Лекция 5: Миграция кластера на HACMP V5.3
Сценарий 3: AIX 5.2 и HA 5.2
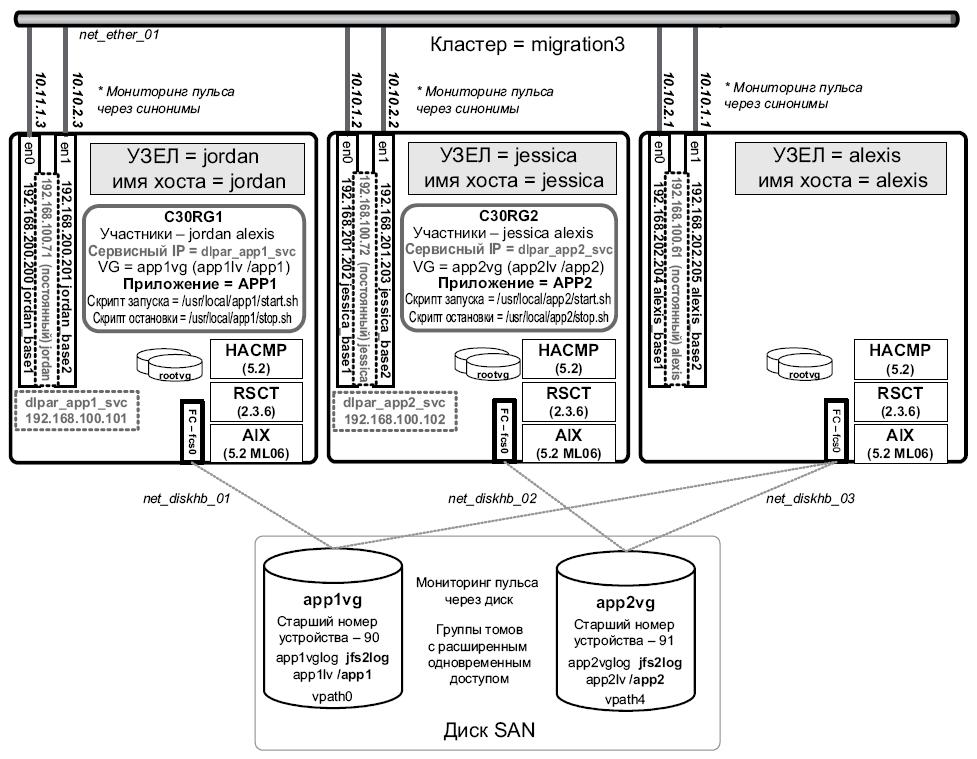
Третий тестовый сценарий представлял собой миграцию кластера AIX 5.2 / HA 5.2 с двумя активными узлами и одним дежурным резервным узлом на AIX 5.3 / HA 5.3. В своей конфигурации мы использовали три одинаковых LPAR p690 (7040-681). На рис. 5.4 представлена схема используемой конфигурации.
Топология была настроена на использование IP-синонимов вместе с мониторингом пульса через синонимы. Это было сделано, чтобы убедиться в том, что обновление сохранит смещение сети 10.10.1.1 и соответствующие синонимы и что впоследствии проблем в работе кластера не возникнет.
Мы сконфигурировали базовые адреса для каждого узла в соответствующей подсети и поместили все сервисные и постоянные IP-адреса в другой диапазон подсети. Такая конфигурация IP используется для имитации университетской среды, где компьютеры могут быть разделены определенным расстоянием и могут использовать различные подсети, а также для того, чтобы убедиться в том, что для базовых адресов не выполняется мониторинг с использованием трафика пульса HACMP.
Хранилище содержало ESS LUN (2105-800) с подключением к коммутатору, а также скрипт подключения хоста и драйвер SDD для балансировки нагрузки и многопутевой конфигурации (multipathing). Мы использовали группы томов с расширенным одновременным доступом для создания трех сетей пульса через диски, отличных от IP.
Циклическая миграция: сценарий 3
Для этого сценария мы использовали кластер в среде DLPAR, чтобы убедиться в том, что все работает после обновления. Мы выполнили следующие предварительные действия:
- Сохранение снимка с рабочего кластера (со всеми активными узлами).
- Создание резервной копии (mksysb).
- Создание alt_disk_install как средства возврата к прежней конфигурации. Это было сделано с целью ускорения повторного тестирования.
Сценарий миграции
Сначала мы решили выполнить обновление дежурного узла alexis, чтобы максимально сократить перерыв в работе узлов, содержащих группы ресурсов. Для этого мы выполнили следующие действия:
- Остановка HACMP на узле alexis (постепенная остановка с передачей ресурсов на резервный узел – graceful with takeover).Внимание. Не сохраняйте снимок в каталог /tmp, так как при миграции AIX содержимое каталога /tmp удаляется. Сохраните снимок в другой каталог или на другой сервер. Не забудьте также сохранить скрипты приложения в надежный каталог.
- Инициация установки базового кода AIX 5.3/ RSCT с использованием NIM вместе с последними исправлениями. Удаление и замена SDD текущим драйвером AIX 5.3:
- Выполнение smit update_all для загрузки наборов файлов HACMP 5.3.
- Перезагрузка узла alexis:
- Верификация инсталляции AIX ( lppchk -l / -c / -v, instfix, oslevel, errpt );
- lslpp -l | grep cluster => Нет следов версии 5.2 (проверка отсутствия наборов файлов);
- odmget HACMPcluster => все еще отображалась версия 7.
- Реинтеграция узла alexis в кластер путем запуска служб кластера.Внимание. Выполнение синхронизации для кластера в гибридном состоянии нарушит миграцию.
- Остановка HACMP на узле jordan (постепенная остановка с передачей ресурсов на резервный узел – graceful with takeover).
- Повтор действий пп. 2–5 на узле jordan.
- Остановка HACMP на узле jessica (постепенная остановка с передачей ресурсов на резервный узел – graceful with takeover).
- Повтор действий пп. 2–5 на узле jessica.
Результаты циклической миграции: сценарий 3
Как и в двух предыдущих сценариях, мы не столкнулись с какими-либо проблемами при циклической миграции HACMP. После интеграции последнего узла в кластер было выполнено преобразование разделов ODM-классов, и теперь для всех узлов выводилось cluster_version = 8, как и ожидалось. Номера версий HACMP см. в табл. 5.2.
При первоначальной настройке топологии кластера мы выполнили конфигурирование базового, постоянного и сервисного IP-адресов в одной подсети. Хотя такая топология и допустима, она создает некоторые проблемы в среде NIM (Network Install Manager), так как NIM неспособен обрабатывать постоянные синонимы (что вызывает отказы при подключении NFS).
Поэтому мы советуем быть осторожными при внедрении HACMP в среде NIM; это также относится к среде CSM (Cluster Systems Management), которая использует NIM для установки и обновления программного обеспечения на управляемых узлах. ( пример 5.1 представляет конфигурацию в файле hosts (которая создает проблемы с NIM):
_:># more /etc/hosts 192.168.100.200 jordan_base1 192.168.100.201 jordan_base2 192.168.100.202 jessica_base1 192.168.100.203 jessica_base2 192.168.100.204 alexis_base1 192.168.100.205 alexis_base2 192.168.100.71 p690_1_lpar1 #persistent IP jordan 192.168.100.72 p690_1_lpar2 #persistent IP jessica 192.168.100.61 p690_2_lpar1 #persistent IP alexis 192.168.100.101 dlpar_app1_svc 192.168.100.102 dlpar_app1_svcПример 5.1. Разрешение имен в нашей среде
Миграция с использованием снимков: сценарий 3
В том же трехузловом кластере мы проверили работу метода преобразования снимков. Мы использовали образы установки на резервных дисках для возврата к прежней среде, после чего перезапустили службы кластера на обоих узлах, на которых выполнялся HACMP 5.2. Тестирование содержало следующие действия:
- Остановка HACMP на всех узлах: alexis jordan jessica.
- Выполнение команды smit remove и деинсталляция всех наборов файлов cluster.* со всех узлов.
- Миграция кода AIX/RSCT с использованием NIM.
- Установка пакетов HACMP с текущими уровнями PTF на всех узлах.
- Перезагрузка всех узлов кластера.
- Копирование файла snapshot.odm, предварительно сохраненного в процессе циклической миграции и имеющего расположение /usr/es/sbin/cluster/utilities/ snapshot.odm
- Выполнение следующей команды для преобразования снимка: #/usr/es/sbin/ cluster/conversion/clconvert_snapshot -v 5.2 -s snapshot.odm.
- Применение снимка: smit hacmp > Extended Configuration (Расширенное конфигурирование) > Snapshot Configuration (Конфигурирование снимка) > Apply a Cluster Snapshot (Применение снимка кластера) > выбор снимка и нажатие Enter.
- Запуск служб кластера поочередно на каждом узле.
Результаты миграции с использованием снимков: сценарий 3
В целом миграция с использованием снимка также прошла успешно. Преобразование файла снимка заняло около 1 мин, и его применение на всех трех узлах также произошло очень быстро. Затем мы убедились в корректности преобразования разделов ODM.
Мы считаем, что, если ваша среда допускает перерыв в обслуживании в масштабе кластера, можно использовать этот быстрый и надежный метод, позволяющий полностью избежать функционирования узлов в смешанном режиме. Использование снимка для возврата конфигурации HACMP после обновления всех узлов позволяет избежать потенциальных проблем, которые могут возникнуть в процессе циклической миграции. Дополнительные сведения о потенциальных проблемах см. в разделе "Аспекты", в этой главе.