Опубликован: 24.04.2015 | Доступ: свободный | Студентов: 145 / 0 | Длительность: 04:57:00
Специальности: Менеджер, Математик, Преподаватель, Физик
Лекция 5:
Инструменты Gnumeric для статистиков
5.9 Ранги и процентили
Инструмент "Ранги и процентили" выполняет сортировку выборки по убыванию, определяет максимальное значение в выборке, присваивая ему первый ранг и значение в 100%, остальные значения выстраивает относительно первого и определяет, какой процент составляет текущая величина в выборке относительно максимального значения, а также указывает позицию каждого значения в выборке.
Рассмотрим, например, гипотетические результаты единого госэкзамена по ботанике среди группы в 25 участников (фамилии не указаны, поскольку они не используются для формирования данных). Таблица исходных данных приведена на рис. 5.28 (столбец "Баллы").
На вкладке "Параметры" диалога "Ранг и процентиль" (рис. 5.29) можно определить способ вычисления ранга (варианты "Средний ранг" и "Верхний ранг").
Поскольку требуется распределить весь набор значений на количество мест, равных количеству значений, то для повторяющихся значений получается деление мест (два одинаковых значения занимают два уровня рангов). Поэтому при использовании режима "Средний ранг" получаем дробные значения рангов (например, от 13 до 14 ранга имеется два значения, итого в среднем ранг получается 13,5). Результаты вычислений в таком режиме иллюстрируются группой "Средний ранг" на рис. 5.28.
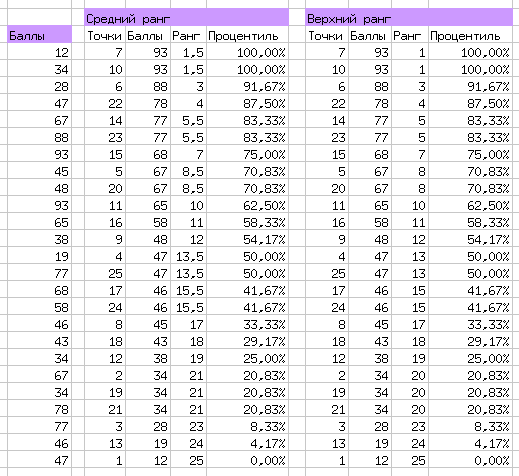
При использовании режима "Верхний ранг" используется минимальное значение ранга для повторяющихся значений, что иллюстрируется группой "Верхний ранг" на рис. 5.28.
5.10 Дисперсионный анализ
Согласно определению, данному в классической книге В.Е.Гмурмана "Теория вероятностей и математическая статистика", "дисперсионный анализ (ДА) применяют, чтобы установить, оказывает ли существенное влияние некоторый качественный фактор 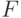 , который имеет
, который имеет 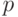 уровней
уровней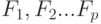 на изучаемую величину
на изучаемую величину  . Основная идея дисперсионного анализа состоит в сравнении "факторной дисперсии", порождаемой воздействие фактора, и "остаточной дисперсии", обусловленной случайными причинами. Если различие этих дисперсий значимо, то фактор оказывает существенное влияние на .
. Основная идея дисперсионного анализа состоит в сравнении "факторной дисперсии", порождаемой воздействие фактора, и "остаточной дисперсии", обусловленной случайными причинами. Если различие этих дисперсий значимо, то фактор оказывает существенное влияние на .

В более сложных случаях исследуют воздействие нескольких факторов на нескольких постоянных или случайных уровнях и выясняют влияние отдельных уровней и их комбинаций (многофакторный анализ)".
5.10.1 Однофакторный дисперсионный анализ
Рассмотрим пример однофакторного ДА на основе данных, взятых из учебного пособия "Статистические методы в инженерных исследованиях (лабораторный практикум)" (авторы Бородюк В.П., Вощинин А.П., Иванов А.З и др., см. список литературы).
Исследуется зависимость долговечности y электрических лампочек (в часах) от технологии изготовления (фактор x). В качестве исходных данных используется отклонение долговечности от "стандартного" значения в 1500 часов для 4-х неравночисленных серий образцов из разных партий (см. рис. 5.30).
В таблице приведены отклонения для различных образцов (y – номера образцов).
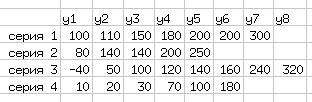
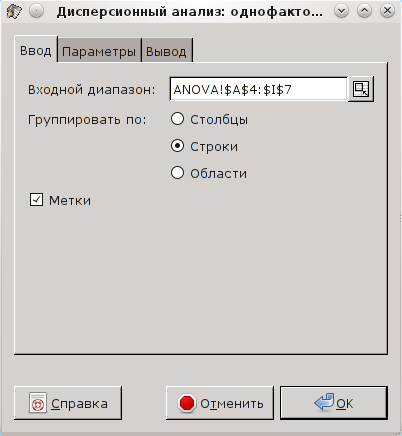
Диалог определения исходных данных для однофакторного ДА "Статистика/Тесты с множеством выборок/Дисперсионный анализ/Однофакторынй..." показан на рис. 5.31.
Важно не включать в диапазон данных лишние ячейки, в данном случае – ячейки с названиями образцов, что обеспечивается включением режима "Метки".
На вкладке "Параметры" устанавливается уровень значимости "Альфа" (по умолчанию – общепринятое значение 5%).

Вкладка "Вывод" – стандартная для всех диалогов статистического анализа, на ней определяется местоположение результатов вычислений.
Результаты показаны на рис. 5.32. Для повышения компактности вывода некоторые ячейки перенесены.
Какой же из этого всего следует вывод? А вывод такой: поскольку вычисленное значение результата "F" (F-критерий) меньше, чем "F критическое" для данного уровня значимости, влияние фактора (технологии изготовления) на исследуемый параметр (долговечность лампочек) является несущественным.
5.10.2 Двухфакторный дисперсионный анализ
В качестве примера применения Gnumeric для двухфакторного дисперсионного анализа рассмотрим задачу, приведенную в статье "Практикум по статистике с пакетами StatGraphics, Statistica, SPSS" на http://www.exponenta.ru/educat/systemat/goritskii/part2/LR7/2.asp (см. список литературы).
Исследуется урожайность четырех сортов пшеницы, ц/га (фактор А, 4 уровня) от используемого вида удобрений (5 уровней фактора B). Данные получены с 20 участков равной площади и одинакового почвенного состава. Требуется выяснить влияние сорта пшеницы и типа удобрений на урожайность.
Таблицы исходных данных приведена на рис. 5.33.
На рис. 5.34 показана вкладка "Ввод" диалога "Дисперсионный анализ: двухфакторный". Вкладки "Параметры" и "Вывод" являются стандартными, поэтому показывать их нет особого смысла.



Результаты вычислений показаны на рис. 5.35. Для уменьшения размера рисунка итоговые значений ("F", "P" и "F критическое") перенесены на другую строку.
При использовании Gnumeric получены те же значения уровней значимости P (0,153 и 0,225), что и в примере первоисточника. Соответственно, делается вывод о том, что в результате дисперсионного анализа не обнаружено влияние сорта пшеницы и типа удобрения на урожайность, что также видно из того, что при вычисленных уровнях значимости значения критерия F получаются меньше, чем соответствующие значения параметра "F критическое".
Нужно заметить, что использование свободно распространяемого пакета Gnumeric для решения подобных задач выглядит значительно привлекательнее использования пакета Statistica ценой около $700 USD, не говоря уже о StatGraphics или SPSS, легально приобрести которые весьма затруднительно.