

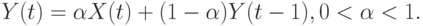


|
В дисциплине "Основы эконометрики" тест 6 дается по теме 7. |
Опубликован: 10.09.2016 | Доступ: свободный | Студентов: 947 / 166 | Длительность: 15:27:00
Тема: Экономика
Специальности: Менеджер, Руководитель, Экономист, Бухгалтер
Лекция 6:
Сглаживание временных рядов
6.4. Простое экспоненциальное сглаживание
Выше рассмотрены симметричные фильтры для сглаживания временных рядов. Вместе с ними широкое распространение при прогнозировании временных рядов получили асимметричные фильтры. Простейший из них - скользящая средняя, которая заменяет последнее значение ряда внутри интервала сглаживания,
Из формулы (6.22) следует простая рекуррентная формула
Первое слагаемое в формуле (6.23) указывает на то, что процесс обладает инерцией развития. Второе слагаемое отражает последние изменения в процессе, причем вес, с которым учитывается новое значение, зависит от ширины интервала сглаживания и равен 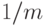 .
.
В предложенном методе (см. (6.22)) прошлые значения временного ряда выбирались с постоянным весом. Однако естественно прогнозировать будущие значения ряда с учетом устаревания информации. Один из приемов сглаживания ряда, позволяющих учитывать устаревание данных, является придание веса a текущему наблюдению и веса  предыдущему сглаженному значению ряда
предыдущему сглаженному значению ряда
Если формулу (6.24) последовательно применить к 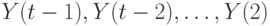 , то получим
, то получим
Так как 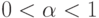 , веса при
, веса при  быстро уменьшаются с ростом
быстро уменьшаются с ростом 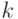 и влияние на
и влияние на 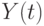 падает. Аналогично (6.23) можно переписать формулу (6.24)
падает. Аналогично (6.23) можно переписать формулу (6.24)
Из формулы (6.26) видно, что a является коэффициентом поправки на "новизну" в сглаженном временном ряде . Отметим, наконец, что за 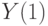 обычно принимают
обычно принимают  и процедуру сглаживания начинают со второго члена ряда.
и процедуру сглаживания начинают со второго члена ряда.
Для простой экспоненциальной средней, в предположении о независимости членов исходного ряда и постоянности дисперсии 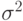 , можно вывести формулу для дисперсии сглаженного ряда
, можно вывести формулу для дисперсии сглаженного ряда

Так как  , то
, то 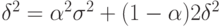 . Отсюда
. Отсюда  Следовательно, дисперсия сглаженного ряда меньше дисперсии исходного ряда.
Следовательно, дисперсия сглаженного ряда меньше дисперсии исходного ряда.
Теперь рассмотрим вопрос о выборе параметра \alpha . Во многих руководствах рекомендуется выбирать a из промежутка [0,1; 0,3].
Однако в работе С. Макридакиса рассмотрены примеры, когда лучшие результаты сглаживания были получены при 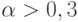 . Поэтому в последних статистических пакетах (например, в пакете STATISTICA) предлагается находить оптимальное значение параметра
. Поэтому в последних статистических пакетах (например, в пакете STATISTICA) предлагается находить оптимальное значение параметра  методом перебора значений с заранее выбранным шагом h.
методом перебора значений с заранее выбранным шагом h.
Метод простого экспоненциального сглаживания получил популярность главным образом благодаря его привлекательности как инструмента прогноза и простоте реализации. Так, С. Макридакис показал, что простое показательное сглаживание было лучшим выбором для прогноза "один период вперед" из числа 24 других методов. Таким образом, независимо от теоретической модели процесса, лежащей в основе наблюдаемого временного ряда, простое показательное сглаживание часто дает весьма точные прогнозы.