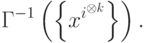Нейронные сети ассоциативной памяти
Тензорные сети
Для увеличения числа линейно независимых эталонов, не приводящих к прозрачности сети, используется прием перехода к тензорным или многочастичным сетям [8.3, 8.4, 8.5, 8.6, 8.7].
Тензорным произведением 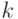
 -мерных векторов
-мерных векторов  называется
-индексная величина
называется
-индексная величина 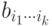 , у которой все индексы независимо пробегают весь набор значений от единицы до , а
, у которой все индексы независимо пробегают весь набор значений от единицы до , а  . -ой тензорной степенью вектора
. -ой тензорной степенью вектора 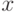 будем называть вектор
будем называть вектор  , полученный как тензорное произведение векторов . Вектор
, полученный как тензорное произведение векторов . Вектор  является
является  -мерным вектором. Однако пространство
-мерным вектором. Однако пространство  имеет размерность, не превышающую величину
имеет размерность, не превышающую величину  , где
, где  - число сочетаний из
- число сочетаний из 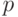 по
по 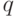 .
.
Теорема. При k < n в ранг  множества
множества  равен: .
равен: .

Небольшая модернизация треугольника Паскаля, позволяет легко вычислять эту величину. На рис. 8.2 приведен "тензорный" треугольник Паскаля. При его построении использованы следующие правила:
- Первая строка содержит двойку, поскольку при n=2 в множестве X всего два неколлинеарных вектора.
- При переходе к новой строке, первый элемент получается добавлением единицы к первому элементу предыдущей строки, второй - как сумма первого и второго элементов предыдущей строки, третий - как сумма второго и третьего элементов и т.д. Последний элемент получается удвоением последнего элемента предыдущей строки.
| n | k | nk | Ck - 1n + k - 1 | rn,k |
|---|---|---|---|---|
| 5 | 2 | 25 | 15 | 11 |
| 3 | 125 | 35 | 15 | |
| 10 | 3 | 1 000 | 220 | 130 |
| 6 | 1 000 000 | 5005 | 466 | |
| 8 | 100 000 000 | 24310 | 511 |
В
таблица
8.1 приведено сравнение трех оценок информационной емкости тензорных сетей для некоторых значений n и k. Первая оценка - - заведомо завышена, вторая -  - дается формулой Эйлера для размерности пространства симметричных тензоров и третья - точное значение
- дается формулой Эйлера для размерности пространства симметричных тензоров и третья - точное значение
Как легко видеть из таблицы
таблица
8.1, уточнение при переходе к оценке  является весьма существенным. С другой стороны, предельная информационная емкость тензорной сети (число правильно воспроизводимых образов) может существенно превышать число нейронов, например, для 10 нейронов тензорная сеть валентности 8 имеет предельную информационную емкость 511.
является весьма существенным. С другой стороны, предельная информационная емкость тензорной сети (число правильно воспроизводимых образов) может существенно превышать число нейронов, например, для 10 нейронов тензорная сеть валентности 8 имеет предельную информационную емкость 511.
Легко показать, что если множество векторов  не содержит взаимно обратных, то размерность пространства
не содержит взаимно обратных, то размерность пространства  равна числу векторов в множестве . Сеть (2) для случая тензорных сетей имеет вид
равна числу векторов в множестве . Сеть (2) для случая тензорных сетей имеет вид
 |
( 9) |
а ортогональная тензорная сеть
 |
( 10) |
где  - элемент матрицы
- элемент матрицы