Обслуживание кластера
Остановка служб кластера
Ниже приведен список действий, представляющих процедуру остановки служб кластера на одном узле, на нескольких узлах или на всех узлах кластера с использованием утилиты C-SPOC на одном из узлов кластера. C-SPOC останавливает узлы последовательно, а не параллельно. Если какой-либо из заданных узлов неактивен, операция завершения работы на этом узле прерывается. Как и при запуске служб, для остановки служб кластера следует всегда использовать SMIT. Экран SMIT остановки кластера представлен на рис. 7.2.
Чтобы остановить службы кластера:
- Введите быстрый путь smit cl_admin.
- В SMIT выберите Manage HACMP Services (Управление службами HACMP) > Start Cluster Services (Запустить службы кластера) и нажмите Enter.
- Введите следующие значения полей:
- Stop now, on system restart or both (Остановить сейчас, при перезапуске системы или в обоих случаях). Определяет, когда следует останавливать службы кластера: в данный момент (now), при перезагрузке операционной системы (restart) или в обоих случаях (both). При выборе значений restart или both в файле /etc/inittab происходит удаление записи, запускающей службы кластера. Службы кластера больше не будут автоматически запускаться после перезагрузки.
- BROADCAST cluster shutdown? (Отправлять широковещательное сообщение при завершении работы кластера?). Указывает, требуется ли отправлять широковещательное сообщение пользователям перед остановкой служб кластера. Если задано значение true, выполняется широковещательная рассылка сообщения на все узлы кластера.
- Shutdown mode (Режим завершения работы). Указывает тип остановки:
- graceful (постепенная). Завершение работы после запуска скрипта /usr/es/ sbin/cluster/events/node_down_complete на узле для освобождения ресурсов кластера. Другие узлы кластера не выполняют перехват ресурсов остановленного узла.
- graceful with takeover (постепенная с передачей ресурсов на резервные узлы). Завершение работы после запуска скрипта /usr/es/sbin/cluster/ events/node_down_complete для освобождения ресурсов кластера. Другие узлы выполняют перехват ресурсов остановленного узла.
- forced (принудительная). Немедленное завершение работы. Узел сохраняет управление всеми своими ресурсами. Эту опцию можно использовать для отключения узла при выполнении обслуживания или внесении изменений в конфигурацию кластера, в частности при добавлении сетевой карты.

Однако после остановки служб кластера больше не обеспечивается высокая доступность приложений. При возникновении отказа восстановление выполняться не будет.
Наблюдения
В прежних версиях HACMP после остановки диспетчера кластера (Cluster Manager) больше не обеспечивалась высокая доступность приложений. При возникновении отказа восстановление приложений не обеспечивалось. В HACMP 5.3 диспетчер кластера (Cluster Manager) продолжает работать даже после остановки служб кластера. Скрипты rc.cluster и clstop выдают диспетчеру кластера команды IPC™. Диспетчер кластера выполняет скрипт обработки событий для запуска стека RSCT (rc.cluster).
Кроме того, в HACMP 5.3 node_down_complete вызывает процедуру остановки стека RSCT. Диспетчер кластера реагирует на команды stopsrc немедленной остановкой без запуска события node_down, что необходимо перед установкой, обслуживанием или заменой демона clstrmgr или зависимых библиотек (например, libclstr.a).
Управление группами ресурсов и приложениями
В этом разделе обсуждаются следующие темы:
- перевод группы ресурсов в отключенное состояние;
- перевод группы ресурсов в подключенное состояние;
- перемещение группы ресурсов;
- приостановка/возобновление мониторинга приложения.
Понимание этих вопросов так же важно, как и понимание остановки и запуска служб кластера, так как эти операции часто применяются в периоды обслуживания.
В следующих разделах мы начинаем с предположения, что службы кластера выполняются, группы ресурсов подключены, приложения работают и кластер стабилен. Если кластер находится в нестабильном состоянии, то операции с группами ресурсов невозможны.
Все три обсуждаемые нами операции с группами ресурсов могут быть выполнены с использованием команды clRGmove. Однако в наших примерах мы будем применять C-SPOC. Все эти операции имеют похожие экраны SMIT и списки для выбора. Чтобы сократить объем главы, мы представим только по одному экрану SMIT в каждом из последующих разделов.
При выполнении любой из операций с группами ресурсов важно понимать действие параметра priority override location (расположение, отменяющее приоритет). Это настолько важно, что мы посвятили этому целый раздел – "Расположение, отменяющее приоритет".
Перевод группы ресурсов в отключенное состояние через SMIT
Чтобы перевести группу ресурсов в отключенное состояние:
- Введите быстрый путь smit cl_admin.
- В SMIT выберите HACMP Resource Group and Application Management (Управление группами ресурсов и приложениями HACMP) > Bring a Resource Group Offline (Перевести группу ресурсов в отключенное состояние). Выводится список, как показано на рис. 7.3. Он отображает только группы ресурсов, находящиеся в подключенном состоянии или в состоянии ERROR (Ошибка) на всех узлах в кластере.
- Выберите требуемую группу ресурсов из списка и нажмите Enter. После выбора группы ресурсов появляется другой список, Select a Destination Node (Выбор целевого узла). Список будет содержать только активные на данный момент узлы кластера, участвующие в ранее выбранной группе ресурсов.
- Выберите целевой узел из списка и нажмите Enter.
- Появляется последнее меню SMIT с информацией, выбранной в предыдущих списках. Кроме того, необходимо задать значение еще одного дополнительного поля, Persist across Cluster Reboot?. Вообще говоря, следует оставить в этом поле значение по умолчанию или false. Это поле непосредственно связано с параметром POL; дополнительные сведения см. в разделе "Расположение, отменяющее приоритет".
- Просмотрите ранее заданные записи, после чего нажмите Enter, чтобы начать обработку отключаемой группы ресурсов.
После завершения обработки группа ресурсов будет отключена, тогда как службы кластера на узле останутся активными.
Перевод группы ресурсов в подключенное состояние через SMIT
Чтобы перевести группу ресурсов в подключенное состояние:
- Введите быстрый путь smit cl_admin.
- В SMIT выберите HACMP Resource Group and Application Management (Управление группами ресурсов и приложениями HACMP) > Bring a Resource Group Online (Перевести группу ресурсов в подключенное состояние). Выводится список. Он отображает только группы ресурсов, находящиеся в подключенном состоянии или в состоянии ERROR (Ошибка) на всех узлах в кластере.
- Выберите требуемую группу ресурсов из списка и нажмите Enter. После выбора группы ресурсов появляется другой список, Select a Destination Node (Выбор целевого узла). Список будет содержать только активные на данный момент узлы кластера, участвующие в ранее выбранной группе ресурсов.
- Выберите целевой узел из списка, как показано на рис. 7.4. После выбора этого узла он становится расположением, отменяющим приоритет (priority override location) для данной группы ресурсов.
- Появляется последнее меню SMIT с информацией, выбранной в предыдущих списках. Кроме того, необходимо задать значение еще одного дополнительного поля, Persist across Cluster Reboot?. Вообще говоря, следует оставить в этом поле значение по умолчанию или false. Это поле непосредственно связано с параметром POL ; дополнительные сведения см. в разделе "Расположение, отменяющее приоритет".
- Просмотрите ранее заданные записи, после чего нажмите Enter, чтобы начать обработку подключаемой группы ресурсов.

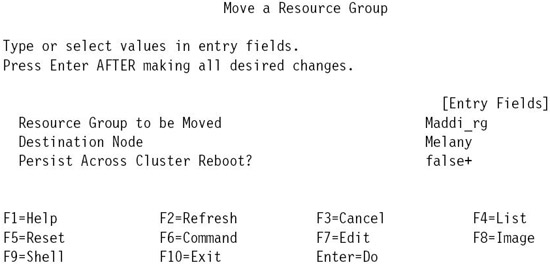
После успешного завершения HACMP выводит сообщение о состоянии, расположении и типе расположения (постоянное или нет) группы ресурсов, которая была успешно остановлена на заданном узле.