Повышение производительности запроса
В предыдущей лекции вы научились извлекать сводную информацию о данных, хранящихся в вашей базе данных. SQL Server может возвращать результаты, в том числе, сводную информацию, быстро и эффективно, если данные правильно хранятся в базе данных. В этой лекции объясняются различные способы хранения и извлечения данных в SQL Server, а также рассказывается о том, какие факторы следует учитывать при разработке базы данных, чтобы добиться наиболее эффективной производительности от SQL Server.
Планы запросов
Когда сервер SQL Server выполняет запрос, сначала требуется определить наилучший способ выполнения. Для этого нужно рассчитать, как и в каком порядке обращаться к данным и соединять их, как и когда выполнять вычисления и агрегации и т. д. За это отвечает подсистема, которая называется Query Optimizer (Оптимизатор запроса). Оптимизатор запроса использует статистические данные о распределении данных, метаданные, относящиеся к объектам в базе данных, информацию индекса и другие факторы для вычисления нескольких возможных планов выполнения запроса. Для каждого из этих планов Оптимизатор запроса предполагает его стоимость на основе статистики по этим данным и выбирает план с минимальными затратами ресурсов на выполнение. Конечно, SQL Server не вычисляет всех возможных планов для каждого запроса, поскольку для некоторых запросов сами эти вычисления могут отнять больше времени, чем выполнение наименее эффективного из всех планов. Следовательно, SQL Server использует сложные алгоритмы, чтобы найти план выполнения с разумной стоимостью, близкой к минимально возможной. После того, как план выполнения сгенерирован, он хранится в буферном кэше (на что SQL Server выделяет большую часть своей виртуальной памяти). Затем план выполняется тем способом, который Оптимизатор запроса сообщает ядру базы данных (компоненту database engine).
 Примечание. Планы выполнения в буферном кэше могут быть повторно использованы при выполнении такого же или аналогичного запроса. Следовательно, планы выполнения хранятся в кэше максимально возможное время. Дополнительную информацию о кэшировании планов выполнения см. в официальном документе под названием: "Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005" (Проблемы компиляции и рекомпиляции пакетов, а также кэширования планов в SQL Server 2005) на странице http://www.microsoft.com/ technet/prodtechnol/sql/2005/recomp.mspx.
Примечание. Планы выполнения в буферном кэше могут быть повторно использованы при выполнении такого же или аналогичного запроса. Следовательно, планы выполнения хранятся в кэше максимально возможное время. Дополнительную информацию о кэшировании планов выполнения см. в официальном документе под названием: "Batch Compilation, Recompilation, and Plan Caching Issues in SQL Server 2005" (Проблемы компиляции и рекомпиляции пакетов, а также кэширования планов в SQL Server 2005) на странице http://www.microsoft.com/ technet/prodtechnol/sql/2005/recomp.mspx.Сможет ли Query Optimizer (Оптимизатор запросов) сгенерировать эффективный план для конкретного запроса, зависит от следующих аспектов:
- Индексы. Подобно оглавлению в книге, индекс базы данных позволяет быстро найти определенные строки в таблице. В таблице может быть не один индекс. Благодаря наличию в таблице индексов, Оптимизатор запросов SQL Server может оптимизировать доступ к данным, выбрав для использования подходящий индекс. Если индексы отсутствуют, у Оптимизатора запросов остается только один вариант, который заключается в сканировании всех данных, имеющихся в таблице, в поиске нужных строк. Далее в этой лекции приводится информация о том, как работают индексы и как их разрабатывать и проектировать.
- Статистика распределения данных:SQL Server хранит статистику о распределении данных. Если эта статистика отсутствует или устарела, Оптимизатор запросов не сможет вычислить эффективный план выполнения запроса. В большинстве случаев, статистические данные генерируются и обновляются автоматически. Далее в этой лекции рассказывается о том, как генерируются статистические данные и как можно управлять статистикой.
Как видите, генерирование плана выполнения запросов - это функция, немаловажная для производительности SQL Server, поскольку эффективность плана выполнения запроса определяет, будет ли время его выполнения измеряться в миллисекундах, секундах или даже минутах. Планы выполнения запросов, которые показали низкую скорость выполнения, можно проанализировать, чтобы определить, имеется ли индекс, устарели ли данные статистики или просто SQL Server выбрал не самый эффективный план (такое случается не очень часто).
Примечание. Конечно, возможно, что неэффективно выполненный запрос выполнялся в соответствии с хорошим планом. В этих случаях дело не в оптимизации запроса. Скорее всего, проблема кроется совсем в другом, например, в проекте запроса, конфликте доступа к данным, операций ввода/вывода, памяти, использования ЦПУ, сетевых ресурсов и т. п. Чтобы получить дополнительную информацию по этим проблемам, рекомендуем ознакомиться с официальным документом "Troubleshooting Performance Problems in SQL Server 2005" (Поиск и решение проблем с производительностью в SQL Server 2005), который доступен по следующей ссылке: http://www.microsoft.com/ technet/prodtechnol/sql/2005/tsprfprb.mspx.Знакомимся с планами выполнения запросов
- В меню Start (Пуск) выберите All Programs,. Microsoft SQL Server 2005, SQL Server Management Studio (Все программы, Microsoft SQL Server 2005, Среда SQL Server Management Studio). Нажмите кнопку New Query (Создать запрос), чтобы открыть окно нового запроса, и измените контекст выполнения на базу данных Adventure Works, выбрав ее из раскрывающегося списка Available Databases (Доступные базы данных).
- Выполните следующую инструкцию SELECT. Код этого примера имеется в файлах примеров под именем Viewing Query Plans.sql.
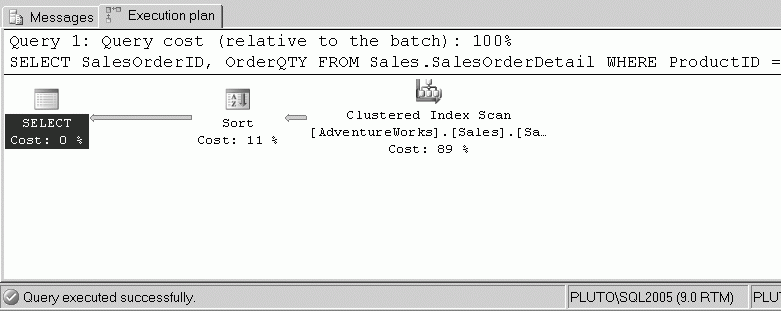
SELECT SalesOrderID, OrderQTY FROM Sales.SalesOrderDetail WHERE ProductID = 712 ORDER BY OrderQTY DESC
- Чтобы вывести на экран план выполнения для этого запроса, нажмите комбинацию клавиш (Ctrl+L) или выберите из меню Query (Запрос) команду Display Estimated Execution Plan (Показать предполагаемый план выполнения). План выполнения показан на следующем рисунке.
При генерировании предполагаемого плана запроса запрос на самом деле не выполняется. Он только оптимизируется Оптимизатором запроса. Эта особенность Оптимизатора запросов является преимуществом, когда приходится иметь дело с запросами, которые имеют продолжительные рабочие циклы, ведь для того, чтобы увидеть план выполнения запроса, нет необходимости выполнять сам запрос. Графическое представление плана выполнения запроса читается справа налево и сверху вниз. Каждый значок в плане представляет один оператор, а данные, изменяемые между этими операторами, обозначены стрелками. Толщина стрелок соответствует объему данных, которые передаются между операторами. Мы не будем углубляться в подробности и объяснять значение каждого оператора; расскажем только о тех из них, которые показаны в данном плане выполнения запроса.
- SQL Server обращается к данным при помощи операции Clustered Index Scan (Просмотр кластеризованного индекса). Это сканирование представляет собой реальную операцию доступа к данным и подробно рассматривается далее.
- Данные переходят к оператору Sort (Сортировка), который сортирует данные на основе предложения ORDER BY.
- Данные пересылаются клиенту.
Мы рассмотрим самые важные операторы, которые использует SQL Server, когда будем изучать индексы и соединения. Полный список операторов можно найти в Электронной документации SQL Server 2005, тема "Пиктограммы графического представления плана выполнения".
Стоимость в процентах под пиктограммой каждого оператора показывает процент от общей стоимости запроса, представленного на графической схеме. Это число поможет вам понять, какая операция использует при выполнении больше всего ресурсов. В нашем случае самой дорогостоящей операцией является Clustered Index Scan (Просмотр кластеризованного индекса), которая составляет 89% общей стоимости запроса.
- Задержите указатель мыши над оператором Clustered Index Scan (Просмотр кластеризованного индекса). Откроется окно с текстом на желтом фоне, показанное на следующем рисунке.
В этом окне отображается подробная информация об операции. До сих пор мы знали только то, что SQL Server извлекает данные при помощи операции сканирования. Но в этом окне видно, что он выполняет операцию Clustered Index Scan (Просмотр кластеризованного индекса) (которая подробно рассматривается ниже) на кластеризованном индексе таблицы Sales.SalesOrderDetail, а также поиск ProductID 712. Эта информация находится в секции Predicates (Предикаты). Кроме того, показаны предполагаемая стоимость и предполагаемое количество строк, а также размер строки. В то время, как количество строк оценивается на основе статистики, которую SQL Server хранит для этой таблицы, значения стоимости вычисляются на основе статистики и значений эталонной системы. Следовательно, значения стоимости не следует использовать для того, чтобы рассчитать, сколько времени запрос будет выполняться на компьютере. Эти цифры могут использоваться только для выявления более дешевой или более дорогостоящей операции.
- Эту информацию об операторах можно увидеть также в окне Properties (Свойства) в SQL Server Management Studio. Чтобы открыть окно Properties (Свойства), щелкните правой кнопкой мыши на значке оператора и выберите из контекстного меню команду Properties (Свойства).
- Планы запросов можно также сохранить. Чтобы сохранить план запроса, щелкните в панели плана правой кнопкой мыши и выберите из контекстного меню команду Save Execution Plan As (Сохранить план выполнения как). План сохраняется в формате XML с расширением .sqlplan. Его можно открыть через SQL Server Management Studio. выбрав из меню File (Файл) команды Open, File (Открыть, Файл).
- То, что вы видели до сих пор - это предполагаемый план выполнения запроса, но можно просмотреть и действительный план выполнения. Действительный план выполнения аналогичен предполагаемому плану выполнения, но включает также действительные (не предполагаемые) значения количества строк, количества перемоток и т. д. Чтобы включить в запрос действительный план выполнения, нажмите (Ctrl+M) или выберите из меню Query (Запрос) команду Include Actual Execution Plan (Включить действительный план выполнения). Затем нажмите F5 и выполните запрос. Результаты запроса отображаются как обычно, но вы увидите также план выполнения, который показан на вкладке Execution Plan (План выполнения).