Языки описания онтологий. Основные синтаксические структуры: классы, отношения, аксиомы
RDF-литералы (или символьные константы)
RDF-литералы бывают двух видов: типизированные и нетипизированные.
Каждый литерал в RDF-графе содержит одну или две именованные компоненты.
- Все литералы имеют лексическую форму в виде строки символов Unicode.
- Простые литералы состоят из лексической формы и необязательной ссылки на язык (ru, en, :).
- Типизированные литералы состоят из лексической формы и URI-ссылки на тип данных, задаваемой в формате RDF URI.
Замечание. Язык литерала не нужно путать с идентификатором (языком) локали. Язык относится только к текстам, написанным на естественном языке. Все трудности, возникающие при представлении данных на конкретном компьютере (при определении локали), должны решаться конечным потребителем метаданных.
Сравнение литералов
Два литерала равны тогда и только тогда, когда выполняются все перечисленные ниже условия.
- Строки обеих лексических форм совпадают посимвольно.
- Либо оба литерала имеют теги языка, либо оба не имеют.
- Теги языка, если они имеются, совпадают.
- Либо оба литерала имеют URI типа данных, либо оба не имеют.
- При наличии URI типа данных эти URI совпадают посимвольно.
Определение значения типизированного литерала
Рассмотрим следующий пример. Пусть множество {T, F} - множество значений истинности в математической логике. В различных приложениях элементы этого множества могут представляться по-разному. В языках программирования {1, 0} ( 1 соответствует T, 0 соответствует F ), либо {true, false}, либо {истина, ложь}.
Фактически задается некоторое отображение множества значений истинности на множество чисел или строк символов. Теперь значениями логического типа (bool или boolean) становятся строковые значения или спецсимволы. Чтобы получить значения истинности, необходимо воспользоваться обратным отображением.
Таким же образом происходит получение значения типизированного RDF-литерала. За лексической формой стоит некоторое значение, которое определяется применением отображения. Это отображение определяется по URI типа данных и зависит от самого типа.
Контрольные вопросы
- Почему список высказываний о каком-либо ресурсе может быть представлен неупорядоченным множеством?
- Чем отличаются понятия "ресурс", "объект" и "документ" в контексте Web?
- Что такое RDF? Что представляет собой модель данных RDF и на чем она основана?
6.2. Языки представления онтологий: RDFS, OWL. Язык запросов SPARQL
Для того чтобы реализовывать различные онтологии, необходимо разработать языки их представления, имеющие достаточную выразительную мощность и позволяющие пользователю избежать "низкоуровневых" проблем. Ключевым моментом в проектировании онтологии является выбор соответствующего языка спецификации онтологий. Цель таких языков - дать возможность указывать дополнительную машинно-интерпретируемую семантику ресурсов, сделать машинное представление данных более похожим на положение вещей в реальном мире, существенно повысить выразительные возможности концептуального моделирования слабо структурированных Web-данных.
Распространение онтологического подхода к представлению знаний оказало содействие при создании разнообразных языков представления онтологии и инструментальных средств, предназначенных для их редактирования и анализа. Существуют традиционные языки спецификации онтологий: Ontolingua, CycL, языки, основанные на дескриптивных логиках (такие как LOOM), языки, основанные на фреймах (OKBC, OCML, F-Logic). Более поздние языки основаны на Web-стандартах (XOL, SHOE, UPML). Специально для обмена онтологиями через Web были созданы языки RDF, RDFS, DAML+OIL, OWL.
Языки, о которых пойдет речь в данном разделе, являются основными языками так называемой Семантической Сети (Semantic Web). О Semantic Web упоминалось ранее. Там же было отмечено, что на сегодняшний день наблюдается разрыв между способами представления метаданных (языками их определения) и теми интеллектуальными агентами, которые должны ими пользоваться. Языки описания метаданных и онтологий в Web развиты очень хорошо, языки запросов и языки описания правил доведены до стадии технологических стандартов в данной области. Однако узким местом всё еще являются механизмы взаимодействия агентов на основе онтологий.
Многие популярные редакторы онтологий, которые будут описаны ниже, используют в качестве основного формализма дескриптивную логику (DL) и предоставляют средства для создания OWL-онтологий.
RDFS
Каждый из элементов триплета определяется ссылкой на тип элемента и URI. Предикат (в контексте RDF его обычно называют свойством) может пониматься либо как атрибут, либо как бинарное отношение между двумя ресурсами. Но RDF сам по себе не предоставляет никаких механизмов ни для описания атрибутов ресурсов, ни для определения отношений между ними. Для этого предназначен язык RDFS (RDF Schema) - язык описания словарей для RDF. RDFS определяет классы, свойства и другие ресурсы.
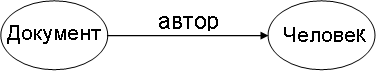
RDFS является семантическим расширением RDF. Он предоставляет механизмы для описания групп связанных ресурсов и отношений между этими ресурсами. Все определения RDFS выражены на RDF (поэтому RDF называется "самоописывающимся" языком). Новые термины, вводимые RDFS, такие как "домен", "диапазон" свойства, являются ресурсами RDF.
Система классов и свойств языка описания RDF-словарей похожа на систему типов объектно-ориентированных языков программирования, например, Java. Но RDF отличается от большинства таких систем тем, что здесь центральным аспектом является определение свойства, а не класса. Свойства в RDF определяются как пары (домен, диапазон). При этом домен представляет некоторое множество классов RDF, к которым данное свойство применимо, диапазон определяет допустимое множество ресурсов - значений свойства. Для сравнения: в Java определение класса имеет законченную форму (свойства класса выражаются в полях и методах класса). В RDF, напротив, описание класса всегда остается открытым (набор свойств класса определяется вне самого класса).
Пример. Определим свойство "автор" с доменом "Документ" и диапазоном "Человек" (рис. 6.2). В случае появления дополнительной информации о свойствах "Документа" нет необходимости изменять описание класса "Документ". Достаточно добавить новое свойство с соответствующим доменом.
Пример "a-la RDF":
Класс ("Документ");
Класс ("Человек");
Свойство ("Автор", "Документ", "Человек").
Пример "a-la Java":
Класс "Документ"
{
"Человек" "Автор"
}Можно заметить, что при изменении смысла свойств изменять придется именно их. При этом все классы, зависящие от изменяемых свойств, косвенно изменят свою семантику.
Основное преимущество такого подхода - в легкой расширяемости: добавление/удаление свойств интуитивно проще, чем управление множеством классов, обладающих каждый своим индивидуальным набором свойств (как в ООП). Фактически, любой может расширять описание существующих ресурсов (лозунг Web: "Кто угодно может сказать что угодно о чем угодно!").
Классы
Ресурсы могут объединяться в группы, называемые классами. Члены класса (здесь наиболее близкий термин - "экземпляры" или "объекты" ООП) называются экземплярами класса. Сами классы также являются ресурсами и идентифицируются ссылками RDF-URI. Чтобы указать, что ресурс является экземпляром класса, используется свойство rdf:type ("rdf" здесь применен как префикс пространства имен).
В RDF определение класса или свойства (т.н. интенсионал ) отделено от множества экземпляров класса и значений свойства (т.н. экстенсионала ). Так, два класса с одинаковыми экстенсионалами считаются различными, если они имеют разные наборы свойств (интенсионалы).
Экстенсионал и интенсионал
Рассмотрим множества
A = {0, 2, 4, 6, 8},
B = {x | x = 2k, k = 0..4, k - целое},
C - множество неотрицательных четных чисел, меньших 10.В этом примере множество А полностью описывается своим экстенсионалом, множества В и С описываются интенсионалами, т.е. с использованием характеристических свойств данного множества. Множества, имеющие бесконечное число элементов, могут быть описаны только своим интенсионалом. Однако при использовании интенсионала могут возникнуть парадоксы1Парадокс Рассела: пусть множество М - множество всех множеств, не содержащих себя. Содержит ли М само себя? Если содержит, то оно не удовлетворяет своему определению - интенсионалу; если М не содержит себя, то оно удовлетворяет определению и, следовательно, должно себя содержать.. Чтобы избежать их, в теории множеств вводятся дополнительные аксиомы. Примечательно, что RDF нарушает эти аксиомы. Классу RDF не запрещено быть экземпляром самого себя.
Группа ресурсов, являющихся классами, в RDFS описывается термином rdfs:Class.
На множестве классов определено отношение ПОДКЛАСС-НАДКЛАСС, описываемое RDFS-свойством rdfs:subClassOf. Семантика данного отношения состоит в том, что экстенсионал любого подкласса данного класса С целиком содержится (как множество) в экстенсионале самого класса С. Другими словами, если ресурс i является экземпляром класса С*, а класс С* является подклассом класса С, то i является экземпляром класса C.
Любой класс RDFS по определению является подклассом самого себя.
В спецификации по RDFS определены также списки, коллекции и контейнеры ресурсов, текстовые пометки и комментарии для создания удобных для чтения примечаний к ресурсам.