Лекция 10: Динамические LPAR (DLPAR) и виртуализация (VIO)
Конфигурация тестового кластера
Наша тестовая конфигурация состоит из трех LPAR на двух системах p690s: двух рабочих LPAR (Jordan, Jessica) на одной системе p690 (itso_p690_1) и одного дежурного LPAR (Alexis) на второй системе p690 (itso_p690_2). Каждая система p690 содержит восемь процессоров и 8 Гб памяти и подключена к двум консолям HMC в целях обеспечения избыточности.
В каждом разделе установлены следующие версии программного обеспечения:
- AIX 5.2 ML5;
- HACMP 5.2.0.3;
- RSCT 2.3.5.0;
- rpm-3.0.5-37.aix5.1;
- OpenSSH 3.8.1p1 (и следующие обязательные пакеты):
- zlib 1.2.1-2;
- prngd 0.9.23-3;
- openssl 0.9.7d-2.
В каждом разделе установлены следующие адаптеры:
Оба HMC имеют:
Наши тестовые LPAR и соответствующие фреймы см. на рис. 10.5.
В качестве общего хранилища мы использовали ESS с восьмью LUN на 10 Гб, четыре из которых назначены рабочим группам ресурсов. Для тестирования общее хранилище не было важным; оно предназначалось только для настройки более полной конфигурации кластера с использованием мониторинга пульса через диски.
Для этих LPAR сконфигурированы параметры разделов, представленные в табл. 10.5.
| Имя LPAR | Минимальное значение | Желаемое значение | Максимальное значен |
|---|---|---|---|
| Jordan | 1 процессор – 1 Гб | 1 процессор – 1 Гб | 4 процессора – 4 Гб |
| Jessica | 1 процессор – 1 Гб | 1 процессор – 1 Гб | 2 процессора – 2 Гб |
| Alexis | 1 процессор – 1 Гб | 1 процессор – 1 Гб | 6 процессоров – 6 Гб |
У нас сконфигурировано две группы ресурсов (app1_rg и app2_rg), каждая из которых содержит свои серверы приложений – app1 и app2 соответственно. Каждая группа ресурсов конфигурируется как подключающаяся на домашнем узле (online on home node). App1_rg содержит участвующие узлы Jordan и Alexis. App2_rg содержит участвующие узлы Jessica и Alexis. В итоге получается кластер с конфигурацией 2+1, где узел Alexis является дежурным (standby node).

Для каждого узла связи с HMC были настроены таким образом, чтобы включать обе консоли HMC с IP-адресами 192.168.100.69 и 192.168.100.5.
Параметры конфигурации DLPAR для серверов приложений представлены в табл. 10.6.
| Сервер приложения | Минимальное значение | Желаемое значение |
|---|---|---|
| app1 | 0 | 3 |
| app2 | 0 | 2 |
Мы специально установили минимальные, нулевые, значения, чтобы всегда можно было получить группу ресурсов.
Результаты тестирования
Сценарий 1: получение группы ресурсов
В этом сценарии мы начинаем со следующей конфигурации:
- на узле Jordan выделен 1 процессор/1 Гб памяти;
- свободный пул содержит 7 процессоров/7 Гб памяти.
При запуске служб кластера на узле Jordan app1 запускается локально и пытается получить оптимальное количество ресурсов. Так как свободный пул содержит достаточно ресурсов, он получает еще 3 процессора и 3 Гб памяти, как показано на рис. 10.6.

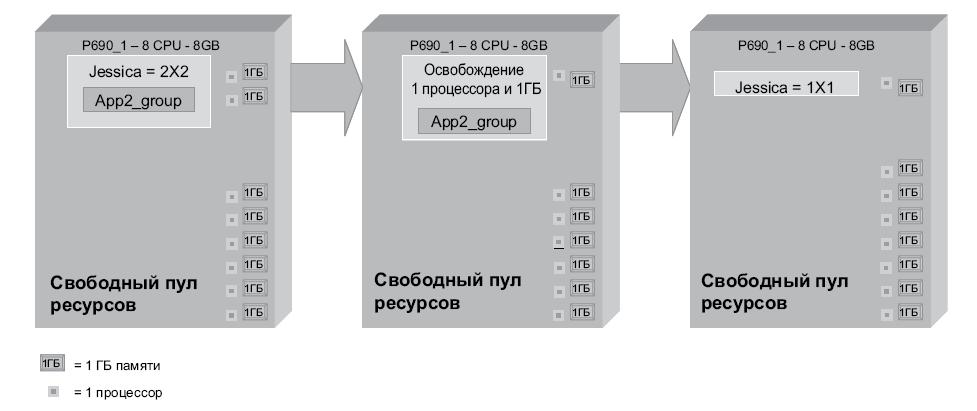
Сценарий 2: освобождение группы ресурсов
В этом сценарии узел Jessica подключен в кластере с запущенным сервером приложения app2 при максимальных значениях: 2 процессора и 2 Гб.
При остановке служб кластера на узле Jessica сервер приложения app2 останавливается локально и освобождает ресурсы обратно в свободный пул. При этом HACMP не освобождает больше ресурсов, чем изначально было получено.
На рис. 10.7 представлено освобождение ресурсов и их перемещение обратно в свободный пул.
Сценарий 3: последовательное перемещение при сбое для каждого LPAR
Этот сценарий состоит из двух частей, при котором выполняется перемещение при сбое для каждого раздела: сначала для узла Jordan, затем для узла Jessica. Это демонстрирует, что во время перемещения при сбое получение ресурсов выполняется подобно получению локальной группы ресурсов.
Также мы покажем различия между этим сценарием и сценарием 4, "Перемещение при сбое для рабочих LPAR в обратном порядке", в общем количестве ресурсов на дежурном узле.
В первой части инициируется отказ узла Jordan командой reboot -q. При этом происходит перемещение при сбое на узле Alexis. Alexis получает группу ресурсов app1 и выделяет желаемое количество ресурсов, как показано на рис. 10.8.

Узел Alexis теперь имеет такое же количество ресурсов, как и первый отказавший узел.
Вторая часть этого сценария начинается со следующей конфигурации:
- узел Jordan отключен;
- узел Jessica имеет 2 процессора и 2 Гб памяти;
- узел Alexis имеет 4 процессора и 4 Гб памяти;
- свободный пул (фрейм 2) содержит 4 процессора и 4 Гб памяти.
Теперь инициируется отказ узла Jessica командой reboot -q. Узел Alexis перехватывает группу ресурсов app2 и получает желаемое количество ресурсов, как показано на рис. 10.9.
В конечном итоге Alexis остается с максимальными параметрами раздела: 6 процессоров и 6 Гб памяти.
