Составляющие высокой доступности
Коммуникационные устройства HACMP
Топология HACMP также включает отличные от IP сети (non-IP networks) типа "точка-точка", такие, как последовательная сеть RS232, target mode SCSI, target mode SSA, и подключения мониторинга пульса через диски (disk heartbeat). На обоих концах сети "точка-точка" находятся устройства AIX (определенные в каталоге /dev), такие, как /dev/tty1, /dev/tmssa1, /dev/tmscsi1 и /dev/hdisk1.
Например, при мониторинге пульса через диски имя дискового устройства (например, /dev/hdisk2) используется в качестве устройства, сконфигурированного в HACMP на каждом конце подключения.
Эти отличные от IP сети представляют собой соединения "точка-точка" между двумя узлами кластера и используются RSCT для управления трафиком сообщений и мониторинга пульса. Эти сети обеспечивают дополнительный уровень защиты кластера HACMP на случай отказа IP-сетей или подсистемы TCP/IP на узлах.
Коммуникационные адаптеры и связи включают адаптер X.25, используемый для обеспечения коммуникационной связи с высокой доступностью. В качестве ресурсов HACMP может быть определено следующее:
- SNA, сконфигурированный через адаптеры локальной сети;
- SNA, сконфигурированный через адаптеры X.25;
- собственные связи X.25.
HACMP осуществляет управление этими связями в составе групп ресурсов, обеспечивая, таким образом, коммуникационные связи высокой доступности. В случае отказа физического сетевого интерфейса, отказа связи X.25 или отказа узла коммуникационная связь высокой доступности переносится на другой доступный адаптер на том же узле или на резервный узел (вместе со всеми ресурсами в той же группе ресурсов).
Физические и логические сети
Физическая сеть соединяет два или больше физических сетевых устройства. Существует множество типов физических сетей, и в HACMP они разделяются на IP-сети и сети, отличные от IP:
- сети TCP/IP, такие, как Ethernet и Token Ring;
- сети устройств, такие, как RS-232, target mode SCSI (tmscsi), target mode SSA (tmssa), или сети мониторинга пульса через диски (disk heartbeat).
HACMP, подобно AIX, поддерживает понятие логических сетей. Два или более сетевых интерфейса в одной физической сети могут быть сгруппированы, представляя логическую сеть. Эти логические сети имеют уникальное имя (например, net_ether_ 01, если оно присваивалось HACMP) и могут включать одну или несколько подсетей. Логическая сеть может быть представлена как группа интерфейсов, используемых HACMP для содержания одной или нескольких сервисных IP-меток/адресов. RSCT образует собственные сети, соединяющие интерфейсы в одной подсети, и при необходимости может обеспечивать временную маршрутизацию между подсетями.
Определения сетей можно добавить через экраны SMIT HACMP, однако мы рекомендуем выполнить процесс обнаружения (discovery) перед конфигурированием сетей. Выполнение процесса обнаружения заполнит ниспадающие списки, которые могут использоваться в процессе конфигурирования. В процессе обнаружения информация берется из файла /etc/hosts, определенных интерфейсов, определенных адаптеров, устройств target mode и существующих дисков с расширенным режимом одновременного доступа (enhanced concurrent) и создаются следующие файлы:
- clip_config. Содержит сведения об обнаруженных интерфейсах, используемых в SMIT-списках <F4>.
- clvg_config. Содержит сведения о каждом физическом томе (PVID, имя VG, состояние, старший номер устройства и т. д.), а также список свободных старших номеров устройств (major numbers).
В процессе обнаружения также могут быть выявлены некоторые несогласованности в сети вашего сайта.
Глобальная сеть
Глобальная сеть представляет собрание нескольких сетей HACMP одного типа, например Ethernet. Как обсуждалось выше, логические сети HACMP могут состоять из любого сочетания физически различающихся сетей и/или различных подсетей.
Для HACMP важно знать, где именно в сети произошел отказ и не произошел ли отказ глобальной сети, так как при отказе глобальной сети перемещение группы ресурсов на другой узел ничего не даст.
Мониторинг пульса RSCT и HACMP
Диспетчер кластера HACMP cluster manager использует несколько источников для получения информации о возможных отказах:
- RSCT осуществляет мониторинг состояния сетевых интерфейсов и устройств;
- AIX LVM осуществляет мониторинг состояния дисков, логических томов и групп томов.
- мониторы приложений (HACMP Application monitors) осуществляют мониторинг состояния приложений.
HACMP, подобно многим другим типам кластеров, использует пакеты пульса (keep alive, KA) для мониторинга доступности сетевых интерфейсов, коммуникационных устройств и IP-меток (сервисных, несервисных и постоянных). HACMP может использовать как IP-сети, так и сети, отличные от IP, для обмена пакетами или сообщениями пульса между узлами. Посредством мониторинга пульса HACMP получает информацию о состоянии интерфейсов, устройств и адаптеров и, таким образом, о доступности узлов кластера.
Начиная с HACMP V5.1 мониторинг пульса основан исключительно на службах топологии RSCT. До этого HACMP Classic (до HACMP V4.5) использовал собственный код для модулей сетевых интерфейсов (Network Interface Modules, NIM). Демоны RSCT для передачи пакетов пульса используют протокол UDP. При запуске HACMP на узле HACMP передает сетевую топологию, сохраненную в конфигурации HACMP ODM в RSCT. RSCT использует эту информацию для построения своих групп связи ("колец пульса", heartbeat rings) и, в свою очередь, передает в HACMP уведомления об отказах.
Технология RSCT была разработана в начале 1990-х гг. для систем IBM SP и затем стала инфраструктурой для HACMP/ES (Enhanced Scalability).
RSCT содержит следующие компоненты:
- Службы мониторинга и управления ресурсами (Resource monitoring and control, RMC). HACMP 5.1 и более ранние версии использовали подсистему управления событиями. RMC представляет собой распределенную подсистему, обеспечивающую набор служб высокой доступности. RMC создает события, сопоставляя текущее состояние системных ресурсов с информацией о требуемом клиентами состоянии ресурсов. После этого клиенты могут использовать уведомления о событиях для вызова действий восстановления. Тем не менее диспетчер событий (event manager) все еще используется для поддержки Oracle RAC.
- Диспетчеры ресурсов (Resource managers). Представляют собой демоны, которые в действительности являются частью RMC и представляют административную задачу или системную функцию. HACMP использует RMC для динамической установки приоритетов узлов, мониторинга приложений и пользовательских событий. Например, монитор ресурсов, сообщающий показатель бездействия процессора, используется при перемещении ресурсов на узел с наиболее высоким показателем бездействия процессора.
- Службы групп (Group services). Обеспечивают системное средство мониторинга и согласования изменений в состоянии приложения, выполняющегося на наборе узлов, с высокой доступностью.
- Службы топологии (Topology services). Обрабатывают мониторинг пульса через несколько сетей в кластере. Имеют сведения о конфигурации сети и сообщают информацию о состоянии сетевых интерфейсов и адаптеров, а также самих узлов.
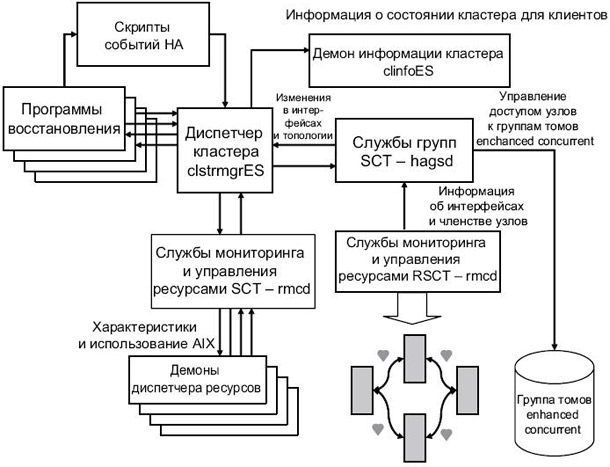
На рис. 2.3 показаны некоторые из демонов RSCT, а также их взаимодействие с другими демонами HACMP (в HACMP V5.3).
Мониторинг пульса осуществляется путем обмена сообщениями (пакетами пульса) между узлами через каждый интерфейс и коммуникационное устройство, определенные в кластере (топологии). Каждый узел отправляет пакет пульса и ожидает получить пакет через каждую сеть с интервалом, определенным чувствительностью сети. Так как каждый узел в каждой кольцевой сети связан только с двумя соседними узлами, узел будет получать только один пакет с определенного узла каждые два интервала пульса. Это важно при вычислении того, сколько времени занимает определение отказа.
RSCT осуществляет мониторинг только для базовых адресов интерфейсов (если только не выбран мониторинг пульса через IP-синонимы) и не осуществляет мониторинг сервисных IP-меток (при использовании перехвата IP-адреса IPAT посредством синонимов) или постоянных IP-меток.
HACMP отвечает за отслеживание синонимов меток (сервисных IP-меток при IPAT посредством синонимов и постоянных синонимов меток) как по состоянию базового интерфейса и состоянию связи, так и посредством мониторинга счетчика полученных пакетов (подобно выходным данным команды netstat ). HACMP V5.2 и более поздние версии пытаются восстановить работоспособность интерфейса, если он находится в состоянии "down" или "detached" (по выходным данным команды lsattr ), но при этом физическое соединение остается активным.
Примечание. Таким образом, если вы решите командой ifconfig отключить адаптер для тестирования, HACMP вновь его подключит без какой-либо обработки событий HACMP.
RSCT определяет, что на одном из интерфейсов или адаптеров узла произошел отказ, если от него не приходят пакеты пульса, однако продолжает приходить информация пульса через другие интерфейсы и адаптеры узла. В этом случае HACMP сохраняет связь с узлом, переводя сервисные (и постоянные) IP-метки на другой сетевой интерфейс той же сети на том же узле.
Если все интерфейсы этой сети HACMP на этом узле становятся недоступными, HACMP переносит все группы ресурсов, содержащие IP-метки, на другой узел с доступными интерфейсами в этой же сети. Если RSCT не получает пакеты пульса через все интерфейсы или адаптеры узла, то считается, что на этом узле произошел отказ и HACMP попытается привести затронутые этим сбоем группы ресурсов в рабочее состояние на другом узле.
Коммуникации RSCT
HACMP отвечает за запуск RSCT (служб топологии и групп) на узлах, входящих в кластер. RSCT организует свои сети и межузловые связи в зависимости от типа сети следующим образом:
- IP-сети. Кольцо (группа связи RSCT) создается для каждой логической подсети для интерфейсов, определенных в HACMP, в порядке IP-адресов. Каждый узел связан с двумя соседними узлами – узлами с большим и меньшим по очередности IP-адресом. Каждое IP-кольцо (также называемое группой связи RSCT – communication group) изменяется при добавлении каждого нового узла в кластер.
- Последовательные сети. RSCT также создает группу связи для каждой пары коммуникационных устройств или последовательной сети HACMP. Затем RSCT строит логическую сеть между этими группами связи для передачи информации между узлами с использованием коммуникаций, отличных от IP.
Учитывая топологию кластера, представленную на рис. 2.2, RSCT создает три сети пульса – по одной для каждой IP-подсети, и одну для кольца устройств, отличного от IP, как показано на рис. 2.4.
В более ранних версиях HACMP количество последовательных (отличных от IP) коммуникационных устройств одного типа на узел ограничивалось двумя, так что для трех или более узлов была возможна только кольцевая конфигурация. Более новые версии HACMP (5.1 и выше) поддерживают конфигурацию с сетями, отличными от IP, с подключением между всеми узлами (каждого с каждым), если на каждом узле достаточно устройств.
RSCT использует определенные узлы для управления связью между группами связи. Узлы, выполняющие эти задачи, выбираются динамически и могут изменяться при каждом входе или выходе узла из кластера.
- Лидер группы (Group Leader). Узел с наивысшим IP-адресом в первой созданной группе связи, называется лидером группы. Этот узел хранит информацию о других узлах в кластере и о конфигурации сети.
- Резервный лидер группы (Group Leader Backup). Узел со вторым по величине IP-адресом в первой группе связи называется резервным лидером группы. Этот узел содержит резервную копию данных топологии лидера группы и принимает на себя роль лидера группы в случае выхода лидера группы из кластера.
- Распорядитель (Mayor). Узел с третьим по величине IP-адресом в первой группе связи (если третий узел недоступен, используется резервный лидер группы). Этот узел отвечает за информирование всех узлов о любых изменениях в топологии кластера.

На рис. 2.5 показан пример двух групп связи, сформированных для двух IP-подсетей, и RSCT-роли узлов.
Как уже обсуждалось, получение информации о состоянии топологии кластера в HACMP в значительной мере зависит от RSCT и от данных, получаемых в пакетах пульса. Тем не менее должна быть полная уверенность в том, что на узле действительно произошел отказ, прежде чем предпринимать какие-либо действия. Если
в сети отсутствует избыточность, HACMP может прийти к неправильным выводам о состоянии узлов. Например, если RSCT использует только сеть TCP/IP, отказ сетевого компонента (коммутатора, маршрутизатора, концентратора) или подсистемы TCP/IP будет некорректно интерпретироваться как отказ одного или нескольких узлов. На рис. 2.6 представлен пример кластера, получающего данные пульса исключительно через TCP/IP.
В этом примере узлы 1 и 2 будут считать, что на узлах 3 и 4 произошел отказ, и будут пытаться восстановить работоспособность их ресурсов. Подобным же образом

узлы 3 и 4 будут считать, что отказ произошел на узлах 1 и 2. Такая ситуация, называемая разделенным кластером (partitioned cluster), может привести к повреждению данных, так как каждая группа узлов будет пытаться одновременно осуществлять доступ к данным и запускать приложения.
Чтобы HACMP мог отличить действительный отказ узла от отказа подсистемы TCP/IP, требуется использовать другой путь связи между узлами – такой, который бы не был основан на TCP/IP. Для этого HACMP использует последовательные сети, отличные от IP (сети "точка-точка" или сети устройств). RSCT осуществляет мониторинг как для сетей устройств, так и для сетей TCP/IP, поэтому HACMP может использовать эту информацию, чтобы отличать отказ узла от отказа IP-сети/подсистемы. Рекомендуется, чтобы каждый кластер имел как минимум одну сеть, отличную от IP, для каждого узла в кластере, чтобы не допустить разделения кластера. Если бы в примере, представленном на рис. 2.6, использовались последовательные сети, HACMP мог бы правильно распознать отказ и не возникла бы опасность потери или повреждения данных ( рис. 2.7).
На рис. 2.7 представлена рекомендованная конфигурация кластера из двух узлов.
Другая ситуация, при которой RSCT и HACMP не смогут точно определить состояние интерфейса, заключается в возникновении сети с одним интерфейсом. Если
по причине какого-либо отказа интерфейс обнаружит, что он является единственным интерфейсом в сети, это означает, что не существует другого адреса, с которым интерфейс мог бы обмениваться пакетами пульса. В случае возникновения сети с одним интерфейсом RSCT может определить, работает ли интерфейс, путем мониторинга счетчика полученных пакетов следующим образом:
- Путем широковещательного ping-опроса.
- Путем отправки пакетов ICMP ECHO (ping) на все адреса, указанные в файле netmon.cf.
- Путем создания временного маршрута от одной из групп связи к другой с последующим тестированием связи.
Файл /usr/es/sbin/cluster/etc/netmon.cf
Должен
- содержать список IP-адресов или меток, преобразуемых в адреса, по одной в строке и
- существовать (и быть одинаковым) на всех узлах, входящих в кластер.
Подсети и RSCT
AIX 5L поддерживает использование нескольких маршрутов к одному пункту назначения в таблице маршрутизации ядра. Это означает, что, если несколько совпадающих маршрутов имеют одни и те же критерии, маршрутизация может осуществляться поочередно с использованием каждого из маршрутов подсетей. Это также называется чередованием маршрутов.
Таким образом, действие нескольких интерфейсов в одной подсети на одном узле состоит в том, что пакеты будут отправляться через каждый из интерфейсов поочередно. Это означает, что другие узлы, а значит и RSCT, не смогут определить, с какого интерфейса пришел пакет пульса. Чтобы избежать ситуации, при которой RSCT, а значит и HACMP, не смогут точно определить состояние интерфейсов, существуют строгие правила конфигурирования подсетей. Эти правила зависят от конфигурации сети и обсуждаются в разделах, посвященных перехвату IP-адреса.
Примечание. В AIX 5.3 реализована новая опция, mpr_policy, позволяющая настроить TCP/IP таким образом, чтобы пакеты для определенного пункта назначения поступали только с одного адаптера. Чтобы настроить TCP/IP на применение адаптера в зависимости от пункта назначения пакета, следует использовать значение mpr_policy = 5. Мы рекомендуем устанавливать это значение в том случае, если какие-либо из приложений восприимчивы к тому, с какого адаптера приходит пакет, например для NFS.