


|
Не могу получить доступ к Azure |
Спонсор: Microsoft
Вы можете этот курс.
Опубликован: 31.07.2015 | Доступ: свободный | Студентов: 1891 / 839 | Длительность: 10:00:00
Специальности: Администратор информационных систем, Администратор 1C
Лекция 3:
Облачная платформа Microsoft Azure
DocumentDB
Azure DocumentDB представляет собой службу базы данных документов NoSQL, разработанную специально для реализации прямой поддержки JSON и JavaScript внутри системы базы данных. Это решение подходит для веб-приложений и мобильных приложений, при работе с которыми требуется обеспечить предсказуемую полосу пропускания, низкий уровень задержек и гибкие возможности работы с запросами. В приложениях Microsoft для потребителей, таких как OneNote, используется DocumentDB, что позволяет работать с миллионами пользователей.
Широкие возможности запросов и транзакций при работе с данными JSON. Схемы приложений постоянно изменяются, и это общая проблема, с которой сталкиваются многие разработчики. DocumentDB автоматически индексирует все документы JSON, добавляемые в базу данных, и затем позволяет с помощью обычного языка SQL запрашивать данные без указания схемы или вторичных индексов. Сочетание широких возможностей формирования запросов и транзакционной обработки данных позволяет создавать масштабируемые мобильные и веб-приложения, отвечающие современным требованиям. Поддержка использования в запросах пользовательских операторов и заданных пользователем функций (UDF) предоставляет больше преимуществ при работе с DocumentDB. Собственная модель данных JSON делает возможной интеграцию с интернет-платформами и средствами.
Обеспечение стабильного уровня производительности с возможностью настройки. Служба DocumentDB имеет облачную природу и работает со сверхбыстрыми SSD-накопителями, обладающими малым временем задержки и оптимизированными для операций записи. Высокая предсказуемая производительность и зарезервированные ресурсы позволяют обеспечить выполнение требований, предъявляемых к пропускной способности. По мере роста требований приложений хранилище и пропускная способность могут масштабироваться с пропорциональным изменением стоимости благодаря комбинируемым единицам мощности. Предусмотрена возможность настройки и подбора оптимального уровня согласованности с определенными уровнями (высокий, с ограниченной задержкой, сеансовый и пассивный) для соответствия сценариям приложений и требованиям к производительности. Это позволяет избежать необходимости выбора между двумя противоположными уровнями – высоким и пассивным. Выполняется автоматическая репликация данных, благодаря чему поддерживается высокий уровень доступности.
Предоставление возможности быстрой разработки. Доступ к базам данных через CRUD, запросы и обработка JavaScript в HTTP-интерфейсе RESTful упрощает процесс построения новых приложений для бизнеса. Программирование для DocumentDB характеризуется простотой, гибкостью и доступностью и не требует написания отдельного кода или расширений JSON или JavaScript.
Кэш Redis
Оптимизация приложения с помощью КЭШа. Кэш Azure обеспечивает быстрое реагирование приложения, высокую пропускную способность и доступ к данным с минимальной задержкой.
Кэш Redis. Кэш Redis для Microsoft Azure основан на кэше с открытым исходным кодом, Redis. Он предоставляет доступ к безопасному выделенному кэшу Redis, управляемому корпорацией Microsoft. Кэш, созданный с помощью Azure Redis, доступен из любых приложений в Microsoft Azure.
Кэш Redis для Microsoft Azure предоставляется на двух уровнях:
Basic – один узел. Несколько размеров.
Standard – два узла, ведущий/ведомый. Предоставляется соглашение об уровне обслуживания и поддерживается репликация. Несколько размеров.
Доступен кэш размером до 53 ГБ.
Высокая производительность. Кэш Redis для Azure помогает приложению работать быстрее, даже если пользовательская нагрузка увеличивается, и использует скоростные и производительные возможности модуля Redis. Отдельный распределенный слой кэша позволяет независимо масштабировать уровень данных для эффективного использования вычислительных ресурсов на слое приложений.
Redis. Redis – это усовершенствованное хранилище значений ключей, где ключи могут содержать такие структуры данных, как строки, хэши, списки, наборы и сортируемые наборы. Redis поддерживает ряд атомарных операций с этими типами данных.
Redis поддерживает репликацию "ведущий-ведомый" с быстрой начальной синхронизацией без блокировки, автоматическим повторным подключением при разделении сети и т.д.
К другим возможностям относятся транзакции, публикация/подписки, скрипты Lua, ключи с ограниченным сроком жизни и параметры конфигурации, позволяющие Redis действовать как кэш.
С Redis работают, используя большинство современных языков программирования.
Кэш Azure Redis использует проверку подлинности Redis и поддерживает SSL-подключения к Redis.
Удобство использования и управления. Кэш Redis для Azure прост в использовании. Необходимо подготовить кэш на новом портале управления Azure и использовать вызов к конечной точке в любом клиенте, поддерживающем Redis.
Кэш Redis для Azure прост в управлении. Можно отслеживать состояние и работу кэша с помощью нового портала управления Azure. Корпорация Microsoft может управлять репликацией кэша, повышая доступность данных при сбое кэша.
Хранилище
BLOB-объекты, таблицы, очереди и файлы. Хранилище Azure предоставляет гибкие возможности для хранения и извлечения крупных объемов неструктурированных данных, например, документов и файлов мультимедиа, в BLOB-объектах Azure, слабо структурированных данных в таблицах Azure, надежных сообщений в очередях Azure, а также использовать SMB-хранилище файлов Azure для переноса локальных приложений в облако (рис. 3.14).
Высокая масштабируемость. Хранилище Azure адаптируется к возрастающим требованиям в отношении объемов данных, выделяя до 500 ТБ общего пространства для хранения для каждой учетной записи.
Надежность и высокая доступность. Хранилище Azure автоматически реплицирует данные для защиты от неожиданных сбоев оборудования и предоставления доступа к ним в случае необходимости.
Создано для разработчиков. Можно создавать приложения с поддержкой клиентских библиотек для .NET, Java, Android, C++ и Node.js. Доступ к данным в хранилище Azure также можно получить, используя REST API, который вызывают с использованием любого языка, позволяющего осуществлять запросы HTTP/HTTPS. Хранилище Azure подразумевает гарантированную согласованность, упрощая разработку облачных приложений и обеспечивая прогнозируемую производительность приложений, основанных на Azure.
Глобальный доступ. Осуществляется горизонтальное или вертикальное масштабирование центров обработки данных по мере необходимости и данные размещаются географически ближе к своим клиентам для более быстрого доступа и повышения производительности.
Экономичность. Плата только за то, что используется, по цене, более низкой, чем у локальных вариантов хранения.
Создание учетной записи хранилища. Создание учетной записи с помощью портала управления (рис. 3.15).
- Необходимо щелкнуть "Создать", "Хранилище", "Быстрое создание".
- В области URL-адреса нужно ввести имя поддомена.
- В области "Расположение/родственная организация" нужно выбрать регион.
- Необходимо выбрать функцию репликации данных и щелкнуть "Создать учетную запись хранилища".
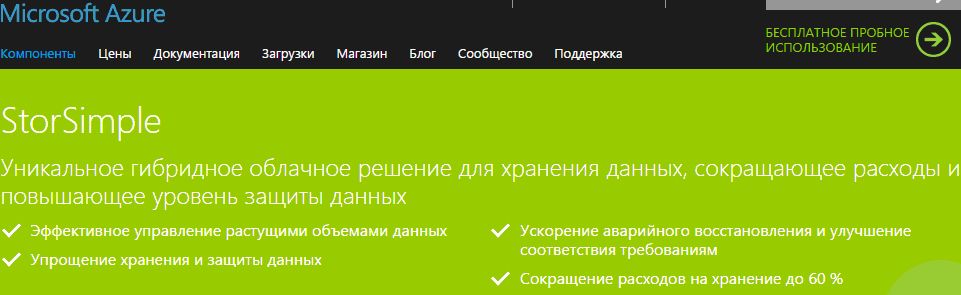
StorSimple
Управление данными. StorSimple позволяет автоматизировать работу и исключить рост объемов данных на два порядка и связанные с этим проблемы управления. В StorSimple используются SSD-накопители и жесткие диски, обеспечивающие высокую скорость ввода-вывода без существенных затрат, а также предоставляется встроенная функция удаления дубликатов и сжатия с целью сокращения общего объема данных. Данный продукт предоставляет широкие возможности масштабирования инфраструктуры хранения данных посредством использования Azure для сохранения быстро растущего объема неактивных первичных данных, зачастую приводящего к постоянному приобретению новых мощностей для хранения данных и слишком громоздкой инфраструктуре (рис. 3.16).
Упрощение хранения и защиты данных. StorSimple с помощью Azure позволяет автоматически расширять мощности и выполнять внешнее резервирование данных, поэтому сотрудники отделов ИТ могут тратить меньше времени на добавление мощностей, обслуживание инфраструктуры и управление защитой данных. Данное гибридное облачное решение объединяет в себе первичное, резервное, архивное и внешнее хранилище данных с автоматизированным созданием снимков, что заменяет дорогостоящую удаленную репликацию и управление ленточными накопителями.
Ускорение аварийного восстановления, улучшение соответствия требованиям. StorSimple обеспечивает быстрое аварийное восстановление посредством загрузки только данных, непосредственно необходимых приложениям. Продукт позволяет клиентам тестировать восстановление данных и обеспечивать соответствие политикам компании без нарушения работы центров обработки данных. При использовании StorSimple сохраняемые данные определяются программно на уровне политик, а не ограничиваются емкостью системы резервного копирования или ленточных накопителей.
Семейства продуктов
Хранилище StorSimple серии 8000. Microsoft Azure StorSimple – это предложение от корпорации Microsoft для хранения данных в облаке, реализованное на основе гибридных массивов хранения данных StorSimple 8000. Эти массивы хранения обеспечивают более высокую производительность и интеграцию с Azure. Массивы StorSimple 8600 поставляются в двух вариантах, отвечая различным требованиям к емкости и производительности: StorSimple 8100 and StorSimple 8600. Виртуальный модуль StorSimple предоставляет доступ по требованию к данным предприятия в среде Azure, что позволяет клиентам осуществлять поиск и анализ исторических наборов данных, осуществлять разработку и тестирование, а также аварийное восстановление в Azure. С помощью диспетчера StorSimple клиенты могут централизованно настраивать все параметры хранилища StorSimple и управления данными из облака, что позволяет обеспечить надлежащее выполнение операций и принудительное применение политик защиты и хранения данных на всем предприятии в целом.
StorSimple 5000 и 7000. StorSimple также предоставляет свои ведущие гибридные облачные решения для хранения данных – серии StorSimple 5000 и 7000. Клиенты получают все преимущества консолидации хранилищ, возможность управлять ростом объемов данных, упрощенные методы защиты данных и сокращение расходов за счет использования облака, как и в случае с серией 8000, но в конфигурации с меньшей мощностью и с тем исключением, что серии 5000 и 7000 не поддерживают диспетчер StorSimple и виртуальный модуль StorSimple.
Поиск Azure
Поиск Azure позволяет реализовать полнофункциональные возможности поиска на веб-сайте или в приложении. Настройка результатов поиска, а также создание полноценных адаптированных моделей ранжирования позволяет привязать результаты поиска к целям бизнеса. Стабильная пропускная способность и надежное хранение данных обеспечивают высокую скорость индексирования поиска и выполнения запросов, что незаменимо в сценариях с ограниченными временными рамками.
Упрощение работы. Поиск Azure исключает сложности, связанные с настройкой собственного поискового индекса и управлением этим индексом. Полностью управляемая служба предотвращает проблемы, связанные с повреждением индекса, доступностью службы, а также ее масштабированием и обновлением. Можно создать несколько индексов без увеличения стоимости.
Поиск Azure ускоряет разработку благодаря поддержке привычных средств и согласованной глобальной облачной платформе. Аналогично другим службам Azure, в службе поиска используются вызовы API REST. Всемирная сеть центров обработки данных Azure позволяет сократить длительность задержек при поиске, независимо от расположения приложения.
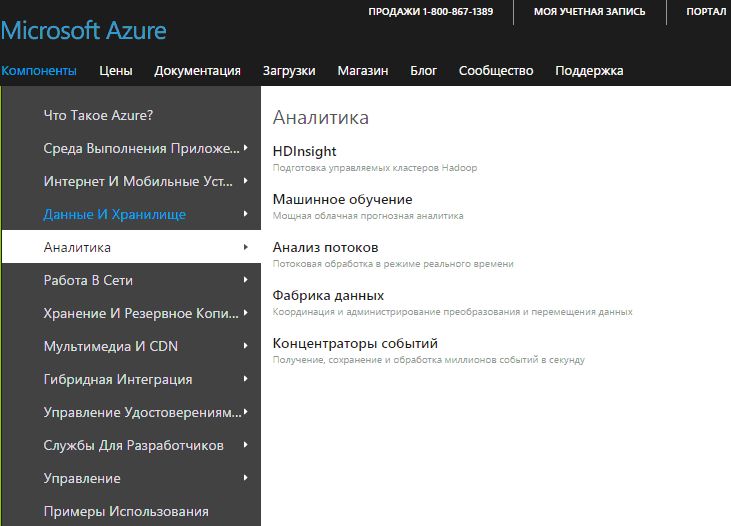
Аналитика
Рассмотрим следующие разделы компоненты "Аналитика" (рис. 3.17):
- HDInsight. Подготовка управляемых кластеров Hadoop.
- Машинное обучение. Облачная прогнозная аналитика.
- Stream Analytics. Потоковая обработка в режиме реального времени.
- Фабрика данных. Координация и администрирование преобразования и перемещения данных.
- Концентраторы событий. Получение, сохранение и обработка миллионов событий в секунду.
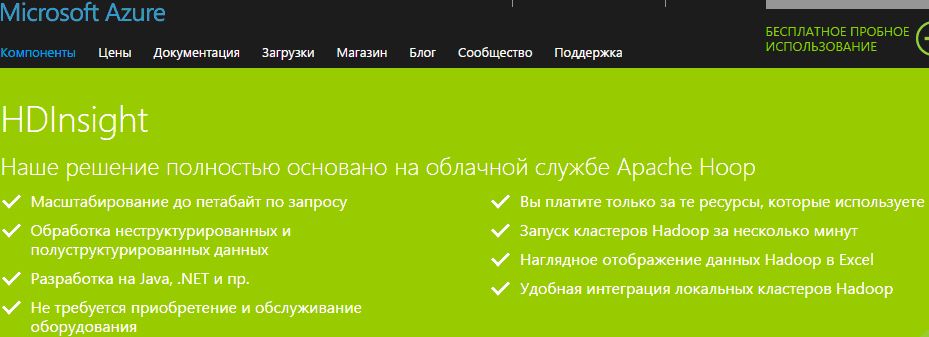
HDInsight
Масштабируемость по требованию. HDInsight представляет собой расширение Hadoop на основе облачных технологий (рис. 3.18). Средство HDInsight было создано для обработки любого объема информации с масштабированием от терабайтов до петабайтов данных по мере необходимости. Можно запустить любое количество узлов в любое время. Плата взимается только за те вычислительные ресурсы и хранилища, которые реально используются.
Объединение всех данных – структурированных, полуструктурированных и неструктурированных. HDInsight совместим с Apache Hadoop и поэтому может обрабатывать неструктурированные или частично структурированные данные журналов посещений сайта, соцсетей, журналов серверов, устройств, сенсоров и т.д. Благодаря этому можно анализировать новые наборы данных и находить новые возможности для бизнеса, которые будут способствовать росту организации.
Разработка программного обеспечения на предпочитаемом языке. HDInsight имеет программные расширения для языков, включая C#, Java, .NET и др. Можно использовать выбранный язык программирования в Hadoop для создания, настройки, отправки и мониторинга заданий.
Не требуется приобретение и обслуживание оборудования. С помощью HDInsight можно развернуть Hadoop в облаке без покупки дополнительного оборудования и предварительной платы. Также не требуется длительная установка и настройка.
Для визуализации данных Hadoop используется Excel. HDInsight интегрирован с Excel, и это позволяет визуализировать и анализировать данные Hadoop. В Excel пользователи могут выбрать Azure HDInsight в качестве источника данных.
Локальные кластеры соединяются с облаком. HDInsight интегрирован с платформой данных Hortonworks, поэтому можно перемещать данные Hadoop из локального центра обработки данных в облако Azure для создания резервных копий, разработки и тестирования и сценариев "cloud bursting". С помощью платформенной системы аналитики Microsoft можно одновременно отправлять запросы в локальные и облачные кластеры Hadoop.
Включает транзакционные функции, не связанные с базами данных SQL. HDInsight включает в себя Apache HBase, столбчатую базу данных NoSQL, работающую на базе распределенной файловой системы Hadoop (HDFS). Благодаря этому можно обрабатывать большие транзакции нереляционных данных и интерактивно записывать данные интерактивных веб-сайтов или сенсоров в хранилище BLOB-объектов Azure.
Обработка потоков в реальном времени. HDInsight включает Apache Storm, потоковую платформу аналитики, способную обрабатывать множество событий в реальном времени. Она позволяет обрабатывать миллионы создаваемых событий и поддерживать такие сценарии, как "Интернет вещей", получая данные от подключенных устройств и веб-событий.
Создание кластера с помощью HDInsight. С помощью HDInsight можно создать несколько кластеров Hadoop с одним и тем же набором данных (рис. 3.19).
Машинное обучение
Возможности машинного обучения. Машинное обучение – интеллектуальный анализ ретроспективных данных с помощью вычислительных систем для прогнозирования будущих тенденций или поведения. Поисковые системы, рекомендации в Интернете, целевая реклама, виртуальные помощники, прогнозирование спроса, выявление мошенничества, фильтры нежелательной почты – машинное обучение позволяет работать всем этим современным службам.
Машинное обучение Azure. Для машинного обучения требуется комплексное программное обеспечение, современные компьютеры и специалисты. Машинное обучение Azure – полностью управляемая облачная служба для прогнозной аналитики. С помощью облака машинное обучение Azure делает машинное обучение доступнее для более широкой аудитории.
Перетаскивание, прогнозирование. Машинное обучение Azure позволяет пользователям без наработок данных начать интеллектуальный анализ данных для прогнозирования. Для многих задач не требуется писать ни одной строки кода. Студия машинного обучения Microsoft Azure также содержит библиотеку экономящих время примеров экспериментов и сложных алгоритмов Microsoft Research, включая те же проверенные алгоритмы, которые используются в Bing и Xbox.
Поддержка R. Машинное обучение Azure также предназначено для опытных специалистов по изучению данных. Оно поддерживает R, популярную программную среду с открытым исходным кодом для статистики и интеллектуального анализа данных. Существующий код R помещают в рабочее пространство или записывают собственный код в студии машинного обучения Microsoft Azure, которая поддерживает безопасное использование более 350 пакетов R.
С машинным обучением Azure не нужно устанавливать программное обеспечение, настраивать оборудование или скрытую среду разработки. Можно войти в Azure и начать разработку моделей прогнозирования откуда угодно, не используя ничего, кроме браузера, и развертывать новые модели аналитики. Машинное обучение Azure также позволяет хранить практически неограниченное количество файлов в хранилище Azure. Оно подключается к другим службам Azure для работы с данными, включая HDInsight (основанное на Hadoop решение больших данных), базу данных SQL и виртуальные машины.
Машинное обучение Azure объединяет новые средства аналитики, алгоритмы, разработанные для Xbox и Bing, и годы исследований машинного обучения Microsoft в одной облачной службе. Оно предоставит начинающим разработчикам и компаниям данных недорогой доступ к средствам.
Stream Analytics (Анализ потоков)
Анализ потоков позволяет уйти от трудностей при разработке аналитических функций для масштабирования распределенных систем. Разработчикам нужно описать требуемую трансформацию посредством синтаксиса на основе SQL, а система автоматически разложит ее по масштабу, производительности и отказоустойчивости.
Фабрика данных
Фабрика данных позволяет обрабатывать локальные данные, например из SQL Server, вместе с облачными данными, например из базы данных SQL Azure, больших двоичных объектов и таблиц. Эти источники данных можно объединять, обрабатывать и отслеживать с помощью простых, высокодоступных и устойчивых к сбоям конвейеров данных.
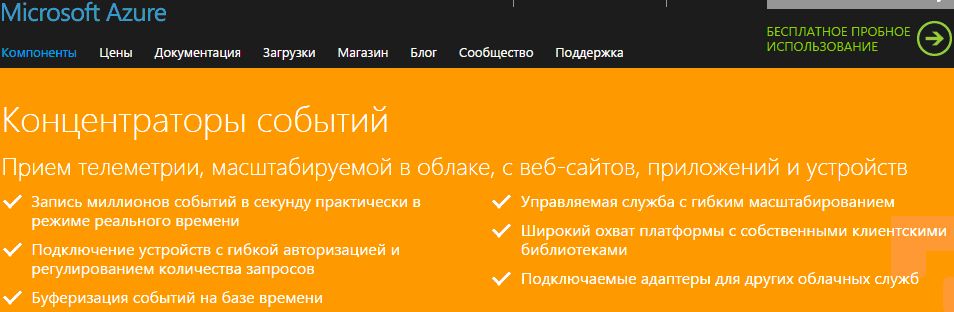
Концентраторы событий
Концентраторы событий – это приемник на основе публикации и подписки с высокой степенью масштабируемости, который принимает миллионы событий в секунду, чтобы можно было обработать и проанализировать большой объем данных с подключенных устройств и из приложений (рис. 3.20). Данные, собранные концентраторами событий, можно преобразовать и сохранить, используя любого поставщика аналитики в режиме реального времени, или с помощью адаптеров пакетов или хранилища.
Подключение миллионов устройств разных платформ. Концентраторы событий предоставляют возможность подготовки емкости для принятия событий с миллионов устройств, сохраняя порядок событий для каждого устройства. Поддержка AMQP и HTTP позволяет многим платформам работать с концентраторами событий. Также для популярных платформ существуют собственные клиентские библиотеки.