Просмотр моделей интеллектуального анализа (деревья решений, упрощенный алгоритма Байеса, нейронные сети). Написание "одноэлементных" прогнозирующих запросов
В среде BIDevStudio откроем созданную в ходе выполнения предыдущих лабораторных работ базу данных аналитических служб. В ней - откроем в редакторе структуру vTargetMail_Structure2, которую создавали в "Задача классификации. Создание структуры и моделей интеллектуального анализа. Сравнение точности моделей" . Перейдем на вкладку MiningModelViewer и в выпадающем списке MimingModel выберем модель vTargetMail_NB, основанную на использовании упрощенного алгоритма Байеса ( рис. 30.1)

После проведения обработки, модель интеллектуального анализа данных хранит метаданные о себе, собранную статистику, а также закономерности, выявленные алгоритмом интеллектуального анализа данных. Способ описания закономерностей зависит от используемого алгоритма.
Среда BIDevStudio предоставляет инструменты, позволяющие ознакомиться с содержимым модели. В частности, это представленные на рис. 30.1 диаграммы (вид диаграммы зависит от используемого алгоритма). В случае упрощенного алгоритма Байеса можно использовать диаграмму типа "сеть зависимостей"(DependencyNetwork) для того, чтобы увидеть, насколько значения одних атрибутов влияют на значения других.
Если на диаграмме ( рис. 30.1) щелчком мыши выделить целевой атрибут (BikeBuyer) и передвинуть вниз "бегунок" AllLinks в левой части экрана, то можно увидеть, что в наибольшей степени на решение о приобретении велосипеда влияет число машин в собственности у клиента ( рис. 30.2).

Вкладка AttributeDiscrimination позволяет увидеть, какие значения входных атрибутов в наибольшей степени соответствующие тому или иному значению выходного ( рис. 30.3). Из представленных на рисунке данных можно сделать вывод, что отсутствие машины у клиента с большой вероятностью приведет его к покупке велосипеда. Похожие диаграммы мы видели в Excel, в ходе выполнения "Использование инструментов "AnalyzeKeyInfluencers" и "DetectCategories"" , посвященной использованию инструмента "Анализ ключевых факторов влияния".

увеличить изображение
Рис. 30.3. Сравнение наборов значений входных атрибутов, соответствующих выбранным значениям выходного атрибута
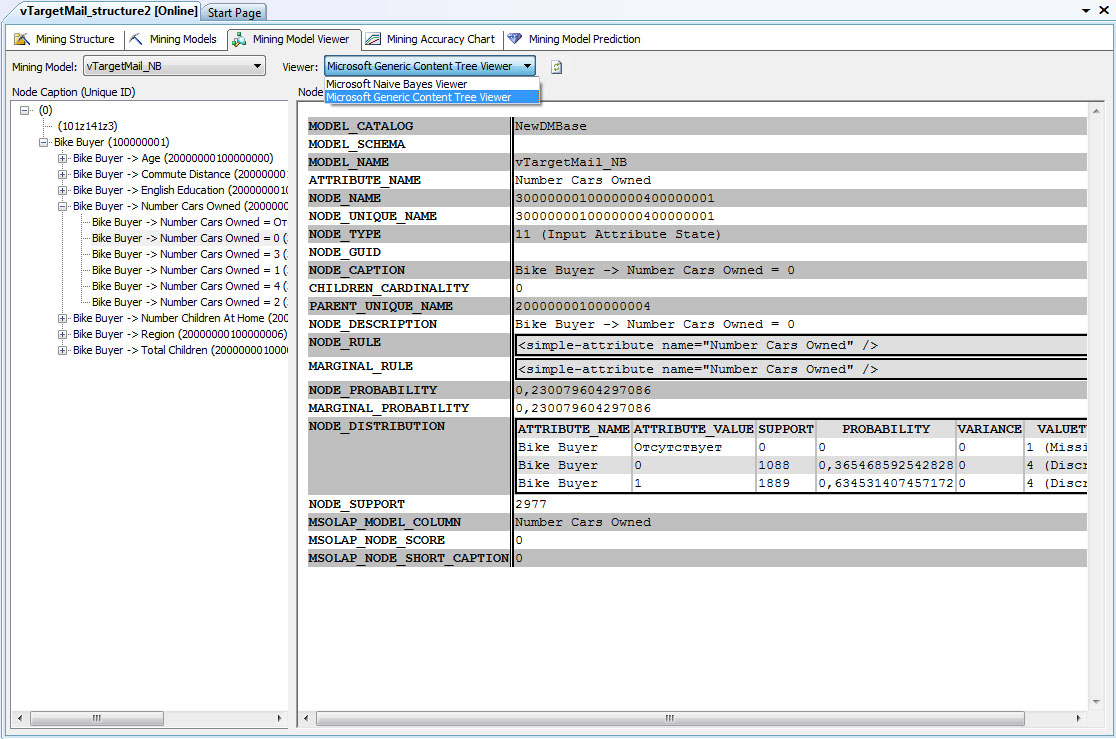
Еще более подробно ознакомиться с содержимым модели позволяет средство просмотра MicrosoftGenericContentTreeViewer. Если открыть в нем нашу модель vTargetMail_NB можно увидеть содержимое модели в виде иерархии узлов. На рис. 30.4 представлено содержимое узла, соответствующее ситуации, когда у клиента нет машин (атрибут NumberCars= 0). Из 2977 вариантов, в которых это значение встречается, 1889 клиентов купили велосипед (это примерно 63%) и 1088 (37%) не купили.
Для модели vTargetMail_DT, использующей на алгоритм деревьев принятия решений,первой показывается одноименная диаграмма DecisionTree ( рис. 30.5).На ней отображаются узлы построенного дерева, а выбор любого конечного узла позволяет понять, как алгоритм будет строить прогноз для соответствующей комбинации значений входных параметров. Например, на рисунке показано, что для клиента имеющего две машины, проживающего в регионе Pacific(Тихоокеанский), возрастом менее 43 лет будет сделан положительный прогноз относительно покупки им велосипеда, т.к. из 103 подобных клиентов в обучающей выборке 84 сделали покупку.
Также для моделей на основе алгоритма деревьев принятия решения можно получить рассмотренные выше диаграммы типа "сеть зависимостей".

Для основанной на алгоритме нейронных сетей модели vTargetMail_DT будет отображаться диаграмма попарного сравнения вариантов, аналогичная представленной на рис. 30.3.
Построение прогнозов
Вернемся к модели vTargetMail_DT, которая как мы выяснили в "Задача классификации. Создание структуры и моделей интеллектуального анализа. Сравнение точности моделей" , дает наиболее точный прогноз. Попробуем сейчас построить прогноз для отдельного варианта. Можно это представить как попытку узнать купит ли человек, заполнивший анкету велосипед или нет.
Перейдем на вкладку построителя запросов MiningModelPrediction. В окне MiningModel нажмите кнопку SelectModel и выберите в структуре vTargetMail_Structure2 модель vTargetMail_DT ( рис. 30.6).

В связи с тем, что прогноз мы хотим построить для одного варианта, значения атрибутов которого будем вводить вручную, в контекстном меню выберем соответствующий тип запроса - SingletonQuery, что можно перевести как "одноэлементный запрос" ( рис. 30.7). После чего зададим набор параметров, характеризующих нового клиента. При этом значение атрибута BikeBuyer не указываем ( рис. 30.8).


Таким образом, вариант мы определили теперь надо указать цель запроса. Во -первых, мы хотим узнать значение атрибута BikeBuyer. Для этого, находясь в режиме конструктора (Design) в нижней части окна в списке Source выбираем модель vTargetMail_DT и автоматически будет подставлен выходной атрибут BikeBuyer ( рис. 30.9). Кроме того, мы хотим узнать оценку вероятности, для выполняемого прогноза. Для этого нам понадобиться функция PridictProbability с указанием столбца [vTargetMail_DT].[BikeBuyer] в качестве аргумента ( рис. 30.10).


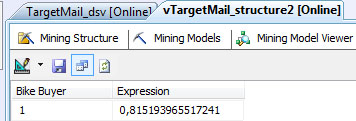
Если нажать кнопку переключения в режим просмотра результатов прогнозирующего запроса (Switchtoqueryresultview в верхней левой части окна) мы увидим предсказываемое значение и оценку вероятности ( рис. 30.11)
А переключившись в режим Query увидим сгенерированный код запроса на языке DMX:
SELECT
[vTargetMail_DT].[Bike Buyer],
PredictProbability([vTargetMail_DT].[Bike Buyer])
From
[vTargetMail_DT]
NATURAL PREDICTION JOIN
(SELECT 36 AS [Age],
'5-10 Miles' AS [Commute Distance],
'Bachelors' AS [English Education],
2 AS [Number Cars Owned],
0 AS [Number Children At Home],
'Pacific' AS [Region],
1 AS [Total Children],
NULL AS [Yearly Income]) AS t
Задание 2. Постройте с помощью конструктора несколько запросов к созданным моделям интеллектуального анализа данных. Выполните их. Проанализируйте результат. Разберите сгенерированный код на языке DMX.
Обратите внимание на то, что результаты запроса можно сохранить в базу данных в качестве новой таблицы, при этом можно добавить эту таблицу в существующее представление источника данных.