Интегрированная база данных
Машинные индексы
Перейдем к последней теме, связанной с нижним уровнем поддержки базы данных в AS/400 — к индексам. Мы уже обсуждали два вида индексов: независимый (в "Объекты" ) и индекс области данных (в этой лекции). Повторю, что оба этих системных объекта содержат дерево с двоичным основанием.
Итак, что такое индекс? На мой взгляд, наиболее удачное определение таково: индекс — организованный набор информации для быстрого поиска в наборе элементов, например в большой таблице. Индексация играет важную роль в реализации многих компонентов AS/400 и любой другой системы. Поэтому еще при проектировании System/38 было принято решение встроить ниже MI максимально эффективный индекс таким образом, чтобы все системные компоненты могли при необходимости использовать его, а не создавать свои собственные. Этот встроенный индекс и называется машинным индексом.
Машинный индекс полезен различным компонентам AS/400 при поиске в таблицах, адресации областей, сортировке и т. д. База данных применяет его при индексации области данных, работе со списком транзакций журнала и т. п.; компонент управление памятью — для многих своих справочников. Машинные индексы используются и в контекстах, и для поиска прав доступа. OS/400 использует объекты типа "независимый индекс" для нескольких целей, включая обработку сообщений, защиту и спулинг.
Основные характеристики машинного индекса таковы:
- обеспечивает обобщенный поиск, позволяя находить группы связанных элементов;
- управляет используемым пространством;
- позволяет минимизировать случаи отсутствия нужной страницы в памяти (страничные ошибки);
- поддерживает ключи переменной длины до 2048 байтов;
- использует алгоритм двоичного поиска;
- хранит элементы в виде фрагментированного дерева с двоичным основанием (подробнее — в разделе "Внутренняя организация дерева с двоичным основанием" этой лекции).
Двоичный поиск
Проще всего понять, что такое двоичный поиск, можно на примере игры в угадывание чисел. Смысл игры в том, что один игрок задумывает число внутри некоторого диапазона, например между 1 и 1000, а второй — пытается угадать это число за минимально возможное количество попыток. При каждой попытке второму игроку сообщается, является ли названное им число большим, меньшим или равным задуманному.
Прием быстрого угадывания чисел в этой игре основан на двоичной системе счисления. Чтобы угадать число между 1 и 1000, при первой попытке следует назвать 512 (29 = 512). Если нам скажут, что это число слишком велико, то задуманное число больше нуля и меньше 512, поэтому далее мы называем 256 (28 = 256) — следующую меньшую степень двойки. Если же сказано, что названное число меньше задуманного, то задумано число большее 512 и для следующей попытки нужно прибавить 256 к 512 и назвать 768, и при каждой следующей попытке прибавлять следующую меньшую степень двойки. Если названное число больше задуманного, мы вычитаем эту степень двойки и прибавляем следующую меньшую степень.
Предположим, что первый игрок задумал 700. Отгадывающему следует называть такую последовательность чисел: 512, 768, 640, 704, 672, 688, 696 и, наконец, 700. При этом ему будет сообщаться, что первое число меньше, второе больше, третье меньше и т. д. На основании этой информации он будет вычислять следующее значение и, в конце концов, задуманное число будет отгадано за восемь попыток.
Если мы посмотрим на последовательность ответов первого "больше/меньше" из приведенного примера, то заметим интересную закономерность. Эта последовательность выглядит так: "меньше", "больше", "меньше", "больше", "меньше", "меньше", "меньше" и "равно". Если на место каждого ответа "больше" подставить 0, а на место каждого ответа "меньше" — 1, то мы получим двоичное число. Учитывая, что для задания любого числа между 1 и 1000 требуется 10 разрядов, можно представить 700 как 1010111100. Мы угадали это число, двигаясь слева направо и используя ответы "больше/меньше" для определения двоичной цифры в текущей позиции.
С использованием данного метода задуманное число всегда может быть найдено не более чем за 10 попыток. В нашем примере потребовалось только восемь попыток, так как число делится на 4 — степень двойки. Обратите внимание, что любое нечетное число потребует 10 попыток, по одной на разряд. Максимальное число попыток можно вычислить как логарифм 1000 по основанию 2. Иначе это значение можно определить, учитывая, что 210 = 1024. Для угадывания числа между единицей и миллионом по данному методу требуется лишь 20 или менее попыток. Приведенный при мер иллюстрирует алгоритм двоичного поиска, который применяется для нахождения элемента индекса.
Структура, в которой все записи заполнены, считается сбалансированной. При поиске по сбалансированному индексу с n элементами требуется выполнить сравнение лишь для log2 n элементов. Наш пример с угадыванием чисел был сбалансированным, так как в последовательности присутствуют все числа. Но даже для сильно несбалансированных структур среднее число попыток возрастает менее чем на 10 процентов. Алгоритм двоичного поиска отлично работает для большого числа элементов, но обычно не рекомендуется, если их число меньше 50.
Деревья с двоичным основанием
Описанный выше метод двоичного поиска можно представить в виде древовидной структуры. Дерево будет содержать два типа узлов: тестовые и окончательные. Каждый тестовый узел дерева проверяет один разряд числа. По тому, равен разряд 1 или 0, в качестве следующего выбирается один из двух узлов следующего уровня. Начиная с вершины дерева10В информатике деревья всегда растут вверх ногами. Где еще корень расположен наверху, а ветви тянутся вниз?, первый узел проверяет первый разряд числа (самый левый). Второй слой дерева содержит два текстовых узла, один из которых выбирается, если первый разряд был равен 0, а другой — если первый разряд был равен 1. На третьем уровне имеется четыре узла, на четвертом — восемь и так далее вплоть до десятого узла, на котором расположено 512 тестовых узлов. Одиннадцатый уровень — последний для данного дерева и содержит 1024 окончательных узла. Окончательный узел содержит точное значение искомого числа.
Итак, для поиска числа мы начинаем с вершины дерева и проверяем разряды слева направо. На каждом уровне дерева проверяется один из разрядов. После десяти проверок мы оказываемся в одном из окончательных узлов и можем точно назвать число.
Мы только что описали двоичное дерево. Оно сбалансированное, так как присутствуют все узлы. При поиске по таблице могут присутствовать не все узлы, так как в таблице присутствуют не все возможные элементы. Следовательно, и проверяются не все разряды числа, некоторые уровни могут отсутствовать. Такое дерево в отличии от двоичного дерева, где присутствуют все узлы, называется деревом с двоичным основанием (binary radix tree).
Использование деревьев с двоичным основанием в AS/400 для реализации машинных индексов мы рассмотрим на примере рисунка 6.4. На нем показан простой файл из девяти записей, упорядоченных в порядке поступления. Каждая запись имеет несколько полей, на рисунке показаны лишь некоторые. Одно из полей — поле имени — предназначено для использования в качестве ключа. Для файла построен индекс, который также показан на рисунке. Каждая запись индекса имеет только два поля: поле ключа и логический адрес записи. Девять элементов индекса отсортированы по порядку значений ключа. В данном случае, ключи отсортированы по алфавиту, и первым элементом является Baker, а последним Wu. Поле логического адреса записи задает относительную позицию соответствующей записи в исходном файле, логическая адресация всегда начинается с 0 (для первой записи). Элемент для Baker указывает, что запись Baker является в файле седьмой.
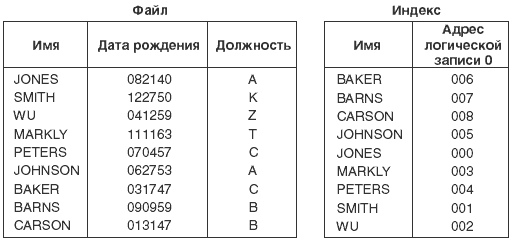
Точный формат логического адреса записи изменяется на AS/400 в зависимости от того, как используется индекс. Например, как уже говорилось, каждый элемент сегмента индекса области данных содержит ключ и относительный адрес, в свою очередь включающий в себя номер области данных, идентификацию сегмента области данных записей и порядковый номер записи. Данный относительный адрес уникальным образом идентифицирует запись, соответствующую ключу. В других случаях применения индекса используется иная форма относительных адресов.
Давайте с помощью этого индекса создадим дерево с двоичным основанием. На рисунке 6.5 показан индекс с рисунка 6.4 с представлением поля ключа в коде EBCDIC. Индекс представлен в шестнадцатеричной и двоичной формах. Например, первая буква имени Baker имеет шестнадцатеричное значение С2. В двоичной системе счисления С2 будет 11000010. Вторая буква имени Baker имеет шестнадцатеричное значение С1 (11000001 двоичное). Каждый ключ располагается в памяти в виде цепочки нулей и единиц, как показано на рисунке.
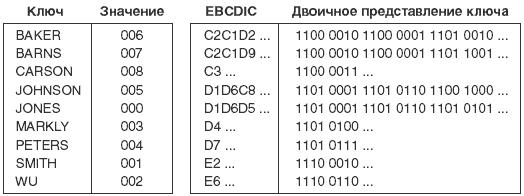
Теперь с помощью двоичного представления ключей можно создать дерево с двоичным основанием. При построении дерева ключи добавляются по одному. Сначала последовательность битов каждого нового ключа просматривается слева направо в поисках первого, отличающего данный ключ от всех ключей, уже вставленных в дерево. Предположим, что единственным элементом дерева является Baker и мы хотим добавить элемент Barns. Взглянув на рисунок 6.5, можно увидеть, что первым отличающимся битом (сканирование всегда идет слева направо) будет пятый в третьем байте. Если в дереве только два элемента Baker и Barns, то чтобы отличить один от другого, достаточно проверить пятый разряд третьего байта. Если разряд равен 0, то это элемент Baker, а если 1, то Barns.
Допустим, теперь мы хотим добавить к дереву Carson. Тогда первым битом, отличающимся и от Baker, и от Barns, будет восьмой первого байта.
Последовательность построения дерева показана на рисунке 6.6. На первом шаге в дереве есть единственный окончательный узел для Baker. Окончательный узел содержит некоторый текст (в данном случае "Baker") и логический адрес записи 006. На втором шаге к дереву добавляется Barns. Здесь к дереву непосредственно над Baker добавляется тестовый узел для проверки пятого разряда третьего байта. Тестовый узел содержит общий текст ключей (BA) и номер бита, который должен проверяться в следующем байте. В нашем примере с двумя байтами совпадающего текста (ВА) ясно, что бит, нуждающийся в проверке, находится в следующем (третьем) байте, задавать который явно не обязательно. При выборе следующего узла всегда берется левый, если проверяемый бит равен 0, и правый — в противоположном случае. Справа от первого окончательного узла добавлен второй окончательный узел для Barns с логическим адресом записи 007. Обратите внимание, что после удаления общего текста, терминальные узлы содержат только остатки имен (KER и RNS для Baker и Barns соответственно).
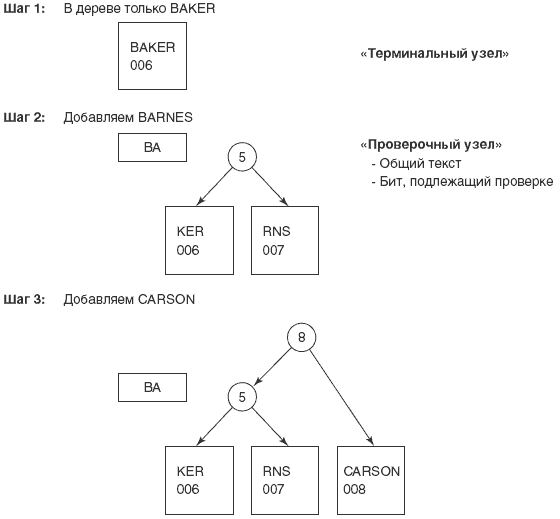
На шаге 3 к дереву добавляется Carson. Создается новый тестовый узел для проверки восьмого бита первого байта. В новом тестовом узле нет общего текста. Если при проверке восьмой бит первого байта равен 0, то далее следует проверить расположенный левее тестовый узел для Baker/Barns. Если же восьмой бит первого байта равен 1, то следующим будет окончательный узел справа для Carson. Данный узел содержит текст (CARSON) и логический адрес записи 008.
На рисунке 6.7 дерево показано полностью, со всеми девятью элементами. Тестовый узел наверху дерева называется корневым узлом. Хотя в данном примере представлен относительно небольшой индекс, он иллюстрирует многие характеристики дерева с двоичным основанием.

Любое имя в дереве может быть найдено уже описанным методом. Но как быть с именами, которых в дереве нет? Предположим, что мы пытаемся найти там имя Soltis. Проверяем третий бит первого байта и видим, что он равен 1, затем — шестой бит первого байта, который равен 0. Это приводит нас к окончательному узлу для Smith. Теперь понятна причина хранения текста в окончательных узлах — на один и тот же окончательный узел может отображаться много имен. При достижении окончатель ного узла необходимо сравнить хранящийся там текст с остатком имени, поиск которого мы ведем. Если они совпали — мы нашли правильный окончательный узел, если нет — искомое имя отсутствует в дереве.
Другая характеристика дерева связана со способом добавления к нему элементов. Мы всегда просматриваем строку битов для каждого нового элемента слева направо в поиске первого бита нового ключа, отличающего его от всех, уже находящихся в дереве. Таким образом, гарантируется, что при проходе по любому пути в дереве биты проверяются слева направо. В тестовом узле никогда не приходится возвращаться к началу имени: мы всегда движемся вперед.
Метод, используемый для вставки элементов, также гарантирует, что дерево всегда будет иметь одну и ту же конфигурацию, независимо от порядка добавления элементов. Более того, окончательные узлы всегда упорядочены в соответствии со значениями ключей слева направо. В нашем примере, окончательные узлы расположены в алфавитном порядке имен в ключевом поле. Это не случайность, а свойство дерева. Дерево само по себе обеспечивает логическую последовательность ключей, так что сортировка физических записей не нужна.
Элемент дерева можно также удалить. Это простая операция, так как на окончательный узел может указывать один и только один тестовый узел. Возьмите имя, подлежащее удалению, отыщите в дереве соответствующий ему окончательный узел, удалите его, вернитесь к расположенному выше тестовому узлу и объедините его со вторым окончательным узлом в новый окончательный узел.
Внутренняя организация дерева с двоичным основанием
Внутренняя форма хранения дерева с двоичным основанием оптимизирована как с точки зрения производительности, так и занимаемого пространства. Первая базовая структура для дерева с двоичным основанием была создана инженером Филом Ховардом (Phil Howard) в 70х годах. В его схеме правый и левый потомки тестового узла вместе с возможным общим текстом объединены в кластер. Такие кластеры располагались в памяти один за другим, и для ссылки на кластер использовалось его положение в цепочке. Это устраняло необходимость учета адресов для ссылки на следующий узел.
Фил изобрел очень элегантный механизм перемещения от одного узла дерева к другому. Кластер не содержал адресов следующего или предыдущего узла. Вместо этого, их положения определялись с помощью операции XOR, что позволяло перемещаться по дереву в обоих направлениях. Этим достигалась еще и экономия памяти, поскольку не нужно было хранить прямые и обратные ссылки на предыдущие и последующие узлы.
Чтобы найти следующий узел дерева, операция XOR выполняется над значением, хранящимся в текущем узле, и позицией предыдущего узла. Ясно, что значение, хранящееся в текущем узле, — результат XOR над позициями следующего и предыдущего узлов. Таким образом, чтобы вычислить местоположение следующего узла, нужно знать лишь текущее значение и позицию предыдущего узла. Предположим, что мы хотим пройти по дереву в обратном направлении. Выполнив операцию XOR над значением в текущем узле и позицией следующего узла, мы получаем позицию предыдущего узла. Таким образом, из любой точки дерева, зная предыдущую, текущую и следующие позиции, а также содержимое текущего узла, можно перемещаться вверх и вниз без ссылок. Для хранения нужных нам трех позиций годится простой стек.
Реализация дерева с двоичным основанием минимизирует число страничных ошибок путем разделения дерева на поддеревья. Формально, такую структуру следовало бы называть фрагментированным деревом с двоичным основанием. При переполнении страницы, выше по дереву выполняется разделение, и к индексу добавляются новые поддеревья.
Предположим, мы решили разделить дерево из нашего примера на рисунке 6.7. Разумно поместить на одну страницу все терминальные узлы от Baker до Peters вместе с их тестовыми узлами, а на вторую — терминальные узлы от Smith до Wu, а также один указывающий на них тестовый узел.
Однако, здесь нас подстерегает неприятность. В узлах нет адресов для связи с другими узлами — вместо этого используются относительные номера позиций. Чтобы попасть на другую страницу памяти, необходим адрес. Решение состоит в создании узла нового типа, который будет содержать адрес и позволит ссылаться на другую страницу дерева. Если верхний узел нашего примера — корневой узел — поместить на третью страницу и разместить в нем указатели на две другие, то мы получим фрагментированное дерево. Верхние узлы на всех трех страницах теперь являются корневым узлами для своих страниц, и мы значительно увеличили максимальный объем памяти, которая может использоваться для хранения данного дерева.
Другое преимущество фрагментирования — то, что, попав в процессе поиска на некоторую страницу памяти, содержащую фрагмент дерева, мы остаемся на ней на всех уровнях тестирования. Перед переходом на следующую страницу все тестовые узлы данной страницы на пути поиска будут просмотрены. Кроме того, поскольку для поиска в очень больших индексах требуется относительно немного проверок (вспомните, что при поиске в индексе из миллиона записей требуется, в среднем, только 20 проверок), то лишь в редких случаях придется затронуть более однойдвух страниц. В результате, данная схема обеспечивает наивысшую производительность по сравнению со всеми иными известными схемами индексации.
Выводы
Интегрированная база данных дает AS/400 целый ряд преимуществ, обеспечивая недостижимый для других систем уровень эффективности и производительности. Многие из этих преимуществ были нами рассмотрены. Так как база данных AS/400 не "сидит" поверх ОС, ею могут пользоваться все компоненты системы. База данных AS/400 не изолирована от других компонентов, как на обычных системах.
База данных AS/400 позволяет приложениям, написанным для различных интерфейсов, сосуществовать и работать с одними и теми же данными, обеспечивая непосредственную реализацию на AS/400 внешних интерфейсов и инструментария других баз данных. Следовательно, и приложения, написанные для иных баз данных, уже сейчас могут работать прямо на AS/400, используя данные совместно с остальными приложениями. В будущем эти возможности станут еще более значимы.
Интегрированная защита AS/400 защищает базу данных и другие компоненты системы от несанкционированного доступа и предотвращает разрушение данных. В "Защита от несанкционированного доступа" , мы рассмотрим эту интегрированную защиту, а также управление доступом в SLIC.