Нейронные сети ассоциативной памяти
Ортогональные сети
Для обеспечения правильного воспроизведения эталонов достаточно потребовать, чтобы первое преобразование в (5) было таким, что  . Очевидно, что если проектор является ортогональным, то это требование выполняется, поскольку
. Очевидно, что если проектор является ортогональным, то это требование выполняется, поскольку 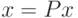 при
при  , а
, а 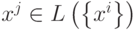 по определению множества
по определению множества 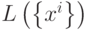 .
.
Для обеспечения ортогональности проектора воспользуемся дуальным множеством векторов. Множество векторов  называется дуальным к множеству векторов
называется дуальным к множеству векторов  если все вектора этого множества
если все вектора этого множества 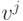 удовлетворяют следующим требованиям:
удовлетворяют следующим требованиям:
-
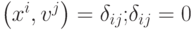 , при
, при  при
при 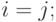
-
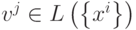 .
.
Преобразование 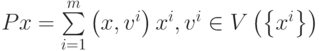 является ортогональным проектором на линейное пространство .
является ортогональным проектором на линейное пространство .
Ортогональная сеть ассоциативной памяти преобразует образы по формуле
 |
( 6) |
Дуальное множество векторов существует тогда и только тогда, когда множество векторов линейно независимо. Если множество эталонов линейно зависимо, то исключим из него линейно зависимые образы и будем рассматривать полученное усеченное множество эталонов как основу для построения дуального множества и преобразования (6). Образы, исключенные из исходного множества эталонов, будут по-прежнему сохраняться сетью в исходном виде (преобразовываться в самих себя). Действительно, пусть эталон 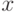 является линейно зависимым от остальных
является линейно зависимым от остальных 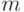 эталонов. Тогда его можно представить в виде
эталонов. Тогда его можно представить в виде
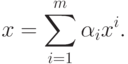
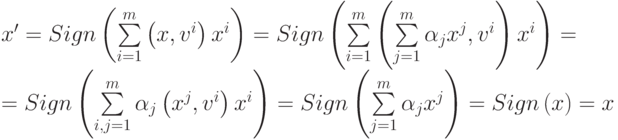 |
( 7) |
Рассмотрим свойства сети (6) [8.2]. Во-первых, количество запоминаемых и точно воспроизводимых эталонов не зависит от степени их скоррелированности. Во-вторых, формально сеть способна работать без искажений при любом возможном числе эталонов (всего их может быть до  ). Однако, если число линейно независимых эталонов (т.е. ранг множества эталонов) равно
). Однако, если число линейно независимых эталонов (т.е. ранг множества эталонов) равно  , сеть становится прозрачной - какой бы образ не предъявили на ее вход, на выходе окажется тот же образ. Действительно, как было показано в (7), все образы, линейно зависимые от эталонов, преобразуются проективной частью преобразования (6) сами в себя. Значит, если в множестве эталонов есть линейно независимых, то любой образ можно представить в виде линейной комбинации эталонов (точнее линейно независимых эталонов), а проективная часть преобразования (6) в силу формулы (7) переводит любую линейную комбинацию эталонов в саму себя.
, сеть становится прозрачной - какой бы образ не предъявили на ее вход, на выходе окажется тот же образ. Действительно, как было показано в (7), все образы, линейно зависимые от эталонов, преобразуются проективной частью преобразования (6) сами в себя. Значит, если в множестве эталонов есть линейно независимых, то любой образ можно представить в виде линейной комбинации эталонов (точнее линейно независимых эталонов), а проективная часть преобразования (6) в силу формулы (7) переводит любую линейную комбинацию эталонов в саму себя.
Если число линейно независимых эталонов меньше n , то сеть преобразует поступающий образ, отфильтровывая помехи, ортогональные всем эталонам.
Отметим, что результаты работы сетей (3) и (6) эквивалентны, если все эталоны попарно ортогональны.
Остановимся несколько подробнее на алгоритме вычисления дуального множества векторов. Обозначим через 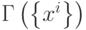 матрицу Грамма множества векторов . Элементы матрицы Грамма имеют вид
матрицу Грамма множества векторов . Элементы матрицы Грамма имеют вид  (
(  -ый элемент матрицы Грамма равен скалярному произведению
-ый элемент матрицы Грамма равен скалярному произведению 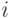 -го эталона на
-го эталона на 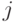 -ый). Известно, что векторы дуального множества можно записать в следующем виде:
-ый). Известно, что векторы дуального множества можно записать в следующем виде:
 |
( 8) |
где  - элемент матрицы
- элемент матрицы 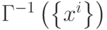 . Поскольку определитель матрицы Грамма равен нулю, если множество векторов линейно зависимо, то матрица, обратная к матрице Грамма, а следовательно и дуальное множество векторов существует только тогда, когда множество эталонов линейно независимо.
. Поскольку определитель матрицы Грамма равен нулю, если множество векторов линейно зависимо, то матрица, обратная к матрице Грамма, а следовательно и дуальное множество векторов существует только тогда, когда множество эталонов линейно независимо.
Для работы сети (6) необходимо хранить эталоны и матрицу .
Рассмотрим процедуру добавления нового эталона к сети (6). Эта операция часто называется дообучением сети. Важным критерием оценки алгоритма формирования сети является соотношение вычислительных затрат на обучение и дообучение. Затраты на дообучение не должны зависеть от числа освоенных ранее эталонов.
Для сетей Хопфилда это, очевидно, выполняется - добавление еще одного эталона сводится к прибавлению к функции H одного слагаемого  , а модификация связей в сети - состоит в прибавлении к весу ij -й связи числа
, а модификация связей в сети - состоит в прибавлении к весу ij -й связи числа 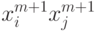 - всего
- всего 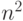 операций.
операций.