отличие от параллелизма уровня инструкций, где участия программиста не требуется (за исключением SIMD), привлечение к вычислениям нескольких процессоров требует существенной модификации алгоритма. Фактически требование дальнейшего повышения производительности вычислений вынуждает применять новые методики программирования, такие как векторное процессирование (например, SSE), многопоточное программирование (например, с использованием технологии OpenMP) и т.д. Отметим, что классические языки программирования высокого уровня (такие, как C++) ориентированы исключительно на класс SISD.
Итак, программист изменил алгоритм и создал многопоточный код (например, при
помощи потоков POSIX). Приведет ли это к неограниченному росту
производительности? Введем в рассмотрение степень параллелизма программы –  –
число процессоров, участвующих в исполнении программы в момент времени
–
число процессоров, участвующих в исполнении программы в момент времени 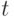 . При
старте программы
. При
старте программы  . Далее программа может создавать независимые потоки и
передавать им часть своей нагрузки. Изучив поведение алгоритма на неограниченной
машине, мы получим график – профиль параллелизма программы. Однако степень
параллелизма зависит не только от используемого алгоритма программы, но и от
эффективности компиляции и доступных ресурсов при исполнении. Реальное значение
будет иным.
. Далее программа может создавать независимые потоки и
передавать им часть своей нагрузки. Изучив поведение алгоритма на неограниченной
машине, мы получим график – профиль параллелизма программы. Однако степень
параллелизма зависит не только от используемого алгоритма программы, но и от
эффективности компиляции и доступных ресурсов при исполнении. Реальное значение
будет иным.
Введем в рассмотрение 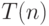 – время исполнения программы на n процессорах.
– время исполнения программы на n процессорах.
 , если параллельная версия алгоритма эффективна.
, если параллельная версия алгоритма эффективна.  , если накладные
расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики.
Заметим, что за
, если накладные
расходы (издержки) реализации параллельной версии алгоритма чрезмерно велики.
Заметим, что за  взято не время выполнения многопоточной программы на одном
процессоре, а время выполнения однопоточной программы.
взято не время выполнения многопоточной программы на одном
процессоре, а время выполнения однопоточной программы.
Тогда ускорение за счет параллельного выполнения составит  .
.
С экономической точки зрения интерес представляет ускорение в пересчете на
один процессор – эффективность системы из n процессоров 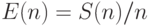 .
.
В идеальном случае ускорение линейно от  . Такой алгоритм обладает свойством
масштабируемости (возможностью ускорения вычислений пропорционально числу
процессоров). Но на практике масштабируемый алгоритм имеет несколько худшие
показатели из-за накладных расходов на поддержку многопроцессорных вычислений.
Кроме того, параметр n масштабируемого алгоритма должен быть согласован с
количеством процессоров в вычислительной системе. Необходимо также учитывать и
текущую загруженность процессоров другими задачами.
. Такой алгоритм обладает свойством
масштабируемости (возможностью ускорения вычислений пропорционально числу
процессоров). Но на практике масштабируемый алгоритм имеет несколько худшие
показатели из-за накладных расходов на поддержку многопроцессорных вычислений.
Кроме того, параметр n масштабируемого алгоритма должен быть согласован с
количеством процессоров в вычислительной системе. Необходимо также учитывать и
текущую загруженность процессоров другими задачами.
Особое внимание заслуживает случай  . Изначально может показаться, что
такого не может быть. Однако примеры такого успешного распараллеливания есть!
Вопрос лишь в том, как квалифицированно разбить исходную задачу на подзадачи.
Требования исходной задачи могут превосходить возможности эксплуатируемого
процессора по любому из его ресурсов (чаще всего это кеши различных уровней, буфер
BTB, буфер TLB). После разбиения на один процессор попадает задача меньшего
объема, и, соответственно, требования к объему ресурсов процессора сокращаются.
. Изначально может показаться, что
такого не может быть. Однако примеры такого успешного распараллеливания есть!
Вопрос лишь в том, как квалифицированно разбить исходную задачу на подзадачи.
Требования исходной задачи могут превосходить возможности эксплуатируемого
процессора по любому из его ресурсов (чаще всего это кеши различных уровней, буфер
BTB, буфер TLB). После разбиения на один процессор попадает задача меньшего
объема, и, соответственно, требования к объему ресурсов процессора сокращаются.
При преодолении таких порогов может возникать суперлинейное ускорение. Внимание: организация кода/данных должна обеспечивать максимальную степень локальности кода/данных (иначе ни линейного, ни тем более суперлинейного ускорения достичь не удастся).
Павел Каширин
|
Скачал архив и незнаю как ничать изучать материал. Видео не воспроизводится (скачено очень много кодеков, различных плееров -- никакого эффекта. Максимум видно часть изображения без звука). При старте ReplayMeeting и Start в браузерах google chrome, ie возникает script error с невнятным описанием. В firefox ситуация еще интереснее. Выводится: Meet Now: Кукаева Светлана Александровна. Meeting Start Time: 09.10.2012, 16:58:04 Downloading... Your Web browser is not configured to play Windows Media audio/video files. Make sure the features are enabled and available.
|